
北航面向对象Round One
1. 第一次作业总结
1.1 需求分析
第一次作业是对简单多项式的导函数求解。本次作业是符号上的求导操作,而不是具体求值。在输入中,表达式包含且仅包含一行,表示一个多项式。输入数据可以不是最简的多项式,且数据的最大长度为1000。为了优化最短输出,我们需要对相同指数的项进行合并。
1.2 代码实现
大一学C语言的时候,我们就实现过多项式的加法、乘法和求导。当时是采用结构体保存多项式。本次作业,我很容易的就想到了使用类似的结构保存多项式。即构建一个Term类,保存多项式中的每个项。然后装入ArrayList中,作为Poly类的属性。每个Term有幂函数的求导规则,Poly有多项式的求导规则。程序的UML图如下:
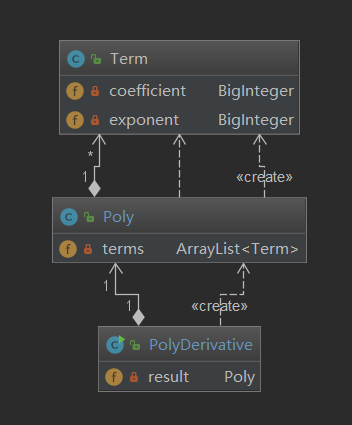
本次作业有三个难点
- 正则表达式匹配输入
- 无序数据的组织管理
- 超长整数的计算
解决过程
1.因为我是第二次写Java程序(第一次是输出"Hello java"),java的正则表达式对我来说是一个陌生的东西,在简单的学习了正则表达式后,我采用了枚举的方法解决这个问题,即枚举出各类输入项的形式,一共五种。接下来就是错误处理的问题,考虑到直接写一个匹配输入的正确形式的正则表达式较为复杂,我选取了先匹配带有空白字符输入错误的情况(从后两次作业来看,这个想法是正确的)第一次作业一共有三种错误的情况,我也是使用枚举的方法匹配输入,然后将\t和<space>替换为空,之后就可以按照无空白字符的方式正则匹配输入了。
2.本次作业中提示了我们可选的数据组织方式,我采用了ArrayList来存储Term。
3.因为输入限制是1000个字符,则极限情况下可以输入一个长达1000位的数字,long类型整数肯定是放不下的。我本来打算使用字符串存这超长整数,然后写两个字符串的加法减法和乘法。还好后来查询了一下,java内置了超长整数的库函数,就没有重复造轮子😢。
1.3 程序结构度量
| 度量对象 | 度量指标 | 值 |
|---|---|---|
| 整个项目 | Lines of Code (LOC) | 248 |
| Poly类 | Lines of Code (LOC) | 112 |
