时序数据库(TSDB)-为万物互联插上一双翅膀
本文由 网易云 发布。
时序数据库(TSDB)是一种特定类型的数据库,主要用来存储时序数据。随着5G技术的不断成熟,物联网技术将会使得万物互联。物联网时代之前只有手机、电脑可以联网,以后所有设备都会联网,这些设备每时每刻都会吐出大量的按照时间组织的数据,需要存储下来进行查询、统计和分析。时序数据和普通的业务数据在各个方面都有很大的不同,本文将会试图带大家进入TSDB的世界。
TSDB应用场景:哪些场景会用到TSDB?
TSDB目前最大的应用场景是监控业务(哨兵),以哨兵为例,哨兵会在业务服务器上部署各种脚本客户端用来采集服务器指标数据(IO指标、CPU指标、带宽内存指标等等),业务相关数据(方法调用异常次数、响应延迟、JVM GC相关数据等等)、数据库相关数据(读取延迟、写入延迟等等),很显然,这些数据都是时间序列相关的,客户端采集之后会发送给哨兵服务器,哨兵服务器会将这些数据进行存储,并提供页面给用户进行查询。如下图所示,用户可以登录哨兵系统查看某台服务器的负载,负载曲线就是按照时间进行绘制的,带有明显的时序特征:
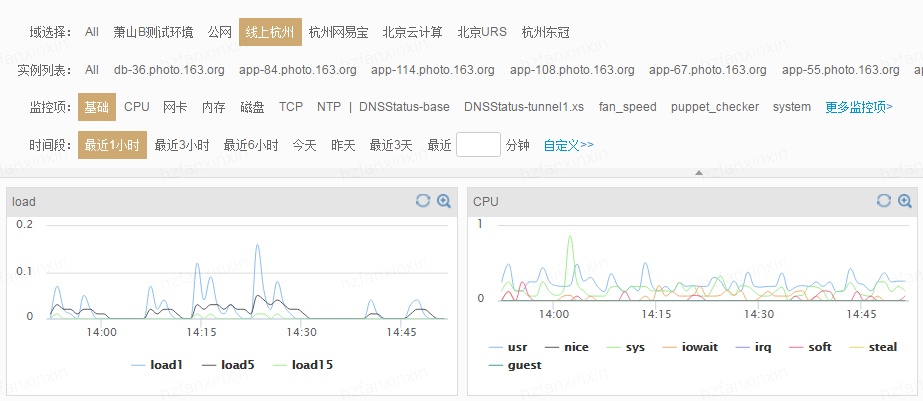
实际上,TSDB的潜力还没有爆发,至少在现在还没有。在可预知的未来3~5年,随着物联网以及工业4.0的到来,所有设备都会携带传感器并联网,传感器收集的时序数据将严重依赖TSDB的实时分析能力、存储能力以及查询统计能力。

上图是一个智慧工厂示意图,工厂中所有设备都会携带传感设备,这些传感设备会实时采集设备温度、压力等基本信息,并发送给服务器端进行实时分析、存储以及后期的查询统计。除此之外,比如现在比较流行的各种穿戴设备,以后都可以联网,穿戴设备上采集的心跳信息、血流信息、体感信息等等也都会实时传输给服务器进行实时分析、存储以及查询统计。
TSDB数据示例:什么是时序数据?
