
北航面向对象Round Three
写在前面
本单元我们主要的任务就是JML实践和理论学习。JML是一种形式化的、面向Java的行为接口语言。在工程实现过程中,架构师仅需根据所需完成的任务,抽象每个方法的功能及作用,而不必注重方法的实现细节。这样,程序员就可以根据每个方法的具体功能进行代码实现,并且方便程序员依据每个方法的功能对其做单元测试。这大大提高了代码的可维护性和程序员之间的合作效率。
1 JML语言
1.1 基本JML语法
JML以注释的方式对规格抽象。同样地,JML也有两种注释方式:行注释和块注释。JML使用@与代码中普通的注释分隔开。两种注释方式的基本结构如下
//@ 这是行注释
/*@ 这是
@ 块注释
@*/
同时,JML采用\作为转义字符,常见使用转义字符转义的单词有\result、\old、\exists、\forall、\min、\max、\nothing、\everything等。根据其单词的中文含义,我们可以大致理解这些关键字的含义。
1.1 方法规格抽象
JML的方法规格抽象主要有两类,一是前置条件,它对应方法在执行前对输入的要求;二是后置条件,它对应执行后方法返回结果应该满足的约束。下面会分别讲解JML在这种方法规格抽象中的语法。
1.1.1 前置条件
前置条件通过requires子句实现,requires的意思是确保调用者在调用时,requires后面跟的条件永远为真,实现时不必考虑requires后的条件为假的情况。这使得代码实现人员能够确定该代码能在何时被调用,而不用浪费精力具体理解该段代码在以后的具体使用场景。
1.1.2 后置条件
后置条件通过ensures子句实现,ensures的意思是确保程序在离开本方法时,数据流的状态和返回值的内容。即ensures确定了代码的作用效果。代码实现人员在实现代码时只需要满足ensures的要求,而不必关心代码的具体实现场景。代码规格中往往会有多个ensures子句,他们具有同等的作用效果,在程序离开此方法时都需要满足。
1.1.3 副作用范围限定
副作用范围限定通过assignable和modifiable实现 ,副作用范围限定规定了此方法所能修改的对象,进而体现出该方法对之后方法执行的影响。当然,副作用范围限定也可以使用\nothing,这代表此方法不会修改任何对象。或者也可以指明变量,表明在调用此方法后,这个变量的值会发生改变。
1.2 数据规格抽象
1.2.1不变式
不变式通过invariant实现,不变式是任何时刻对象实例数据所必须满足的要求。即在可见状态下的取值满足一定的条件(一般为调用方法前和调用方法后)。一旦不满足不变式的要求,对象任何方法的执行结果都可能无效,即便满足方法本身的后置条件。
1.2.2约束
约束通过constraint实现,它是任何时刻修改对象实例数据所必须满足的要求。即每次修改数据都要按照约束来实现。
1.3LSP原则
LSP(Liskov Substitution Principle)即里氏代换原则。它的核心思想是在所有使用父类的地方,必须能透明地使用其子类的对象。即在代码中,如果将一个父类对象替换成它的子类对象,程序将不会产生任何错误和异常。
为了遵循这个原则,我们在书写JML语言的时候要注意:子类重写重写父类方法时,子类不能与父类的方法规格相冲突;子类新增和扩展的数据规格不能与父类数据规格相冲突。所以如果子类是新增任务,则仅需对子类进行repOK检查,因为父类的repOk检查已经在之前完成了,并且满足LSP原则的子类功能扩展,不会影响父类repOK正确性。
1.5JML应用工具链
JML的工具有很多,最常用的还是openjml,可以对JML进行语法检查等。
还有常用的JMLUnitNG,可以根据JML语言自动生成测试文件。