| Term类 | Lines of Code (LOC) | 38 |
| PolyDerivative类(Main) | Lines of Code (LOC) | 98 |
| Poly类 | Number of Methods(NOM) | 6 |
| Term类 | Number of Methods(NOM) | 6 |
| PolyDerivative类(Main) | Number of Methods(NOM) | 11 |
| Poly类 | Lack of Cohesion in Methods(LOCM) | 0.333 |
| Term类 | Lack of Cohesion in Methods(LOCM) | 0.833 |
| PolyDerivative类(Main) | Lack of Cohesion in Methods(LOCM) | 0 |
整个程序写的还是比较啰嗦的,尤其是在输出过程中,为了获得输出结果的性能,进行了很多if-else的判断,代码非常长。在写完代码重新捋代码思路时,又做了一定的修改,减少了十几行的代码,但还是觉得写得很难看。此外,本次代码处理输入时,提前做了同指数的项的合并,并没有将数据输入和数据处理分隔开,写得也有点乱(在后面两次作业放弃了提前合并)。此外,第一次作业只有多项式,结构较为简单,没有采用类的继承。
1.4代码测试
之前就听说了OO课程互测的一些小套路:怼你正则,爆你栈。我使用这个方式测试了自己的程序,例如使用500个+x和空输入等。因为第一次作业比较简单,所以自我测试的时候没测出来什么问题,线上测试也没有什么问题。
1.5小结
本次作业体验了正则表达式的便利(相较于之前编译课所写的内容),OO第一次作业比简单,本次作业是一个既可以使用面向过程和面向对象的方法完成的作业,是我们从面向过程的程序到写面向对象程序的一次过渡。
2. 第二次作业总结
2.1需求分析
