【Java虚拟机4】Java内存模型(硬件层面的并发优化基础知识--缓存一致性问题)
前言
今天学习了Java内存模型第一课的视频,讲了硬件层面的知识,还是和大学时一样,醍醐灌顶。老师讲得太好了。
Java内存模型,感觉以前学得比较抽象。很繁杂,抽象。
这次试着系统一点跟着2个老师学习一下。
学习Java内存模型目的:
1.高并发情况下,java内存模型是怎么提供支持的?
2.一个对象创建后,在内存中的布局?
为什么在聊JVM内存模型、happens-before、八大原子指令之前需要学习硬件层面的并发优化基础知识?
任何语言都是靠CPU执行它的指令来运行的。所以java虚拟机只是在CPU的指令执行上层包装的一些东西(虽然也很高深精妙),再所以先学基于硬件层面的并发优化的基础知识,后面学JVM的内存模型就容易多了。
存储器的层次结构
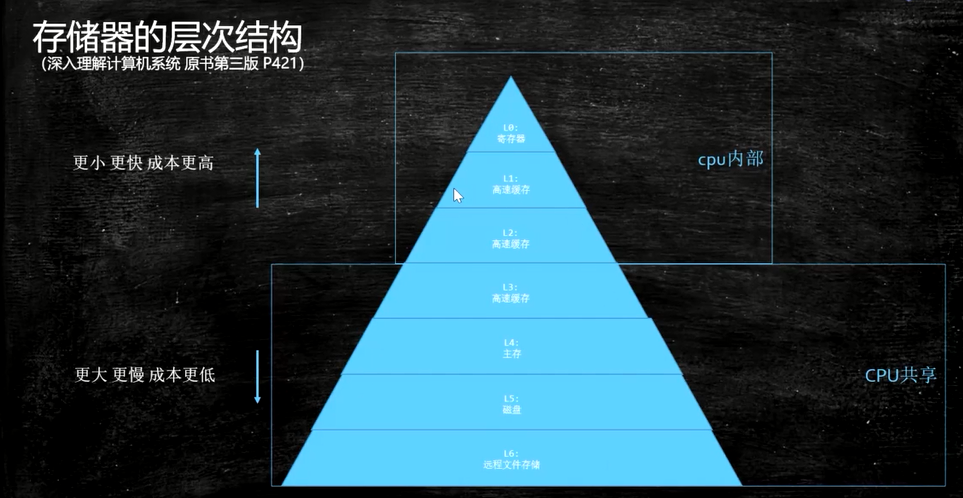
对于现代cpu而言,性能瓶颈则是对于内存的访问。cpu的速度往往都比主存(即内存)的速度高至少两个数量级。
CPU读数的时候,会先从金字塔从上往下找,找到就依次放到缓存。
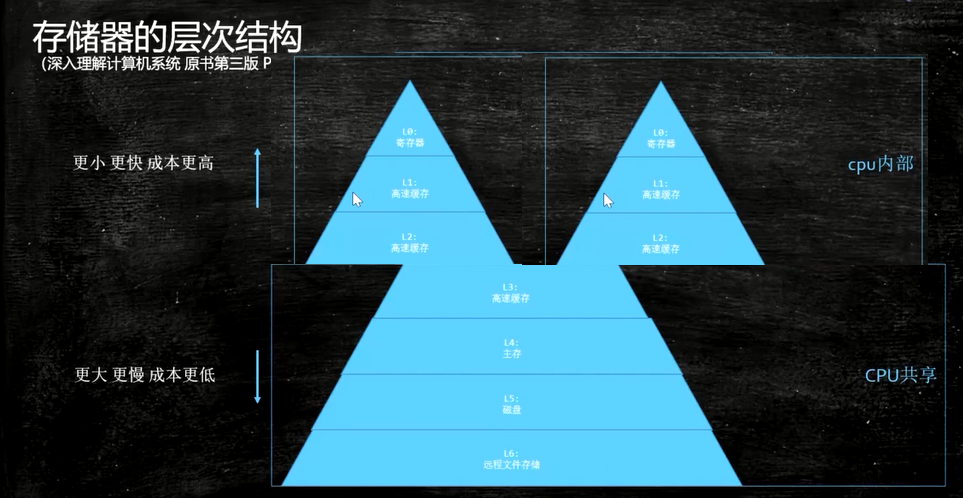
当多核CPU的时候,前三层的缓存和寄存器就是多个。
Cache一致性(Cache Coherence)问题
这里的Cache指的是CPU内部的两级缓存
一致性问题的产生-信息不对称导致的问题
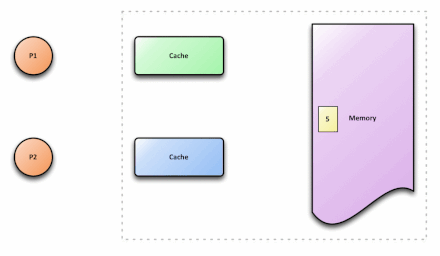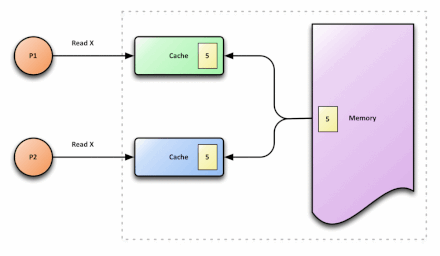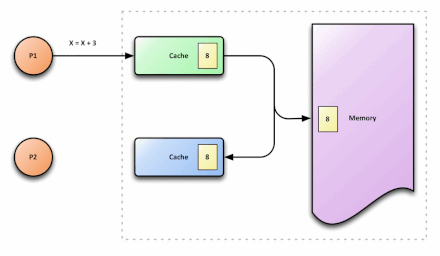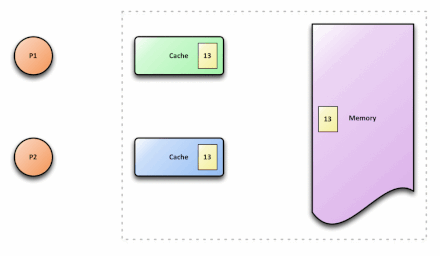
在多核处理器中,内存中有一个数据x,值为3,被缓存到CPU0和CPU1中,如果CPU0将x修改为5,而CPU1不知道x被修改,还在使用旧值,就会导致程序出错,这就是cache的不一致。
Cache一致性的底层操作为了保证cache的一致性,处理器提供了两个保证cache一致性的底层操作:Writeinvalidate和Write update。
- Write invalidate(置无效):当一个内核修改了一份数据,其他内核上如果有这份数据的复制,就置成无效。
