SparkSQL on K8s 在网易传媒的落地实践
作者:鲁成祥 易顺
随着云原生技术的发展和成熟,大数据基础设施积极拥抱云原生是业内发展的一大趋势。网易传媒在 2021 年成功将 SparkSQL 部署到了 K8s 集群,并实现与部分在线业务的混合部署,到目前已经稳定运行了一年多。期间传媒联合杭研 Spark 内核团队和云计算团队对出现的问题进行了持续的改进,本文将对这些落地优化实践进行初步的梳理总结,希望能给大家带来一些有用的参考。目前,传媒大数据中心的大部分 SparkSQL 任务都已经迁移到了 K8s 集群,但仍有一部分算力保留在 Yarn 集群,作业调度主要依托于有数平台,SparkSQL 任务的提交方式以 Kyuubi [1] 为主,Spark 版本主要基于 3.1.2 进行演进,下图简单描述了我们当前 Spark 离线计算的基本架构: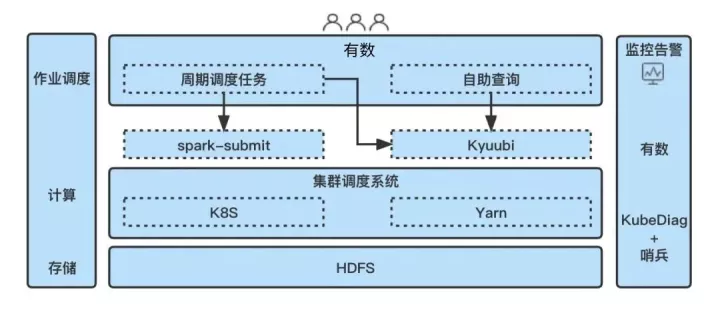
以下将分别从 on K8s 落地收益、任务迁移方案、集群和任务运行监控、任务资源占用治理、任务调度优化等几个方面逐渐展开介绍。
SparkSQL 迁移到 K8s 的收益
传媒大数据将 SparkSQL 迁移到 K8s 主要基于如下考量:
- 可以将计算和存储进行解耦,即存算分离。在存储和计算耦合的架构中,由于各业务场景对存储和计算的需求不平衡,绑定两者同步进行伸缩,会出现其中一种资源浪费的情况;将计算和存储解耦后则可以根据需要分别进行弹性伸缩,系统在负载均衡调度方面可以更加灵活。
- 统一算力资源池实现统筹调度,SparkSQL 可以作为离线业务与其它在线业务进行混混部达到峰谷互补的效果,有助于提升服务器资源利用率和管理运维效率,节约总成本。
任务由 Yarn 迁移到 K8S 的方案
迁移方面,我们已提前将大部分任务由HiveSQL 迁移到了 SparkSQL 引擎[2] ,而 SparkSQL 从 Yarn 集群上切换到 K8S 集群上对用户来说基本上是无感知的。不过,迁移初期为了保证未知风险尽量可控,我们采取了如下措施:
- 先迁移非核心的下游任务来踩坑,逐步扩大规模再推进到上游任务。
- 先迁移自定义脚本类型任务,得益于对 Kyuubi 的使用,只需要少量代码就可以方便地将失败任务调度至 Yarn 集群进行重试。
这样我们在迁移初期尽量减少了对需要保障的核心 SLA 任务链路的影响。
任务在 K8s 上的运行监控
任务迁移到 K8s 之后,在遇到问题进行排查时,用户都迫切希望能尽快看到作业的运行情况从而快速进行问题诊断和作业优化。传统的 SparkSQL on Yarn 场景,我们有 Yarn 的 web 页面作为入口来查看队列资源占用和任务运行状态,但在 K8s 环境下并没有一个类似的统一入口。而 Spark History Server 上的任务统计列表因为需要等待任务运行日志上传至 HDFS 后才能解析展示,相对要滞后许多,这导致了在迁移初期我们对集群和任务的运行情况基本处于两眼一抹黑的状态。为了解决这个问题,我们首先设置所有任务均使用 client 模式提交 SparkSQL,让 Spark Driver 在调度机本地运行,这样一来,便只需要在几台任务调度机上部署监控程序,通过 Spark Driver 本地的 Spark http 接口获取当前任务运行信息即可。这种方式虽然不是很符合所有组件都跑在容器中的云原生理念,但是人力成本相对较低,在前期简化了我们的监控告警工作,将来待方案进一步完善后再切换到 cluster 运行模式。另外,随着优化工作的推进,我们跟杭研 Spark 内核组配合搭建了 Hygieia 任务运行指标监控服务,跟部门运维和杭研云计算团队增加了调度资源相关的监控,对监控需求进行了进一步完善。以下简单列举了日常看得比较多的几个监控报表:
- 任务实时运行列表:实时监控集群上当前的任务列表,可以直接跳转相应的 Spark UI 来查看实时运行情况。
- 任务资源分配监控:监控 CPU、内存等资源分配量的变化,可以按任务或用户维度进行堆叠,主要用于监控集群的整体运行情况,比如是否有异常任务或用户抢占大量资源、或者资源分配速度不正常等等。
- 任务运行状态统计:监控集群上运行中和 pending 的任务数或 pod 数,可以直观地反映集群资源的竞争程度和 K8s 的调度负载。
- 集群运行指标监控:主要通过哨兵提供的监控页面查看,具体各业务的资源容量和实际使用量情况主要通过云计算团队提供的 Grafana 监控查看。
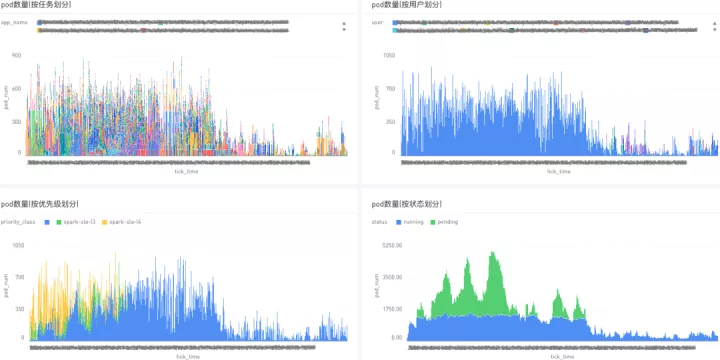
部分监控报表实际使用中,通过上述监控,基本能较全面地查看集群和 SparkSQL 任务的运行状态,有助于快速定位问题。
任务资源占用治理
任务在 K8S 上平稳运行之后,大家的关注点逐渐转移到性能问题上来,尤其是集群的资源使用率和基线任务的产出时间等,这方面我们针对 K8S 集群的特点陆续落地了一系列优化策略,以下分别从 CPU、内存、磁盘等资源角度进行介绍。
1. CPU
为尽可能地提高集群的承载容量,最大化能并发运行的 executor pod 数量,我们根据集群和任务的统计情况对 CPU 做了一定比例的超售。经过对比 CPU 申请量和实际使用量的整体比值,最终统一将任务的 spark.kubernetes.executor.request.cores 参数配置为 1,而 spark.kubernetes.executor.limit.cores 不做限制,同时将 spark.executor.cores 配置为 4,即 excutor 按 1 核的申请量跑 4 并发的 task,以此最大限度地压榨集群的 CPU 算力。CPU 超售会加重集群负载不均衡的问题,造成部分节点负载过高,但得益于云计算团队开发的 Zeus 混部调度器,可以动态更新资源隔离配置,避免对在线业务产生过多干扰 [3]。
2. 内存
由于之前 Yarn 集群的内存资源较充足,业务上对各任务内存申请的审批也相对宽松,导致任务内存申请方面普遍存在 “虚胖” 的问题,从而导致在迁移到 K8s 集群后内存成为瓶颈,集群并发上不去出现算力浪费情况。与 CPU 相比,内存作为一种不可压缩资源相对紧缺,且不同任务所需的内存大小不一,不能对任务内存申请执行一刀切的策略。如何安全且高效地降低 SparkSQL 任务的内存分配,是一个关键的问题。为了给每个任务评估出一个相对合理的内存申请值,我们首先基于前文提到的 Spark 监控插件 Hygieia,实现了对 SparkSQL 任务运行指标的实时采集。在积累了一段时间的样本数据后,我们开始根据每个任务的历史统计数据对内存申请进行例行化调整,调整策略主要如下:
- 取任务近一段时间所有实例 executor 堆内和堆外内存使用量之和的最大值,按 128MB 为单位向上取整作为内存申请建议值进行调整。另外,为了安全考虑设置了调整下限。