本次作业是在多项式求导的基础上增加了sin(x)和cos(x)因子。即可以出现幂函数乘正序函数和余弦函数的情况。按照上次作业的思路,我仍然把要求导的式子划分为由多个项组成初等函数。每个项有四个属性:coefficient、varExp、sinExp、cosExp,分别表示项的系数、项内包含x的指数、项内包含sin(x)的指数和项内包含cos(x)的指数。这样一个设计的优点是,易于在第一次作业的基础上重构代码。因为对一个项的求导可以产生新的项,所以本次作业拥有求导方法的只有Poly类,这样可以将新产生的项即时地加入ArrayList。为了追求结果的性能分,本次作业进行了简单的化简,包括同类项的合并和针对三角函数的部分化简。
2.2代码实现
第二次作业的代码框架与第一次作业的代码框架大致相同。所以第二次作业是在第一次作业的基础上进行更改。同样采用一个Term类,保存表达式中的四个关键数。然后装入ArrayList中,作为Poly类的属性。Poly有表达式的求导规则,对每一个Term类进行求导。程序的UML图如下:
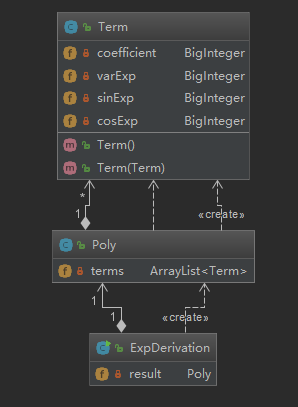
上图和第一次作业中的UML图极为相似。因为框架已经搭好了,所以本次作业的重心就放在数据的输入处理和最终结果优化上。
-
输入处理
针对错误输入,本次作业仍采用了先匹配带有空白字符的错误情况,然后将
\t和<space>替换为空的方法。因为本次作业增加了三角函数,所以错误匹配仅增加了几种带有空白字符的错误情况。最终的错误检查如下:String checkPart1 = "(\\d\\s+\\d)|(\\^\\s*[+-]\\s+\\d)|" + "([+-]\\s*[+-]\\s*[+-]\\s+\\d)|(\\*\\s*[+-]\\s+\\d)"; String checkPart2 = "(s\\s*i\\s+n)|(s\\s+i\\s*n)|(c\\s*o\\s+s)|(c\\s+o\\s*s)"; -
最终结果优化
因为程序最终的结果会出现
sin(x)^2 + cos(x)^2等类似可以化简的情况。所以需要我们从最终给出的表达式中找出可以优化的项,然后对其做合并。我优化的思路非常直接,出现有以下情况的两个项,我就会把这两个项合并。\[Term1:\qquad a_0*x^{a_1}*sin^{a_2}(x)*cos^{a_3}(x)\\ Term2:\qquad b_0*x^{b_1}*sin^{b_2}(x)*cos^{b_3}(x)\\ s.t.\qquad a_1 == b_1\quad and \quad (a_2-b_2)*(a_3-b_3)\leq0\\ |a_2 - b_2| == 2\quad and\quad|a_3 - b_3| == 2 \]但这样一个情况是,遇到
