

本周总结
一、
(1) 项目名称:信息化领域热词分类分析及解释
(2) 功能设计:
数据采集:要求从定期自动从网络中爬取信息领域的相关热
词;
数据清洗:对热词信息进行数据清洗,并采用自动分类技术
生成信息领域热词目录,;
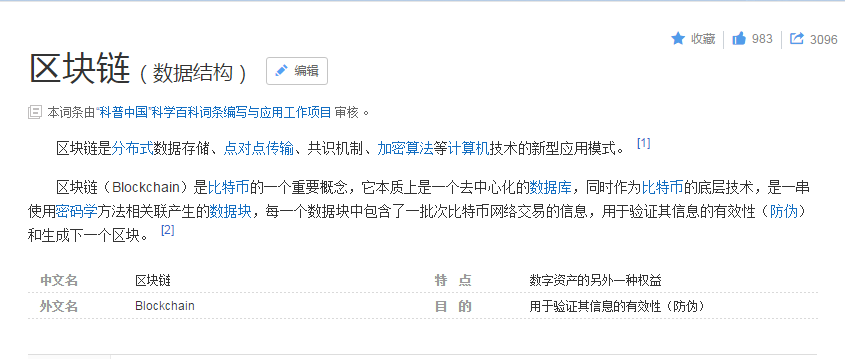
热词解释:针对每个热词名词自动添加中文解释(参照百度
百科或维基百科)
热词引用:并对近期引用热词的文章或新闻进行标记,生成
超链接目录,用户可以点击访问;
数据可视化展示:
① 用字符云或热词图进行可视化展示;
② 用关系图标识热词之间的紧密程度。
首先我爬取热词的地址是博客园:https://news.cnblogs.com/n/recommend
python代码:
import requests import re import xlwt url = 'https://news.cnblogs.com/n/recommend' headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" } def get_page(url): try: response = requests.get(url, headers=headers) if response.status_code == 200: print('获取网页成功') print(response.encoding) return response.text else: print('获取网页失败') except Exception as e: print(e) f = xlwt.Workbook(encoding='utf-8') sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) sheet01.write(0, 0, '博客最热新闻') # 第一行第一列 urls = ['https://news.cnblogs.com/n/recommend?page={}'.format(i * 1) for i in range(100)] temp=0 num=0 for url in urls: print(url) page = get_page(url) items = re.findall('<h2 class="news_entry">.*?<a href=".*?" target="_blank">(.*?)</a>',page,re.S) print(len(items)) print(items) for i in range(len(items)): sheet01.write(temp + i + 1, 0, items[i]) temp += len(items) num+=1 print("已打印完第"+str(num)+"页") print("打印完!!!") f.save('Hotword.xls')
爬取结果截图:

然后继续在爬取结果里面进行筛选,选出100个出现频率最高的信息热词。
Python代码:
import jieba import pandas as pd import re from collections import Counter if __name__ == '__main__': filehandle = open("Hotword.txt", "r", encoding='utf-8'); mystr = filehandle.read() seg_list = jieba.cut(mystr) # 默认是精确模式 print(seg_list) # all_words = cut_words.split() # print(all_words) stopwords = {}.fromkeys([line.rstrip() for line in open(r'final.txt',encoding='UTF-8')]) c = Counter() for x in seg_list: if x not in stopwords: if len(x) > 1 and x != '\r\n': c[x] += 1 print('\n词频统计结果:') for (k, v) in c.most_common(100): # 输出词频最高的前两个词 print("%s:%d" % (k, v)) # print(mystr) filehandle.close(); # seg2 = jieba.cut("好好学学python,有用。", cut_all=False) # print("精确模式(也是默认模式):", ' '.join(seg2))
里面的那个final.txt是将那些单词比如“我们”,“什么”,“中国”,“没有”,这些句子常出现的词语频率高但是跟信息没有关系的词语,我们将他们首先排除。
final.txt:

运行结果:

然后将他们存入txt,导入mysql。
之后我们继续进行爬取,爬取百度百科每个热词的解释。
Python源代码:
import requests import re import xlwt import linecache url = 'https://baike.baidu.com/' headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36" } def get_page(url): try: response = requests.get(url, headers=headers) response.encoding = 'utf-8' if response.status_code == 200: print('获取网页成功') #print(response.encoding) return response.text else: print('获取网页失败') except Exception as e: print(e) f = xlwt.Workbook(encoding='utf-8') sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) sheet01.write(0, 0, '热词') # 第一行第一列 sheet01.write(0, 1, '热词解释') # 第一行第二列 sheet01.write(0, 2, '网址') # 第一行第三列 fopen = open('C:\\Users\\hp\\Desktop\\final_hotword2.txt', 'r',encoding='utf-8') lines = fopen.readlines() urls = ['https://baike.baidu.com/item/{}'.format(line) for line in lines] i=0 for url in urls: print(url.replace("\n", "")) page = get_page(url.replace("\n", "")) items = re.findall('<meta name="description" content="(.*?)">',page,re.S) print(items) if len(items)>0: sheet01.write(i + 1, 0,linecache.getline("C:\\Users\\hp\\Desktop\\final_hotword2.txt", i+1).strip()) sheet01.write(i + 1, 1,items[0]) sheet01.write(i + 1, 2,url.replace("\n", "")) i+= 1 print("总爬取完毕数量:" + str(i)) print("打印完!!!") f.save('hotword_explain.xls')

