
20172304 实验二报告
20172304 实验二报告
- 课程:《软件结构与数据结构》
- 班级: 1723
- 姓名: 段志轩
- 学号:20172304
- 实验教师:王志强
- 助教:张师瑜&张之睿
- 实验日期:2018年11月5日-2018年11月12日
- 必修选修: 必修
实验要求
实验一:实现二叉树
参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
课下把代码推送到代码托管平台
实验二:中序先序序列构造二叉树
基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树,用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
实验三:决策树
自己设计并实现一颗决策树,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
实验四:表达式树
输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分),提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
实验五:二叉查找树
完成PP11.3,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
实验六 : 红黑树分析
参考本博客:点击进入对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
实验过程及实验结果
实验一过程及结果:
LinedBinaryTree码云链接
测试类及测试结果
package week6.jsjf;
public class LinkedBinaryTreeTest {
public static void main(String[] args) throws InterruptedException {
LinkedBinaryTree c=new LinkedBinaryTree("b");LinkedBinaryTree b=new LinkedBinaryTree("c");LinkedBinaryTree a=new LinkedBinaryTree("Translation",c,b);
LinkedBinaryTree e=new LinkedBinaryTree("F");
LinkedBinaryTree f=new LinkedBinaryTree("g",a,e);
System.out.println("二叉树的toString方法");
System.out.println(f.toString());
System.out.println("二叉树的先序遍历");
f.preorder(f.getRootNode());
System.out.println();
System.out.println("二叉树的后序遍历");
f.postorder(f.getRootNode());
System.out.println();
System.out.println("二叉树的中序遍历");
f.Inorder(f.getRootNode());
System.out.println();
System.out.println("二叉树的层序遍历");
f.unrecursionlevelOreder(f.getRootNode());
System.out.println();
System.out.println( "查找是否包含a的结果:"+f.contains("Translation")+"二叉树中的元素:"+"b, c, Translation, F, g");
System.out.println("查找是否包含A的结果:"+f.contains("A")+"二叉树中的元素:"+"b, c, Translation, F, g");
System.out.println("getRight方法的检验,即输出树的根节点的右子树");
System.out.println(f.getRight().toString());
System.out.println("getLeft方法的检验,即输出树的根节点的左子树");
System.out.println(f.getLeft().toString());
System.out.println("二叉树的高度:"+f.getHeight()+"二叉树的元素个数:"+f.size()+"二叉树的根元素"+f.getRootElement());
}
}


实验二
这个实验要求的是通过给定的中缀表达式和后缀表达式构建二叉树题目中给定了中序HDIBEMJNAFCKGL和先序ABDHIEJMNCFGKL。
我们由先序知道二叉树的根节点是为A,在中序遍历中就可以知道以A为根节点的左子树为“HDIBEMJN”,右子树为“FCKGL”。由于我是使用数组记录的两个序列。所以在每一次确定完根节点以后,我就会更新数组的指针,在通过递归依次确定左子树的根节点和右子树的根节点,在进行过几次递归之后。就可以得到以中序遍历以及先序遍历为基础的二叉树了。
测试结果

BTCreation码云链接
实验三
决策树,这个的实现是基于书上的代码,这个实际上也没有也没有太大的难度
DecisionTree码云链接
CharacterAnalyzer
这是我设计的决策树

测试结果

实验四
这个实验主要要求是通过二叉树将中缀表达式转为后缀表达式,输出并计算后缀表达式并计算后缀表达式的结果。
实验分析:书上已经有了将后缀表达式构建二叉树并计算的方法了,实际上饿哦们只需要将中缀表达式按照优先级的顺序录入二叉树中,就可以调用树中的方法计算并得到结果了。然后我就做了实际上原理与那个直接中缀转后缀相仿。
码云链接
Translation
测试结果截图

测试代码
public static void main(String[] args) {
Translation translation =new Translation();
String a="8 / 4 - 9 + 11 * 2";
translation.Translate(a);
System.out.println("中缀表达式树是");
System.out.println(translation.getTree());
System.out.println("后序遍历是"+translation.PostOrder());
System.out.println("结果是"+translation.getResult());
}
实验五
这个实验主要就是测试一下没有什么好讲的
码云链接
LinkedBinarySearchTree
测试代码
package week7.jsjf;
public class LinkedBinarySearchTreeTest {
public static void main(String[] args) throws InterruptedException {