sin(x)或者cos(x)的指数为负数时,优化可能会使最终的结果变得更长,于是我对\(a_2 a_3 b_2 b_3\)进行了特判:只有当他们都为正数时两个项才可以进行化简。这个优化可以说是面向特殊情况的优化,不能对可拆分的三角函数优化进行化简。而且本次优化的思路是贪心的思路,也没有考虑优化路径的问题,所以做的效果一般。但是对某些结果会有很大的优化,例如
程序求导的结果就为1,因为这个式子化简后的结果为\(x\)。
2.3程序结构度量
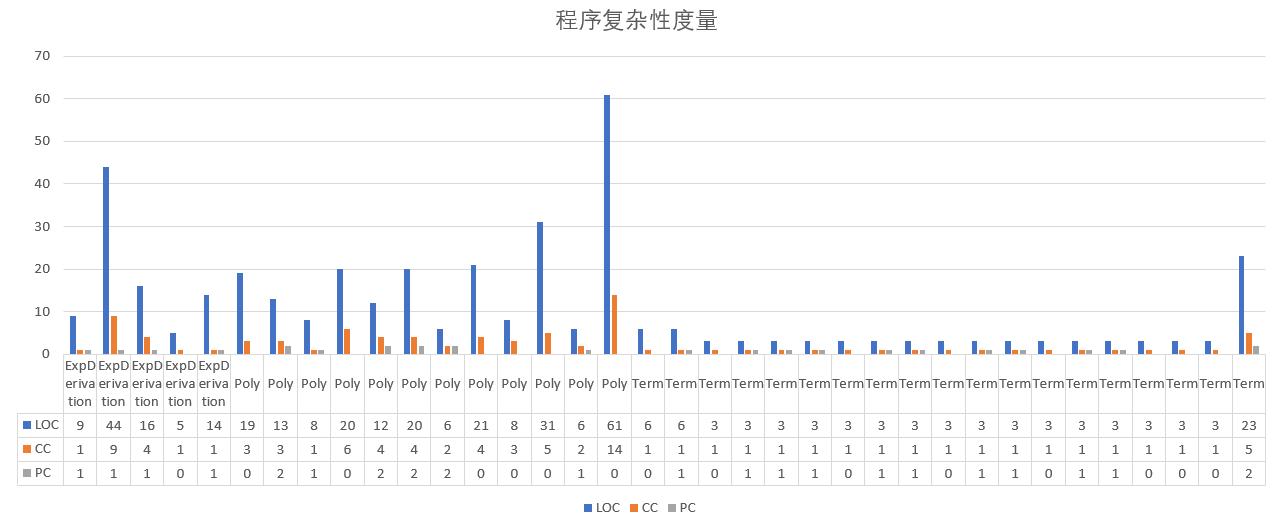
由上图可以看出,本次作业某些方法的复杂度较高,某些方法达到了61行(包括结尾的空格)。是因为本次作业是在第一次作业的基础上直接重构的,某些方法直接添加了新的功能,导致方法的逻辑十分复杂,达到了61行的极限要求。
| 度量对象 | 度量指标 | 值 |
|---|---|---|
| 整个项目 | Lines of Code (LOC) | 395 |
| Poly类 | Lines of Code (LOC) | 215 |
| Term类 | Lines of Code (LOC) | 89 |
| ExpDerivation(Main) | Lines of Code (LOC) | 91 |
| Poly类 | Number of Methods(NOM) | 12 |
| Term类 | Number of Methods(NOM) | 19 |
| ExpDerivation(Main) | Number of Methods(NOM) | 5 |
| Poly类 | Lack of Cohesion in Methods(LOCM) | 0.5 |
| Term类 | Lack of Cohesion in Methods(LOCM) | 0 |