- Write update(写更新):当一个内核修改了一份数据,其他地方如果有这份数据的复制,就都更新到最新值。
参考计算机体系结构(第五版)-复习-MESI&MOESI协议
参考CPU Cache一致性问题
![]()
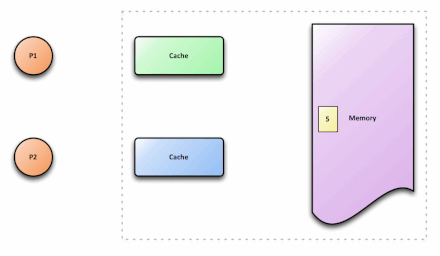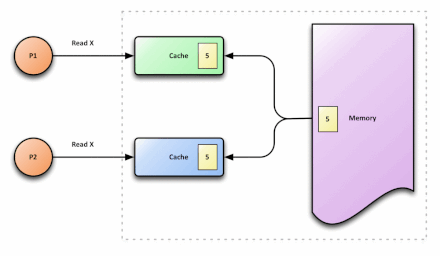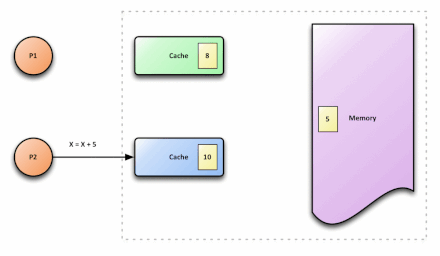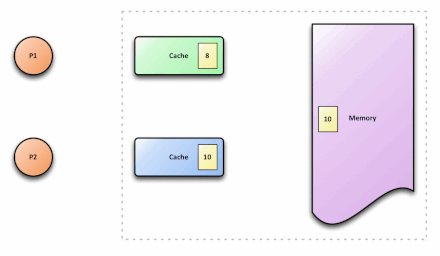
解决方案
1.总线锁
顾名思义,总线锁就是用来锁住总线的,我们可以通过上图来了解总线在这个场景中所处的位置。当一个CPU核执行一个线程去访问数据做操作的时候,它会向总线上发送一个LOCK信号,此时其他的线程想要去请求主内存的时候,就会被阻塞,这样该处理器核心就可以独享这个共享内存。可以理解为,总线锁通过把内存和CPU之间的通信锁住,把并行化的操作变成了串行,这会导致很严重的性能问题,这与我们需要多核多线程并行操作来提高程序的效率的目的大相径庭。
所以,随着技术的发展,就出现了缓存锁。
2.缓存锁
简单的说,如果某个内存区域数据,已经同时被两个或以上处理器核缓存,缓存锁就会通过缓存一致性机制阻止对其修改,以此来保证操作的原子性,当其他处理器核回写已经被锁定的缓存行的数据时会导致该缓存行无效。
就是说当某块CPU核对缓存中的数据进行操作了之后,就通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取。
处理器上有一套完整的协议,来保证缓存的一致性,比较经典的应该就是MESI协议了,其实现方法是在CPU缓存中保存一个标记位,以此来标记四种状态。另外,每个Core的Cache控制器不仅知道自己的读写操作,也监听其它Cache的读写操作,就是嗅探(snooping)协议。
M:被修改的。处于这一状态的数据,只在本CPU核中有缓存数据,而其他核中没有。同时其状态相对于内存中的值来说,是已经被修改的,只是没有更新到内存中。
E:独占的。处于这一状态的数据,只有在本CPU中有缓存,且其数据没有修改,即与内存中一致。
S:共享的。处于这一状态的数据在多个CPU中都有缓存,且与内存一致。
I:无效的。本CPU中的这份缓存已经无效。