此外,JML还有官方网站的支持http://www.eecs.ucf.edu/~leavens/JML/index.shtml
2 SMT solver部署(略)
3 部署JMLUnit
使用jmlunitng以及openjml。采用如下代码,跑JML测试
public class TestAdd {
/*@
@ public normal_behaviour
@ ensures \result == a + b;
*/
public static int add(int a, int b) {
return a + b;
}
public static void main(String[] args) {
add(9527, 123);
}
}
结果如下,从图片上看,主要是整型的溢出问题
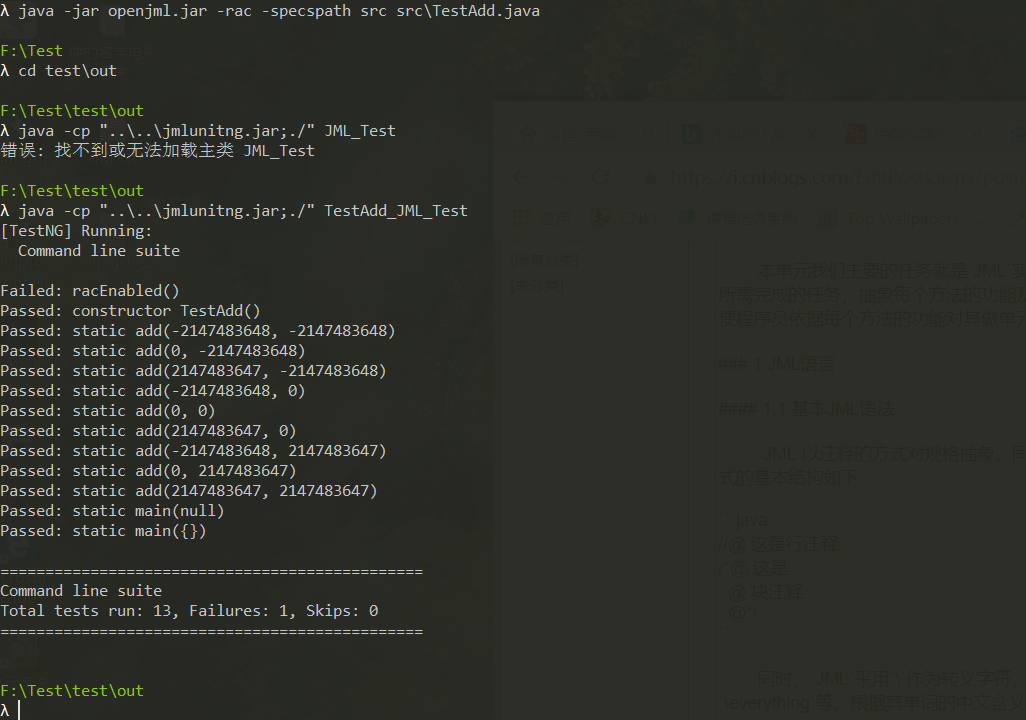
4 作业分析及BUG分析
本次作业同样是采用迭代增量的方式,但与之前两次感觉不同的是,后续的作业完全可以继承之前的作业,这是因为每次作业的接口都有继承关系。这也让我深刻体验到了工程中每次任务迭代的感觉。但是本轮作业遭到了严重的滑铁卢,从一个no bug man变成了浑身是bug的程序猿。虽然高工没有bug修复环节,但是我还是认真分析了几次作业的bug,进行了bug修复(不修复后面没法写).
4.1 第一次作业
第一次作业是根据给出的jml规格写出比较简单的代码。测试结果也正确,虽然看到了本次作业有明确的时间限制,但是感觉本次作业的主题是jml规格,不是一个算法作业,就没再仔细深究。说实话,是自己轻敌了,亦或者说是自己不认真,没有认真阅读指导书,指导书明确指出了数据的基本限制——某些指令条数之和不超过300,并且指令的总上限为3000条。这就意味着某些指令会大量出现,而这些指令的时间复杂度,就决定了最后的程序运行时间。
果不其然,在测试中,最后5个点全部TLE。这是因为我的getDistinctNodeCount函数是每次查询都会重新计算的。而不是在构图时提前计算好,保存最终的结果。这样使得每次调用getDistinctNodeCount函数,我的时间复杂度都是O(n)的,而别人都是O(1)的。在大量数据下,TLE也不足为奇。在认识到这个问题后,我修复了我第一次作业的BUG。因为第一次作业大家都比较相似,所以在此就不贴第一次作业的UML类图。
4.2 第二次作业
第二次作业是在第一次作业上的基础进行增量扩展,有了上次作业的教训,我这次认真阅读了指导书。指导书明确给出,线性指令的总数不超过500条。并且,构图指令总数不会超过20条。那么,剩下没有提到的指令肯定是经常使用的指令了,这包括两个节点之间最短路径的查询。
代码重构
因为这次作业的功能是上次作业的扩增,但是与上次作业的内容并不矛盾,我就直接将上次作业的代码复制过来。第二次作业直接在第一次作业的基础上coding。
架构设计
第二次作业增加了两点之间最短路径的查询,这个查询理所应当的想到的是dijkstra。但是本次作业有特殊性,每条边的边权都为1。这样就可以使用广度优先搜索来找到两点之间的最短路径。为了降低本次作业的时间复杂度,我采用了“懒查询”的方式——并没有选择每次构图时算出所有点之间的最短距离,而是在查询的时候计算两点之间最短距离然后保存。下次查询时就会检查之前有没有缓存,有缓存直接访问缓存的内容。此外,为了增加本次作业的可扩展性,我单独开了一个图算法的类,进行相应的图计算。本次作业的UML类图如下:

在构图的类中添加了缓存表route,在外部查询两点最短路时,优先查询route表,查不到再跑BFS。缓存表在每次执行构图指令后都会flush,这就保证了查询数据的正确性。
bug分析