| ExpDerivation(Main) | Lack of Cohesion in Methods(LOCM) | 0.8 |
2.4代码测试
由于本次增加了sin(x)因子和cos(x)因子,所以求导后的结果变得极为复杂,在和舍友的协作下,我们写了一个简单的自动化测试程序。利用python中的Xeger函数,根据正则表达式随机生成相应的字符串。然后使用subprocess,利用管道获得java控制台输出,最后利用sympy中的求导函数diff对正则表达式生成的数据求导,最后按照评测机的测评方法,比对python求导后的值与我们程序跑出结果,验证程序的正确性。但是这种测试有两个致命的弱点:
- 如果你的正则表达式写的不对,那么你只是在用错误的程序验证错误的结果,进而得到错误的答案
- 该程序只能验证你对一部分正确输入格式的数据求导的结果,并不能验证你对错误输入处理的正确性
所以除了脚本测试,我们还聚在一起讨论了自己对输入格式的理解,检查自己正则表达式写的是否正确。此外,在自动化测试之前,我对程序的结构进行了梳理,在梳理过程中,发现了一个笔误——符号写反了。笔误是代码书写中的致命,与做数学题中算错一步没有区别,所以遇到笔误我就记下来,防止以后再次顺手打错。
最终的结果还是可以的,强测全部通过。但是优化的很差,这也与我所花费的时间成比例,毕竟我只花费了两个小时左右的时间对程序作了简单的优化。
2.5小结
第二次作业写的是极快的,因为是直接在第一次作业上更改了一部分代码,然后又加了新的需求,所以写的比较顺利,体验了一把快速重构的好处。
3. 第三次作业总结
3.1需求分析
第三次作业的难度陡然上升,因为输入的数据允许因子的嵌套,而且出现了表达式因子。即可以出现以下情况:
这就对正则表达式获取输入提出了新的要求,也对程序的结构提出了新的要求。所以我需要推倒原来的代码,重新书写。此外,求导还需要用到链式法则。仔细阅读了指导书后,我打算沿用之前两次作业的思路,即把表达式拆分为多个项,每个项拆分为若干个因子。因为每个因子不能使用一个BigInteger代替,所以我为每个因子都设计了一个类。
3.2代码实现
