FPGA设计性能优化策略漫谈(一)--时序优化
1 速度优化
1.1 关键路径重组
FPGA逻辑设计中时序路径上的组合逻辑都会给路径增加延时,从而影响设计性能的往往只有几条关键的路径而已,所以可以通过减少关键路径上的组合逻辑单元数来减小该路径上的延时,从而达到优化的目的。关键路径重组技术多用于关键路径由多个路径组合而成的场合,而且这些被组合的路径之间又可以重组相互之间的先后顺序,从而使得寄存器之间的关键路径被拉近。以如下代码为例。
module critical_path ( input clk, input in1, input in2, input sel, input critical, output reg out ); reg out_reg; always @ ( * ) begin if (critical && sel) out_reg = in1; else out_reg = in2; end always @ (posedge clk) begin out <= out_reg; end endmodule

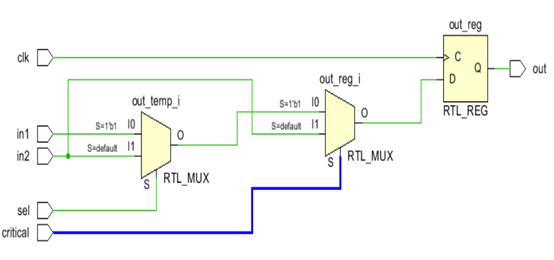
假设critical经过的路径的为关键路径,通过Vivado编译后实现的电路图可以看出,critical经过了两个逻辑单元。
为了减少critical经过的逻辑单元数,修改为如下代码,使得critical经过的逻辑单元数变为一个。
module critical_path ( input clk, input in1, input in2, input sel, input critical, output reg out ); reg out_reg; reg out_temp; always @ ( * ) begin if (sel) out_temp = in1; else out_temp = in2; end always @ ( * ) begin if (critical) out_reg = out_temp; else out_reg = in2; end always @ (posedge clk) begin out <= out_reg; end endmodule
1.2 逻辑复制
逻辑复制是一种通过增加面积来改善时序条件的优化手段,最常使用的场合是调整信号的扇出。如果某个信号需要驱动后级很多单元,此时该信号的扇出非常大,那么为了增加这个信号的驱动能力,一种办法就是插入多级Buffer,虽然这样能增加驱动能力,但是也增加了这个信号的路径延时。为了避免这种情况,此时可以复制生成这个信号的逻辑,用多路同频同相的信号驱动后续电路,使平均到每路的扇出变低,这样不需要插入Buffer就能满足驱动能力增加的要求,从而节约该信号的路径延时。
在大部分逻辑设计中,高扇出信号多为同步信号,即寄存器信号,所以进行逻辑复制时是对寄存器进行复制。由于高扇出信号会增加布局布线的难度,减缓布线速度,因此可以通过寄存器复制解决两个问题:
- 减少扇出,缩短布线延时;
- 复制后每个寄存器可以驱动芯片的不同区域,有利于布局布线。
1.3 并行处理
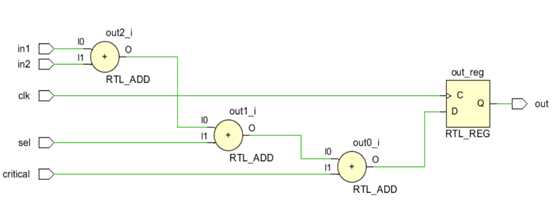
使用并行结构可以优化关键路径上的延时,本质就是通过重组组合逻辑达到提升设计性能的目的。以如下代码在Vivado中编译查看RTL视图,并且修改代码重新编译,对比可知在结构上,第一种代码没有使用括号电路结构为3层,加法一级一级的进行,它的特点是4个输入到达加法器的路径不相等。而第二种描述使用了括号,即操作符平衡,电路结构分为两层,它的特点是4个输入到达加法器的路径是相等的。
module critical_path ( input clk, input in1, input in2, input sel, input critical, output reg out ); always @ (posedge clk) begin out <= in1 + in2 + sel + critical; end endmodule