- 对调整后的任务进行一段时间的健康监测,包括任务运行时长和 GC 吞吐量等指标。当任务运行时长出现延长或者 GC 吞吐量下降时,则需要回调内存或人工介入排查。一个简化版的模型是,当任务内存被削减后一周内的 GC 吞吐量中位位数若低于 95%,每低 1% 则增加 512MB 内存,直至恢复到调整前。
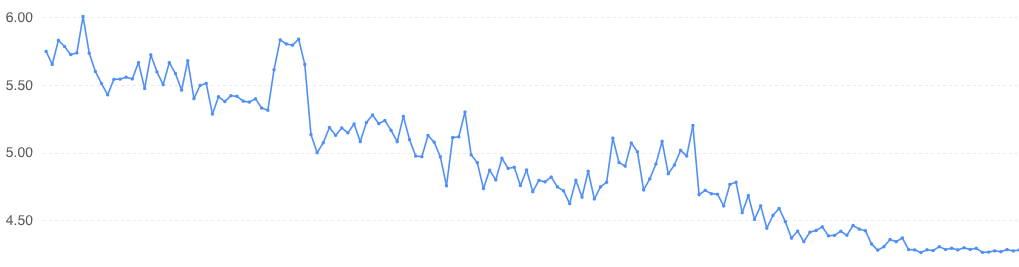
具体执行上,我们通过猛犸调度平台的开放 API 做到了每天例行自动化调整。另外,为了避免任务被频繁调整无法评估效果,还针对每个任务设置了调整冷却期等。截止到当前,调整策略对业务而言基本上做到了透明无感知和 0 事故。下图展示了自调整策略执行以来内存分配量 95 分位与 CPU 实际使用量 95 分位比值的变化曲线,当前比值已降至接近 4:1 的合理水平,集群 0-7 点的 CPU 利用率保持在 80+%,且 GC 吞吐量保持在 95+%:
3. 磁盘
虽然 “内存计算” 是 Spark 的主要特性之一,但在实际场景中往往由于任务 shuffle 数据量大,导致对磁盘容量和 IO 速度要求也较高。目前传媒使用的还是 ESS 方案,尚未切换到 RSS 方案 [4],且传媒 K8s 集群挂载的数据盘容量有限,如果一些异常任务发生倾斜,极易引发个别节点磁盘被写满的风险,导致任务失败和重试。为了解决这些问题,主要措施如下:
- 数据盘统一使用 SSD:迁移之初,K8s 集群使用了部分云盘,而 Spark 离线计算任务高峰期突发数据流量非常大,导致云盘读写出现明显延迟,集群 CPU 的 io_wait 时间占比很高,任务大量时间耗费在等 IO 上。全部改为使用 SSD 后,运行速度得到明显提升。
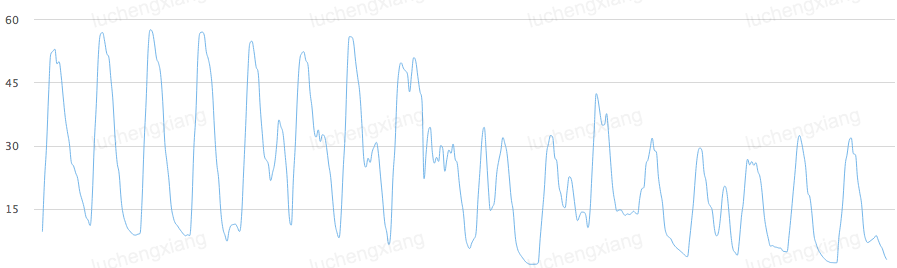
- 使用 zstd 压缩 shuffle 数据:zstd 压缩算法性能优秀,在压缩率和耗时上都有卓越的表现。相较于 shuffle 默认的压缩算法 lz4,zstd level1 压缩级别在任务性能表现上基本持平,但压缩率提升了近一倍。经实践,切换到 zstd 压缩可显著降低 shuffle 写盘的数据量,有效缓解磁盘容量上和 IO 上的压力,从而提升容错上限。下图展示了切换 zstd 压缩算法前后磁盘空间使用率的变化情况:
- 大 shuffle 任务调度至 Yarn:由于传媒当前还保留有一部分 Yarn 算力,将 shuffle 量较大的任务调度至 Yarn 可以有效减轻 K8S shuffle 服务的压力,做到物尽其用。
任务调度优化传媒 SparkSQL 任务主要以分钟级为主,且基于 3.1.2 版本开启了动态资源分配机制,运行时会根据需求动态申请和释放 executor,实际使用中对集群的调度吞吐能力有一定的性能要求,这本身对以调度长时服务起家的 K8s 提出了不小的挑战。我们遇到的问题和应对策略主要如下:
1. 调度性能瓶颈问题优化
上文提到 SparkSQL 任务是作为离线业务与其它在线业务进行混部的,且初期共用一个线性调度器,而由于离线任务的优先级都要低于在线业务,导致出现了高峰期时集群有资源但是迟迟调度不上去的现象。通过与杭研 Spark 内核团队配合,我们对每个任务所能并发申请的 pod 数进行了限制,一定程度上减少了 excutor pod 的频繁申请和释放。通过与杭研云计算团队配合,我们为 SparkSQL 独立出了一个专用的调度器,将 SparkSQL 的调度与其它业务的调度负载隔离开,从而消除了 SparkSQL 在调度性能上的瓶颈。