按照指导书的条理,我设计了五种因子:NumFactor、VarFactor、SinFactor、CosFactor、ExprFactor。它们分别处理和保存常数、变量\(x\)、正弦因子、余弦因子、表达式因子。另外设计了一个处理项的类Term和一个处理表达式的类Expression。输入处理也单独划分为一个类ParseInput。第三次oo理论课我们学了继承和多态,因为每个Factor有共通之处,我设计了一个Factor父类,五种因子都继承于此,获得数据处理的方法和根据字符串生成新的因子的方法。
此外,在输入处理时,我们寝室讨论出一个trick(由SDY提出)。因为本次作业输入可以有括号的嵌套,这样对正则表达式识别括号带来了很大的困难。我们借鉴了从计算机网络课程中学习到的处理数据包的思想——掐头去尾+替换。正则表达式不需要识别括号,而是用另外一个程序将顶层括号识别出来,并替换成一个在输入中不会出现的字符(当然在做此处理之前要对输入检验是否提前带有此字符)。然后正则表达式匹配替换的字符,这样就不会出现括号的歧义问题。例如,我们采用字符Y替换括号,若输入为:
第一次替换结果为
之后正则表达式sinY[^Y]+Y(\\^[+-]?\\d{1,5})?即可对其精准捕捉。然后去掉最外层的sinY和Y即可递归分析输入的表达式。
对于错误处理,同样,本次采用枚举错误,替换空白字符的方法对输入处理。这个方法从第一次沿用至第三次,说明其通用性很强,效果也很好。本次作业的出错情况与第二次相同,这里就不再赘述。
程序的UML图如下:
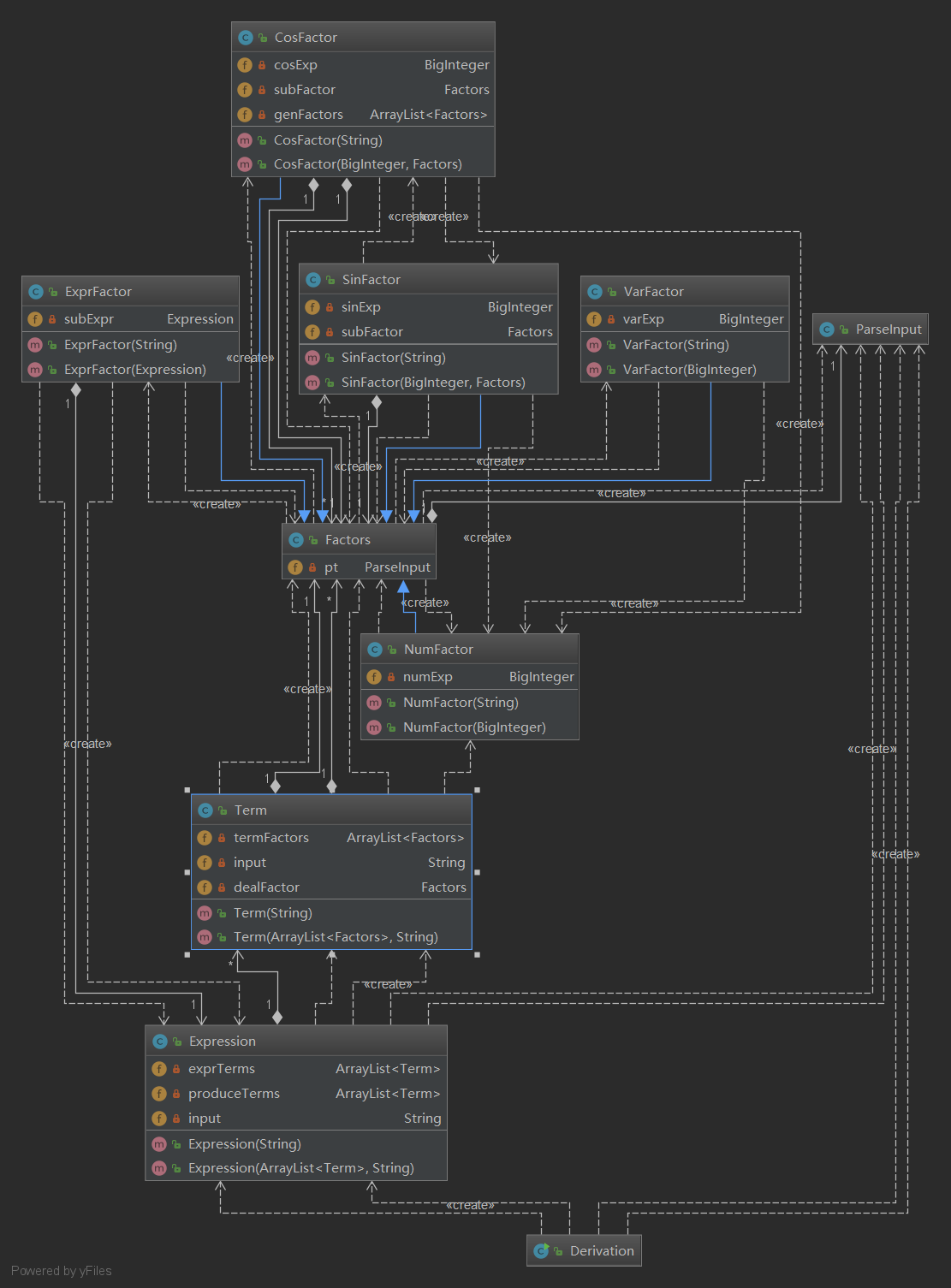
从上图我们可以看出,第三次作业明显比前两次作业复杂,但是只要有了正确的设计,很快就能写完。在我设计的五种因子中,NumFactor和VarFactor是程序递归的出口。并且,每个因子类都有处理字符串输入的能力,用于判断是否有嵌套因子,以及生成嵌套因子。最后ExprFactor中包含了一个属性——实例化的Expression类,做到表达式因子的递归。此外,每个类还重写了toString方法,作为将自己保存数据的输出函数。每个类包含的方法如下:
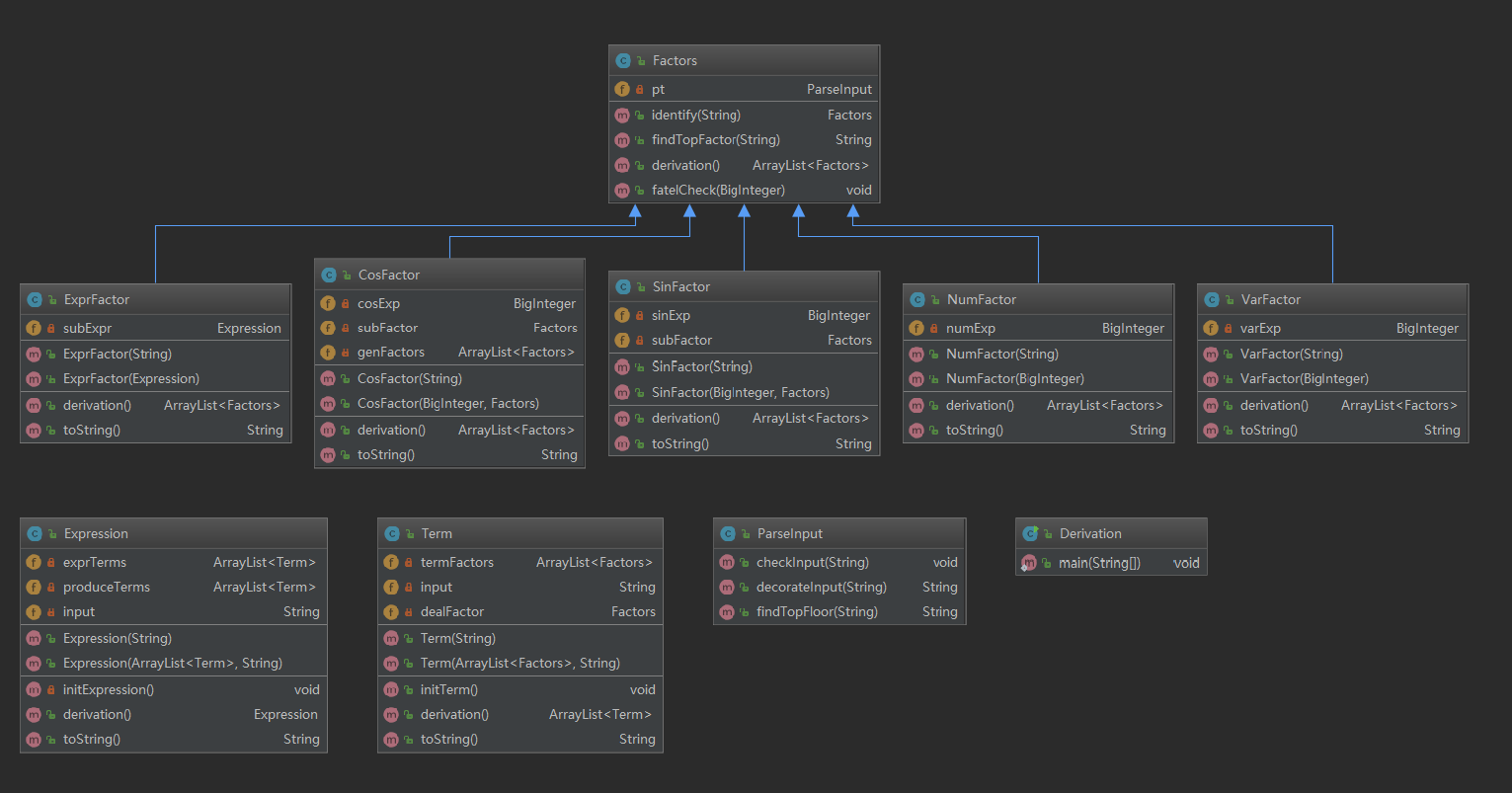
相较前两次作业,本次作业代码写的优雅了一些。
3.3程序结构度量
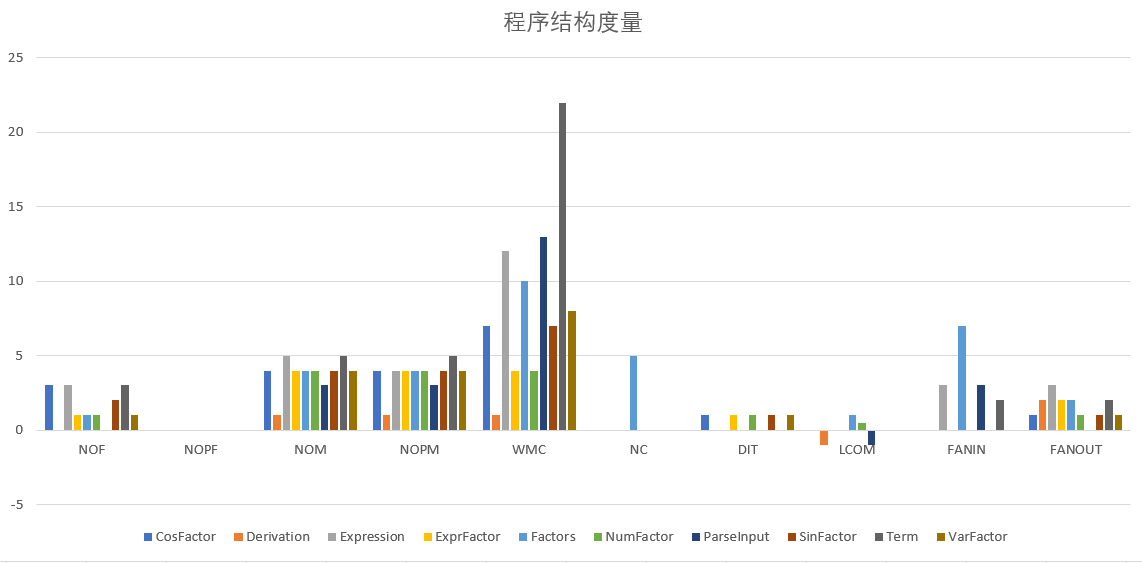