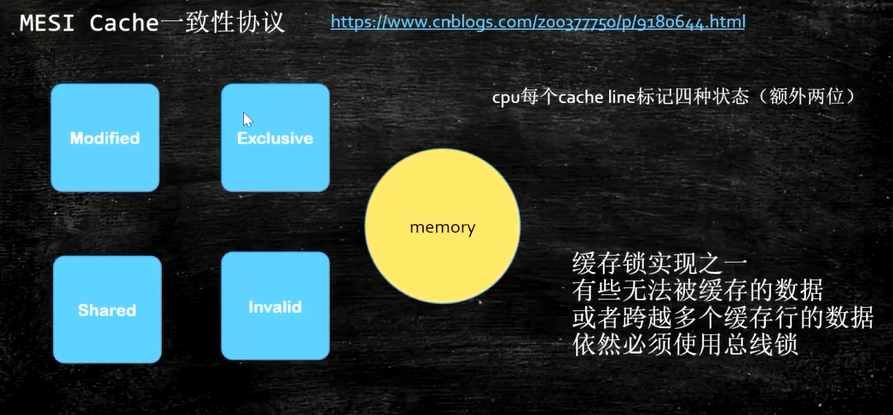
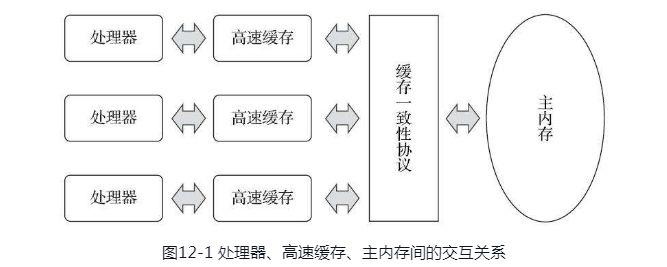
CPU的读取会遵循几个原则(其实就是上面说的嗅探)
一个处于M状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回CPU。(按我个人通俗一点说理解就是,我把内存中这个拼图玩具(数据)复制一份拿来玩,但是我要时刻注意有没有人要玩这个玩具,如果有人要玩,那我就要告诉他,这拼图已经被我拼成这样子了,你从这个进度开始拼吧。)
一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到,则必须把其缓存行状态设置为S。
当CPU需要读取数据时,如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S,如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为M。
所以如果一个变量在某段时间只被一个线程频繁地修改,那么使用其内部缓存就完全可以了,并不需要涉及到总线事务。如果内存一会被这个CPU独占,一会被那个CPU 独占,这时才会不断产生RFO指令影响到并发性能。这其实是跟CPU协调机制有关,如果在CPU间调度不合理,会形成RFO指令的开销比任务开销还要大,喧宾夺主,我们反而不能提高效率。顺带一句题外话,之前听过一句话,程序玩到最后都是性能和安全的博弈,深以为然。
并非所有情况都会使用缓存一致性的,如被操作的数据不能被缓存在CPU内部或操作数据跨越多个缓存行(状态无法标识),则处理器会调用总线锁定;另外当CPU不支持缓存锁定时,自然也只能用总线锁定了,比如说奔腾486以及更老的CPU。
现代CPU一般采用总线锁+缓存锁实现
因为有一些数据无法被缓存,或者无法缓存到同一个缓存行里。想要解决一致性问题就必须用总线锁。
解决后的效果
缓存行与伪共享
概念
在计算机系统中,内存是以【缓存行】为单位存储的,一个缓存行存储的字节是2的倍数。不同机器上,缓存行大小也不一样,通常来说为64字节。
伪共享是指:在多个线程同时读写同一个【缓存行】上的不同数据时,尽管这些变量之间没有任何关系,但是在多线程之间仍然需要同步,从而导致性能下降。在多核处理器中,伪共享是影响性能的主要因素之一,通常称之为:“性能杀手”。
说明