修改代码如下,实现数据的并行处理。
always @ (posedge clk) begin out <= (in1 + in2) + (sel + critical); end
1.4 寄存器操作
1.4.1 插入寄存器
在逻辑设计中,如果寄存器到寄存器的逻辑路径过长,就会成为影响设计的关键路径。这时可以考虑在该路径上插入额外的寄存器,这种插入寄存器的方法,也被称为插入流水线,这种技巧多用于高度流水的设计中,虽然这种插入额外的寄存器增加了时钟周期的延迟,但并不会违反整个设计的要求,从而不会影响设计的整体功能实现,即插入额外的寄存器在保持吞吐量不变的情况下改善了设计的时序性能。当然,鱼与熊掌不可兼得,提升了系统频率,不可避免的会带来面积的增加。
module critical_path ( input clk, input rst_n, input [ 3:0] in1, input [ 3:0] in2, input [ 3:0] in3, input [ 3:0] in4, output reg [15:0] out ); reg [3:0] in1_temp,in2_temp,in3_temp,in4_temp; always @ (posedge clk or negedge rst_n) begin if (rst_n)begin in1_temp <= 1'd0; in2_temp <= 1'd0; in3_temp <= 1'd0; in4_temp <= 1'd0; out <= 1'd0; end else begin in1_temp <= in1; in2_temp <= in2; in3_temp <= in3; in4_temp <= in4; out <= (in1_temp*in2_temp)*(in3_temp*in4_temp); end end endmodule
将上诉代码编译后得到下图所示结果,从中可以三个乘法器分为两级,而两级乘法器之间并无寄存器,一般情况下这种乘法器的处理均要求在一个时钟周期之内完成,即图中的关键路径包含了两个乘法器,使得路径延时有可能大于一个时钟周期,也就无法满足上面一个周期内完成操作的最小要求。因此,在两个乘法器之间插入一级流水,修改后的代码如下。

module critical_path ( input clk, input rst_n, input [ 3:0] in1, input [ 3:0] in2, input [ 3:0] in3, input [ 3:0] in4, output reg [15:0] out ); reg [3:0] in1_temp,in2_temp,in3_temp,in4_temp; reg [7:0] in1_reg,in2_reg; always @ (posedge clk or negedge rst_n) begin if (rst_n)begin in1_temp <= 1'd0; in2_temp <= 1'd0; in3_temp <= 1'd0; in4_temp <= 1'd0; in1_reg <= 1'd0; in2_reg <= 1'd0; out <= 1'd0; end else begin in1_temp <= in1; in2_temp <= in2; in3_temp <= in3; in4_temp <= in4; in1_reg <= in1_temp * in2_temp; in2_reg <= in1_temp * in2_temp; out <= in1_reg * in2_reg; end end endmodule
其实乘法器非常适合流水操作,因此在实际应用中可以将乘法运算通过插入额外的寄存器将其分成多级流水来实现。即在关键路径上插入寄存器将关键路径拆分成两个更小的路径,以此来改善关键路径上的时序。

1.4.2 寄存器操作平衡
所谓寄存器平衡,从概念上讲,该技巧是将两个任意寄存器之间的逻辑重新平均分配,以达到最小化这两个寄存器之间的最大延时的目的。这个技巧通常用于关键路径和其相邻路径之间的逻辑高度不平衡的情况。其实寄存器平衡就是通过移动关键路径和其他相邻路径上的组合逻辑来提升设计的时序性能。
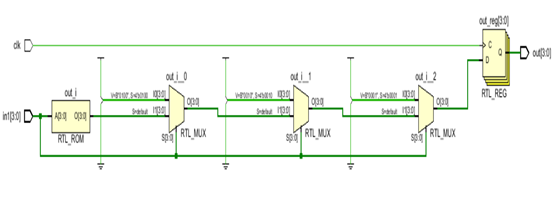
1.5 消除代码的优先级
所谓消除优先级即设计功能可以通过无优先级的方式实现,而对优先级有要求的功能模块无法使用该技巧,从而优化设计的速度。
always @ (posedge clk) begin if (in1 == 4'b0001) out <= 4'b0001; else if(in1 == 4'b0010) out <= 4'b0010; else if(in1 == 4'b0100) out <= 4'b0100; else if(in1 == 4'b1000) out <= 4'b1000; else out <= 4'b1001; end
always @ (posedge clk) begin case(in1) 4'b0001:out <= 4'b0001; 4'b0010:out <= 4'b0010; 4'b0100:out <= 4'b0100; 4'b1000:out <= 4'b1000; default:out <= 4'b1001; endcase end
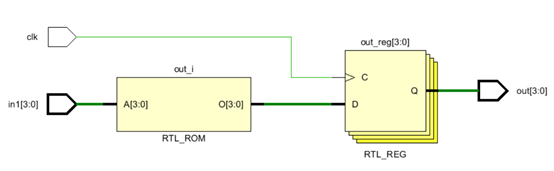
修改后的代码只是使用case语句替换if-else语句,这样进程中顺序执行的语句都改成了并行执行。对比可知,修改前的代码编译后需要经过4级逻辑,而修改后的仅需经过一级逻辑,从而提高了设计频率。