介绍了TSDB的主要应用场景,再来看看时序数据到底是什么样的数据。下图是一份典型的时序数据:
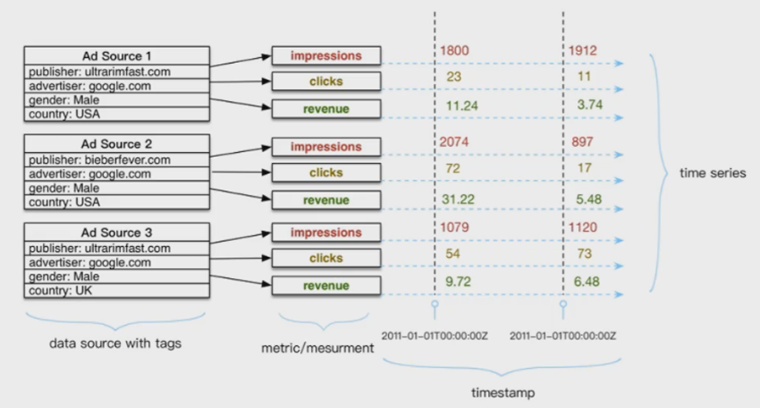
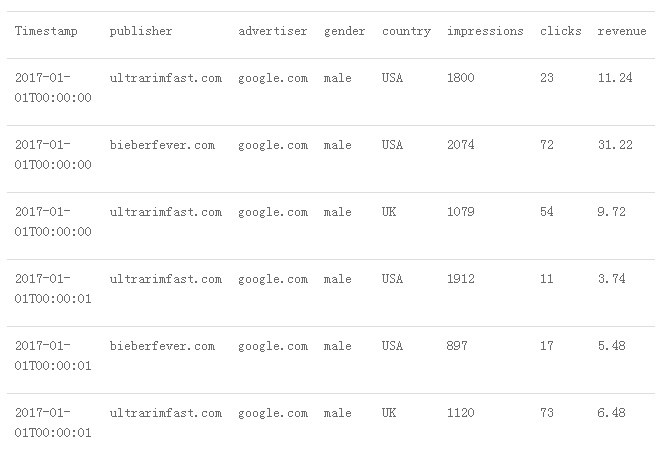
整个图表征广告业务实时行为数据,包括广告实时浏览量、实时点击量以及实时利润收入等。图中分了三个区域,表示时序数据由3个部分构成,分别为维度列、数值列以及时间列。维度列是最左边的部分,表征广告的基本信息,类似于物体标签,比如广告平台、广告主、广告面向对象以及广告面向国家等。数值列是中间的部分,表示采集的数值有广告浏览量(impressions)、点击量(clicks)以及利润(revenue)。时间列就是一系列的时间点信息。将上图翻译成表结构等价于:
TSDB基本特点:时序业务有哪些特点?
时序业务和普通业务在很多方面都有巨大的区别,归纳起来主要有如下几个方面:
- 持续产生海量数据,没有波峰波谷。举几个简单的例子,比如类似哨兵的监控系统,假如现在系统监控1w台服务器的各类指标,每台服务器每秒采集100种metrics,这样每秒钟将会有100w的TPS。再比如说,现在比较流行的运动手环,假如当前有100w人佩戴,每个手环一秒只采集3种metrcis(心跳、脉搏、步数),这样每秒钟也会产生300w的TPS。
- 数据都是插入操作,基本没有更新删除操作。时序业务产生的数据很少有更新删除的操作,基于这样的事实,在时序数据库架构设计上会有很大的简化。
- 近期数据关注度更高,未来会更关注流式处理这个环节,时间久远的数据极少被访问,甚至可以丢弃。这个很容易理解,哨兵系统我们通常最关心最近一小时的数据,最多看看最近3天的数据,很少去看3天以前的数据。随着流式计算的到来,时序数据在以后的发展中必然会更关注即时数据的价值,这部分数据的价值毫无疑问也是最大的。数据产生之后就可以根据某些规则进行报警是一个非常常见并重要的场景,报警时效性越高,对业务越有利。
- 数据存在多个维度的标签,往往需要多维度联合查询以及统计查询。时序数据另一个非常重要的功能是多维度聚合统计查询,比如业务需要统计最近一小时广告主google发布在USA地区的广告点击率和总收入分别是多少,这是一个典型的多维度聚合统计查询需求。这个需求通常对实效性要求不高,但对查询聚合性能有比较高的要求。
TSDB市场发展:现在都有哪些TSDB产品?