线程1在CPU1上读写变量X,同时线程2上读写变量Y,但是巧合的是变量X,Y在同一个缓存行上,那边线程1,2就要互相竞争获取该缓存行的读写权限,才可以进行读写。
假如线程1在内核1上获取了缓存行的读写权限,进行了操作,就会导致其他内核中的x变量和y变量同时失效,那么线程2就必须刷新它的缓存后才能在内核2上获取缓存行的读写权限。
这就导致了这个缓存行在不同的线程之间多次通过L3缓存(共享的,见本文第一张图)进行交换最新复制的数据,极大的影响了CPU性能,如果CPU不在同一个槽上,性能更糟糕。
缓存行对齐在开源框架Disruptor的应用
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。
//Disruptor框架部分源码
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
缓存行对齐(Cache Line Padding)Java示例
例1:不同变量位于相同缓存行示例
public class CacheLinePadding1 {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
例2:不同变量位于不同缓存行示例
public class CacheLinePadding2 {
private static class Padding {
//默认创建7个long类型的数据,一个long占8个字节
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
//实际操作变量占一个缓存行的最后一个字节
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}
执行结果:例2(操作变量位于不同缓存行)比例1性能高1倍多。
参考汇总
计算机体系结构(第五版)-复习-MESI&MOESI协议
CPU Cache一致性问题
MESI--CPU缓存一致性协议
JMM基础(总线锁、缓存锁、MESI缓存一致性协议、CPU 层面的内存屏障)
剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
Java中的伪共享以及应对方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号