LinkedBinarySearchTree a=new LinkedBinarySearchTree();
a.addElement(80);
a.addElement(10);
a.addElement(9);
a.addElement(6);
a.addElement(7);
a.addElement(85);
a.addElement(16);
a.addElement(44);
System.out.println(a.toString());
System.out.println(a.findMax());
System.out.println(a.findMin());
System.out.println(a.find(85));
a.removeElement(10);
System.out.println(a.toString());
a.removeMax();
System.out.println(a.toString());
a.removeMin();
System.out.println(a.toString());
}
}
测试结果

//Node是单向链表,它实现了Map.Entry接口
static class Node<k,v> implements Map.Entry<k,v> {
final int hash;
final K key;
V value;
Node<k,v> next;
//构造函数Hash值 键 值 下一个节点
Node(int hash, K key, V value, Node<k,v> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + = + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
实验六
TreeMap
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)
//构建一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空哈希映像
HashMap()
//构建一个哈希映像,并且添加映像m的所有映射
HashMap(Map<? extends K,? extends V> m)
//构建一个拥有特定容量的空的哈希映像
HashMap(int initialCapacity)
//构建一个拥有特定容量和加载因子的空的哈希映像
HashMap(int initialCapacity, float loadFactor)
- TreeMap的Empty方法,firstEntry()和getFirstEntry()都是用于获取第一个节点。但是,firstEntry() 是对外接口;getFirstEntry()是内部接口。而且,firstEntry()是通过getFirstEntry()来实现的。两个方法并会显得很麻烦,因为通过firstEntry()方法和可以避免修改返回的Entry,这样保证了完整性,而且产生了两个方法,一个可以是避免修改的方法,一个可以是修改的方法。通过查阅资料可以总结出对firstEntry()返回的Entry对象只能进行getKey()、getValue()等读取操作;而对getFirstEntry()返回的对象除了可以进行读取操作之后,还可以通过setValue()修改值。
public Map.Entry<K,V> firstEntry() {
return exportEntry(getFirstEntry());
}
final Entry<K,V> getFirstEntry() {
Entry<K,V> p = root;
if (p != null)
while (p.left != null)
p = p.left;
return p;
}
- TreeMap的Key方法,返回大于/等于key的最小的键值对所对应的KEY,没有的话返回null。
public K ceilingKey(K key) {
return keyOrNull(getCeilingEntry(key));
}
- TreeMap的values方法,values方法是通过new Values()来实现返回TreeMap中值的集合,而Values()正好是集合类Value的构造函数,这样返回的是一个集合了。
public Collection<V> values() {
Collection<V> vs = values;
return (vs != null) ? vs : (values = new Values());
}
- TreeMap的entrySet方法,entrySet方法是返回TreeMap的所有键值对组成的集合,而且它单位是单个键值对。
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet());
}
- TreeMap还有两个遍历方法,顺序遍历和逆序遍历,顺序遍历,就是从第一个元素开始,逐个向后遍历;而倒序遍历则恰恰相反,它是从最后一个元素开始,逐个往前遍历。
- TreeMap遍历键值对的方法,先根据entrySet()获取TreeMap的“键值对”的Set集合,再通过迭代器遍历得到的集合。
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
integ = (Integer)entry.getValue();
}
- TreeMap遍历键的方法,先keySet()获取TreeMap的键的Set集合,再通过迭代器遍历得到的集合。
String key = null;
Integer integer = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
key = (String)iter.next();
integer = (Integer)map.get(key);
}
HashMap
这个类我们已经很熟悉了,所谓哈希查找就是将所要存储的数据通过一个公式来进行计算,得到所谓的“地址”,然后储存在数组对应的“地址”中例如“5%4=1,8%4=0”,则“5”和“8”的地址分别为“1“和”0”,但有时地址之间会发生冲突,这是就要通过其他方法来解决冲突,在就java自带的HashMap中,解决这个冲突的方法是链地址法,也就是指在数组中存放的是链表,一旦存入的数据的地址发生冲突,那么久将其插入链表之中,这样就很好的解决了冲突的问题,在jdk1.8版本之前,解决冲突的首端都是通过链表,但是在jdk1.8.0中,解决这个问题的方案变成了两个,就是在当链表中的元素小于或等于8个是,使用单链表来解决这个问题,当发生冲突的元素个数大于8个是,就使用一个红黑树来储存这些元素,这样可以提高效率。
HashMap储存形式图例
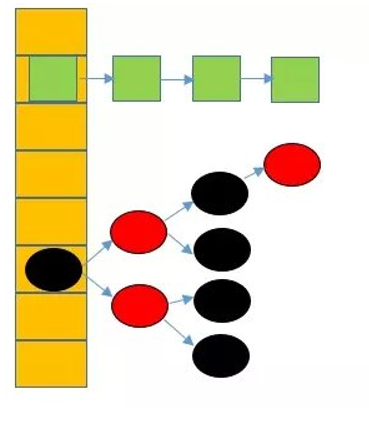
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。下列代码可以近似理解成类似于单链表的结点类
//Node是单向链表,它实现了Map.Entry接口