在最近的一年时间里,随着物联网技术的不断成熟,很多创业者都希望能借助这个风口得到更多创业机会。试想当年移动互联网刚兴起的时候,也是诞生了一批规模庞大的创业者,而现在,要想在移动互联网创业,难度已经非常之大,基本可以认为现在移动互联网创业都是在玩资本、拼干爹。而物联网这个市场的竞争力还是非常之小,非常纯洁,创业的机会也非常之多。看清楚这样的事实,很多厂商尤其是公有云提供商都不约而同的将目光投到这个领域,他们的目标就是笼络这些小的创业公司。下图是最近一年各个云厂商在TSDB的动作,搞个大动作是可以预见的了:

TSDB核心特性:TSDB关注的核心技术点在哪里?
说了这么多,是应该看看TSDB到底在技术层面关注哪些核心点了,基于时序业务的基本特点,总结起来TSDB需要关注的技术点主要有这么几个:
- 高吞吐量写入能力。这是针对时序业务持续产生海量数据这么一个特点量身定做的,当前要实现系统高吞吐量写入,必须要满足两个基本技术点要求:系统具有水平扩展性和单机LSM体系结构。系统具有水平扩展性很容易理解,单机肯定是扛不住的,系统必须是集群式的,而且要容易加节点扩展,说到底,就是扩容的时候对业务无感知,目前Hadoop生态系统基本上都可以做到这一点;而LSM体系结构是用来保证单台机器的高吞吐量写入,LSM结构下数据写入只需要写入内存以及追加写入日志,这样就不再需要随机将数据写入磁盘,HBase、Kudu以及Druid等对写入性能有要求的系统目前都采用的这种结构。
- 数据分级存储/TTL。这是针对时序数据冷热性质定制的技术特性。数据分级存储要求能够将最近小时级别的数据放到内存中,将最近天级别的数据放到SSD,更久远的数据放到更加廉价的HDD或者直接使用TTL过期淘汰掉。
- 高压缩率。提供高压缩率有两个方面的考虑,一方面是节省成本,这很容易理解,将1T数据压缩到100G就可以减少900G的硬盘开销,这对业务来说是有很大的诱惑的。另一个方面是压缩后的数据可以更容易保证存储到内存中,比如最近3小时的数据是1T,我现在只有100G的内存,如果不压缩,就会有900G的数据被迫放到硬盘上,这样的话查询开销会非常之大,而使用压缩会将这1T数据都放入内存,查询性能会非常之好。
- 多维度查询能力。时序数据通常会有多个维度的标签来刻画一条数据,就是上文中提到的维度列。如何根据随机几个维度进行高效查询就是必须要解决的一个问题,这个问题通常需要考虑位图索引或者倒排索引技术。
- 高效聚合能力。时序业务一个通用的需求是聚合统计报表查询,比如哨兵系统中需要查看最近一天某个接口出现异常的总次数,或者某个接口执行的最大耗时时间。这样的聚合实际上就是简单的count以及max,问题是如何能高效的在那么大的数据量的基础上将满足条件的原始数据查询出来并聚合,要知道统计的原始值可能因为时间比较久远而不在内存中哈,因此这可能是一个非常耗时的操作。目前业界比较成熟的方案是使用预聚合,就是在数据写进来的时候就完成基本的聚合操作。
- 未来技术点:异常实时检测、未来预测等等。
TSDB总结
TSDB将是未来一个非常具有市场性、挑战性的数据库,现在虽然已经有这样那样的服务,但大多都有这样那样的问题,现在很难谈得上成熟。为了在物联网时代、工业4.0时代中占有一定地位,TSDB是必须要拓展的技术。本文从时序场景、时序业务特点、TSDB市场以及TSDB核心技术点这几个方面对TSDB进行了介绍,希望看官能基本了解TSDB。后续笔者将会推出针对TSDB的系列专题文章,深入分析TSDB本身所要面对的各种技术问题以及解决方案。
本文为网易工程师心血之作,未经许可请勿转载!
作者:范欣欣
原文链接:时序数据库-为万物互联插上一双翅膀(本文有删节)
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号