由上图可以看出,程序的LCOM值非常小,且FANIN值较大,FANOUT的值适中。所以程序的高内聚低耦合做的还可以。并且使用了Factor的继承,使得程序最大深度为1。
| 度量对象 | 度量指标 | 值 |
|---|---|---|
| 整个项目 | Lines of Code (LOC) | 465 |
| CosFactor | Lines of Code (LOC) | 47 |
| Derivation | Lines of Code (LOC) | 18 |
| Expression | Lines of Code (LOC) | 68 |
| ExprFactor | Lines of Code (LOC) | 23 |
| Factors | Lines of Code (LOC) | 45 |
| NumFactor | Lines of Code (LOC) | 18 |
| ParseInput | Lines of Code (LOC) | 56 |
| SinFactor | Lines of Code (LOC) | 44 |
| Term | Lines of Code (LOC) | 106 |
| VarFactor | Lines of Code (LOC) | 40 |
从代码量来看,虽然本次作业的复杂度骤升,但是采用了正确的设计思路后,程序的代码量上浮不大。
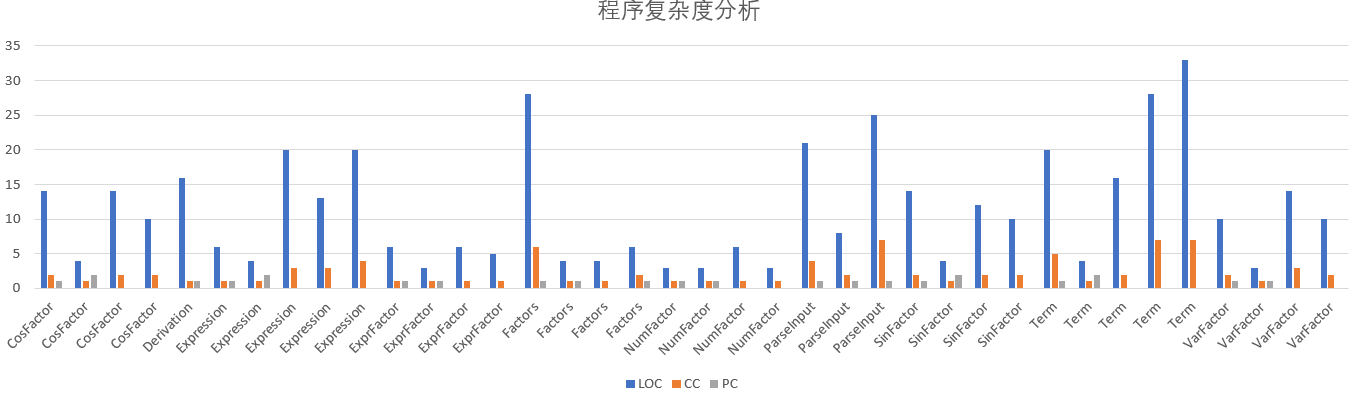
从每个方法的复杂度分析来看,本次程序最长的方法只有33行,相较于第二次作业已经有了非常大的改善。我认为,第三次作业是我这三次作业中比较好的一次。但是优化部分做的很少,只有对常数因子的合并和输出时指数为1的因子省略指数输出等。没有做项与项之间的合并和括号的去除。
3.4代码测试
还是按照之前的惯例,我梳理了一下程序的框架,因为程序思路比较清晰,所以很快就检查完了程序。在检查中,又发现了几个笔误(Ctrl+C、Ctrl+V害死人)。通过中测后,我又使用之前的python脚本验证(后面的作业是兼容前面的作业的)。再后来又使用了wsyc写的可以生成嵌套版的脚本跑了十几分钟,没有检测出问题。就结束了debug阶段。但是这并不意味这没有bug,直到最后一次作业结束,我们才想起来使用Junit等测试工具对程序测试。浪费了在作业轻松时掌握测试工具的机会,以后再学习工具的使用可能时间就比较紧张了。