static class Node<k,v> implements Map.Entry<k,v> {
final int hash;
final K key;
V value;
Node<k,v> next;
//构造函数Hash值 键 值 下一个节点
Node(int hash, K key, V value, Node<k,v> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + = + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
这是红黑树的相关结点类
//红黑树
static final class TreeNode<k,v> extends LinkedHashMap.Entry<k,v> {
TreeNode<k,v> parent; // 父节点
TreeNode<k,v> left; //左子树
TreeNode<k,v> right;//右子树
TreeNode<k,v> prev; // needed to unlink next upon deletion
boolean red; //颜色属性
TreeNode(int hash, K key, V val, Node<k,v> next) {
super(hash, key, val, next);
}
//返回当前节点的根节点
final TreeNode<k,v> root() {
for (TreeNode<k,v> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}
这是插入节点的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
// 步骤③:节点key存在,直接覆盖value
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// 步骤④:判断该链为红黑树
// hash值不相等,即key不相等;为红黑树结点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:该链为链表
// 为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 步骤⑥:超过最大容量 就扩容
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
平衡红黑树的代码
static <K, V> TreeNode<K, V> balanceInsertion(TreeNode<K, V> root, TreeNode<K, V> x) {
//将插入的节点涂成红色
x.red = true;
//此时x节点是刚插入的节点
// 这些变量名不是作者随便定义的都是有意义的。
// xp:x parent,代表x的父节点。
// xpp:x parent parent,代表x的祖父节点
// xppl:x parent parent left,代表x的祖父的左节点。
// xppr:x parent parent right,代表x的祖父的右节点。
for (TreeNode<K, V> xp, xpp, xppl, xppr;;) {
//如果x.parent==null证明x是根节点,并将x(根节点)返回;平衡完毕。
if ((xp = x.parent) == null) {
//将根节点涂成黑色
x.red = false;
return x;
//只要进入此if就不会满足注释中3条件的任意一个,直接将root返回;平衡完毕。
} else if (!xp.red || (xpp = xp.parent) == null)
return root;
//若父节点是祖父节点的左子节点,与下面的完全相反,本质是一样的
if (xp == (xppl = xpp.left)) {
//x节点的祖父节点的右子节点(叔叔节点)不为null且是红色,父节点必然也是红色,此时满足第1种情况。
//操作:1.将祖父节点的右子节点(叔叔节点)、父节点涂为黑色
// 2.将祖父节点涂为红色
// 3.将祖父节点赋给x(参照节点的变更)
if ((xppr = xpp.right) != null && xppr.red) {
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
//进入else 说明已经是第2或第3种情况了
} else {
//第2种情况
// 操作:1.标记节点变为x。
// 2.左旋
// 3.x的父节点、x的祖父节点随之变化
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//第3种情况
//操作 1.将父节点涂黑
// 2.祖父节点涂红
// 3.右旋
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
} else {//若父节点是祖父节点的右子节点,与上面的完全相反,本质一样的
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
} else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
扩展Hash表的代码
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab指向hash桶数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//如果oldCap不为空的话,就是hash桶数组不为空
if (oldCap >= MAXIMUM_CAPACITY) {//如果大于最大容量了,就赋值为整数最大的阀值
threshold = Integer.MAX_VALUE;
return oldTab;//返回
}//如果当前hash桶数组的长度在扩容后仍然小于最大容量 并且oldCap大于默认值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 双倍扩容阀值threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新建hash桶数组
table = newTab;//将新数组的值复制给旧的hash桶数组
if (oldTab != null) {//进行扩容操作,复制Node对象值到新的hash桶数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//如果旧的hash桶数组在j结点处不为空,复制给e
oldTab[j] = null;//将旧的hash桶数组在j结点处设置为空,方便gc
if (e.next == null)//如果e后面没有Node结点
newTab[e.hash & (newCap - 1)] = e;//直接对e的hash值对新的数组长度求模获得存储位置