2. 针对调度倾斜开启反亲和调度
如果某个任务的 excutor pod 集中在少数几个节点上,而这个任务的 shuffle 或计算又比较重,比较容易导致节点磁盘写满或 CPU 负载高,实际场景中这种情况并不少见。为了应对这个问题,我们在 executor pod 的调度上开启了反亲和特性,即同一个任务的 pod 尽可能分散到不同的节点上,也取得了比较不错的效果。
3. 开启优先级调度保障核心任务链路
随着迁移到 K8S 集群上任务规模的扩大,资源竞争逐渐加剧,高峰期频繁出现任务长时间 pending 的情况,尤其是在出现重大新闻事件时需要把集群资源倾斜给线上关键业务时。这个时候给不同 SLA 级别的任务设置不同资源分配优先级的需求格外强烈起来。通过与杭研 Spark 内核团队配合,我们为任务指定了不同的 PriorityClass 来对调度优先级进行区分。下图分别是关闭和开启优先级调度时的 SLA 任务运行情况,其中每个颜色代表一个任务所占用的 pod 数。可以看到,开启优先级调度时,SLA 任务在高峰期时的资源分配得到了优先保障,pod 数的峰值提高 20+%,任务 “身材” 明显 “瘦” 下来,拖尾现象得到缓解。
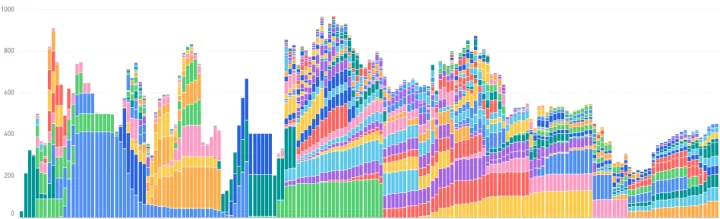
关闭优先级调度时
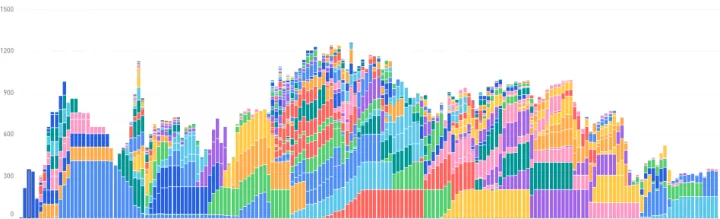
开启优先级调度时优先级调度的落地,为重大新闻事件时的高优数据保障工作提供了一个托底的机制。
总结与展望
传媒 SparkSQL on K8S 稳定运行一年来,随着优化方案的落地,集群的规模相较于初期已经缩容了 30+%,但基线产出仍保持了稳定,甚至有所提升。这与部门内和杭研相关团队的有力支持是分不开的,在此一并表示感谢!后续工作将围绕以下几个方面展开:
1. 继续扩大 SparkSQL on K8s 的规模
后续传媒将继续扩大 SparkSQL on K8s 的规模,统一算力资源池,扩大规模效应。当前大数据技术中心正在协助推荐业务开展迁移验证,也已经取得了不错的测试效果。
2. 探索与 Flink on K8s 混部
当前传媒也正在落地 Flink on K8s 的云原生方案,并探索与 SparkSQL on K8s 做混部。相较于后台线上服务,Flink 实时计算的流量特征更加明显,负载波动更能与 SparkSQL on K8s 互补,且同属于大数据业务便于统筹调度资源。
3. 探索存储的云原生方案
存算分离后,目前传媒大数据的存储资源仍全部集中在 HDFS 集群上,由于与 Yarn 计算资源的绑定,而导致缺乏相应的弹性伸缩能力。当前对象存储和基于对象存储的 Hadoop 兼容文件系统发展迅速,传媒也正在展开对该模式的探索,以期实现存储资源池的统一。传媒当前 SparkSQL on K8s 使用的 ESS shuffle 方案依赖于计算节点上的磁盘来存储临时数据,还不算完整云原生意义上的存算分离,后续将开始调研并落地 RSS 相关的方案。
引用:
- Apache Kyuubi (Incubating)
- Hive SQL 迁移 Spark SQL 在网易传媒的实践
- 降本增效黑科技 | 基于 Kubernetes 的在 / 离线业务混部
- Apache Uniffle (Incubating)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号