3.5小结
本次作业在之前的基础上再次加大了难度,课程组是想让我们使用继承和多态来完成本次任务,并且尽量考虑代码的可扩展性。在完成部分,我认为只要思考出一个较好的实现框架,程序写起来就会很舒服,很快。本次作业放弃了输出性能部分,只做了一点优化,保证了代码的正确性,AC了强测,还是一个比较好的结果。
4.三次作业的代码重构
在做第一次作业时,没有考虑到后面还会追加表达式求导的任务,本以为之后会和往常一样,之后就是电梯作业。没想到第二次还是表达式求导,不过是添加了新的要求。从第一次和第二次代码的UML图也可以看出,第一次的代码是有一定的可扩展性的,第二次作业就是在第一次代码的基础上更改了Term类的属性,增加了代表几种因子的private变量:varExp、sinExp、cosExp,增加了输出优化模块,完完全全使用第一次的框架。
这三次作业的难度其实在第二次作业向第三次作业的转化,前两次作业的架构对函数嵌套的对应能力为0.但是把表达式区分为项和因子的思想是正确的。第三次作业将数据处理、因子、项拉出来形成一个类,可以说真真有了面向对象的概念。(前两次作业按照面向对象的思想写的话,应该是多出来数据处理类和因子类的or2),第三次作业写的代码应对追加任务的能力较强。如果追加了新的因子,如\(e^x\)等,只需要新添加一个因子类,继承自Factor,写上自己的求导方法然后再在数据处理中添加识别此因子的正则表达式,别的代码一概不需要更改。如果添加新的运算规则,如除法,只需要将因子的次数改成负数,求导方式不需要更改。可以说第三次作业写出的代码的可扩展性很高。
5.总结
这三次作业算是初识面向对象编程,掌握了书写java代码一些基本方法,侥幸强测没挂掉点,但是性能分后两次没怎么拿。这不意味是一个No Bug Man,还是应该趁着一些时间学习JUnit等测试框架才是。听说后面就要上多线程了,自求多福吧QAQ。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号