else if (e instanceof TreeNode)//如果e是红黑树的类型,那么添加到红黑树中
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;//将Node结点的next赋值给next
if ((e.hash & oldCap) == 0) {//如果结点e的hash值与原hash桶数组的长度作与运算为0
if (loTail == null)//如果loTail为null
loHead = e;//将e结点赋值给loHead
else
loTail.next = e;//否则将e赋值给loTail.next
loTail = e;//然后将e复制给loTail
}
else {//如果结点e的hash值与原hash桶数组的长度作与运算不为0
if (hiTail == null)//如果hiTail为null
hiHead = e;//将e赋值给hiHead
else
hiTail.next = e;//如果hiTail不为空,将e复制给hiTail.next
hiTail = e;//将e复制个hiTail
}
} while ((e = next) != null);//直到e为空
if (loTail != null) {//如果loTail不为空
loTail.next = null;//将loTail.next设置为空
newTab[j] = loHead;//将loHead赋值给新的hash桶数组[j]处
}
if (hiTail != null) {//如果hiTail不为空
hiTail.next = null;//将hiTail.next赋值为空
newTab[j + oldCap] = hiHead;//将hiHead赋值给新的hash桶数组[j+旧hash桶数组长度]
}
}
}
}
}
return newTab;
}
代码调试时遇见的问题
问题:怎么用二叉树将中缀表达式转为后缀表达式
解答:一开始真的没有什么思路。后来经过长时间的思考以及在咨询过老师之后,大概知道了思路,具体思路就是将输入的中缀表达式根据优先级的顺序插入到树中(以运算符为根,然后优先级的优先的输入到左子树中)具体操作在注释中
public Translation(){
tree = new Stack<ExpressionTree>();
stack = new Stack();
}
private ExpressionTree getOperand(Stack<ExpressionTree> treeExpression){
ExpressionTree num;
num = treeExpression.pop();
return num;
}
public ExpressionTree Translate(String expression){
ExpressionTree operand1,operand2;
char operator;
String tempToken;
Scanner parser = new Scanner(expression);
while(parser.hasNext()){
tempToken = parser.next();//这个方法就是类似于StringTokenizer方法将一个字符串根据分割符分成不同的几个字符块
operator=tempToken.charAt(0);//引用字符块开头的字节码
if ((operator == '+') || (operator == '-') || (operator=='*') || (operator == '/'))//判断是否为运算符{
if (stack.empty())
stack.push(tempToken);//当储存符号的栈为空时,直接进栈
else{
String a =stack.peek()+"";//因为当ope.peek()='-'时,计算机认为ope.peek()=='-'为false,所以要转化为string 使用equals()方法
if (((a.equals("+"))||(a.equals("-")))&&((operator=='*')||(operator=='/')))//这是判断优先级的方法。
stack.push(tempToken);//当得到的符号的优先级大于栈顶元素时,直接进栈
else {
String s = String.valueOf(stack.pop());
char temp = s.charAt(0);
operand1 = getOperand(tree);//这是将数字实例化成树的类型
operand2 = getOperand(tree);//这是将数字实例化成树的类型
tree.push(new ExpressionTree(new ExpressionTreeOp(1, temp, 0), operand2, operand1));//这是以运算符为根节点,然后以运算数为左右子节点构建二叉树。
stack.push(operator);
}//当得到的符号的优先级小于栈顶元素或者优先级相同时时,数字栈出来两个运算数,形成新的树进栈
}
}
else
tree.push(new ExpressionTree(new ExpressionTreeOp(2,' ',Integer.parseInt(tempToken)), null, null));
}
while(!stack.empty()){
String a = String.valueOf(stack.pop());
operator = a.charAt(0);
operand1 = getOperand(tree);//这是将数字实例化成树的类型
operand2 = getOperand(tree);//这是将数字实例化成树的类型
tree.push(new ExpressionTree(new ExpressionTreeOp(1, operator, 0), operand2, operand1));//这是以运算符为根节点,然后以运算数为左右子节点构建二叉树。
}
return tree.peek();
}
public String getTree()
{
return (tree.peek()).printTree();
}
public int getResult(){
return tree.peek().evaluateTree();
}
public String PostOrder(){
Iterator iterator = tree.peek().iteratorPostOrder();
String result="";
for (;iterator.hasNext();)
result +=iterator.next()+" ";
return result;
}
}
其他
这次实验难点在于实验二和一些实验四,即利用中序和后序遍历来生成二叉树,和使用二叉树将中缀表达式转为后缀表达式,至于其他的实验更加侧重于练习。只有经过不断地练习,熟悉,我们才能更加熟练的使用各种类和方法,才能够更加创造性的进行开发和应用。