本次作业,可以说时我OO作业中输的最惨的一次。因为上次的作业出现了超时现象,所以修复了上次作业的bug,并对上次作业进行了一些优化,但是错就错在了优化上。我重写了MyPath中的迭代器,使之返回Path集合中的元素。这就导致迭代器访问的元素顺序和数量与路径中的节点顺序和数量不同。在使用指令 PATH_GET_BY_ID时,就返回了错误的结果。第二次作业的本次测试环节我没有测试第一单元的指令,这导致我虽然过了中测,但是强测一分没有。这是血的教训,即修改之前的代码后,一定要对修改的之前代码部分作完整的测试。在我修改了迭代器方法后,强测中的点就全部通过了。
4.3第三次作业
两次滑铁卢,让我第三次作业不敢怠慢。其实在第二次作业出结果之前我就通过了强测,但是没想到第二次作业输的这么惨。本次作业与以往相同,是在之前作业的功能上增量扩展。我这次尝试了一下直接继承第二次作业的写法,因为这次增量扩展的接口也是一次一次扩展得来的。但是在设计本次作业框架的时候就觉得十分别扭,因为之前的函数全部是按照jml规范写的,直接继承上一次的MyGraph总感觉哪里不舒服。最后我仔细思考了一下原因,我们作业的接口采用继承的方式,是因为它的任务是增量的,每次继承代表功能的增加。而我们的这次增量的作业与上次无具体的父子抽象关系,所以强行使用继承会觉得别扭。所以最后我在图类部分使用了继承,而MyRailwaySystem部分没有使用继承。
代码重构
MyRailwaySystem是直接将上次作业的MyGraph直接粘贴过来。然后用一个新的图类去继承上一次作业写的图类。新建的Hw3NodeGraph.java通过super实现了上一次作业的功能,通过继承扩展方法增加了这次作业的内容。本次作业再次体验到了维护代码的感觉。但是美中不足的是,为了追求性能。我的图类并不是类似于ArrayList这种封装起来的,可以接受外部传入任意数据的图类。而是一个定制方法包。这点在设计上不太好,代码没有通用性。这样的架构在面对小型的增量任务上表现的应该还可以,如果任务有大量的更改,这个方法很有可能需要推倒了重来。本次作业的UML类图如下

在本次计算强连通分量的个数的时候,我复用了上次作业写的BFS方法。并在本次作业添加了dijkstra方法计算车票,不满意度等量。
bug分析
本次作业我格外注重自己写的程序,中测很简单的就通过了。但是在后面继续分析程序的时候,我发现我在dijkstra方法中,使用了PriorityQueue最小优先队列。这个优先队列只有在插入或删除的时候才会维护最小堆的顺序,如果直接修改里面的一个数据,是不会触发最小优先队列顺序的更改的。这就要求我们外部的记录信息要与最小优先队列内部的信息区分开来,一般是选择new一个变量丢进去。我也是这样做的。但是在后面的时候发现了一个非常难调的bug,是查询两点之间换乘次数的指令。我使用了两千条指令,这个bug复现了。于是我过滤掉其它非构图指令,再次测试,发现bug仍然存在。之后就出现了难以理解的一幕——无论我删除哪一条构图指令(不管构图指令中是否包含要查询的两点),bug都不会再次出现。于是我在要换乘的两个点之间的所有点一个一个查,最后发现是从中间某个点开始,换乘次数就错了。我再次找为什么这个点换乘次数是错的,后来发现是最小优先队列弹出的并不是最小的。这时候我大致理解是哪里出错了,我某个地方偶然修改了最小优先队列内部的点,但是它没有更新。在我找出这个问题后,bug自然就解决了。
在强测过程中没有出现问题,总算是在最后挽尊。
5.感想
之前听说电梯是OO难度的巅峰,并且前两次作业都没有挂点,自己便想要在OO上偷懒磨滑,结果湿了半只鞋。再也不敢放松对OO的警惕了。我感觉本次作业的用意并不在于检测我们的代码能力,也不在于学习JML语言,而是让给我们借这个机会,了解工程中的代码编写人员是如何团队协作的。并且,运用JML这种屏蔽“大局观”的工具,可以使每个人只关注自己的那一部分,这也方便工程人员作单元测试。这种“JML”提高团队合作效率的思想值得我们借鉴。

