
寒假自学进度报告1
今天我主要了解了spark的一些专业名词以及相关特点:
spark简介:
- 最初由美国加州伯克利大学的AMP实验室于2009年开发,是基于内存计算的大数据计算框架,可用于构建大型,低延迟的数据分析应用程序
- 2014年打破了hadoop保持的基准排序记录
Spark具有以下特点:
运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
容易使用:支持使用scala,java,python和R语言进行编程,可以通过spark shell进行交互式编程
通用性:Spark提供了完整而强大的技术栈,包括sql查询,流式计算、机器学习和图算法组件
运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可以运行于Amazon EC2等云环境中,并且可以访问HDFS.cassandra、hbase、hive等多种数据源。
Spark 运行框架
基本概念
RDD:是(Resillient Distributed Dataset)弹性分布式数据集的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模式。
DAG:是Directed Acyclis Graph(有向无环图)的简称,反应RDD之间的依赖关系
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task
Application:用户编写的Spark应用程序
Task:运行在Executor上的工作单元
Job:一个job包含多个RDD及作用于相应RDD上的各种操作
Stage:是Job的基本调度单位,一个job会分为多组task,每组task被称为stage,或者taskstage,代表一组关联的、相互之间没有shuffle依赖关系的任务组成的任务集。
架构设计
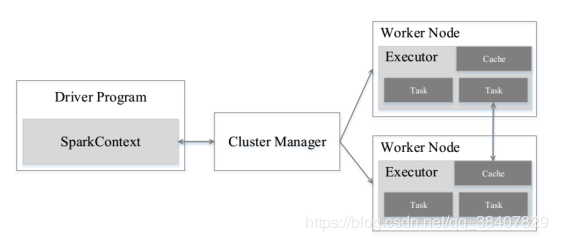
集群资源管理器可以是Spark自带的资源管理器,也可以是yarn或mesos等资源管理器。
与Hadoop Mapreduce计算框架相比,Spark的Executor有两个优点:
利用多线程执行具体的任务(H m采用进程模式),减少任务的启动开销
Executor中有一个BlockManager存储模块(类似KV系统),会将内存和磁盘共同作为存储设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就可以直接读该存储模块里的数据,而不需要读写到hdfs等文件系统,因此有效减少io开销;或者在交互式查询,预先将表缓存到该存储系统上,从而可以提高读写io性能
在 Spark 中,一个 Application 由一个 Driver 和若干个 Job 构成,一个 Job 由多个 Stage 构成,一个 Stage 由多个没有 Shuffle 关系的 Task 组成。当执 行一个 Application 时,Driver 会向集群管理器申请资源,启动 Executor,并向 Executor 发送 应用程序代码和文件,然后在 Executor 上执行 Task,运行结束后,执行结果会返回给 Driver, 或者写到 HDFS 或者其他数据库中。

Spark运行基本流程
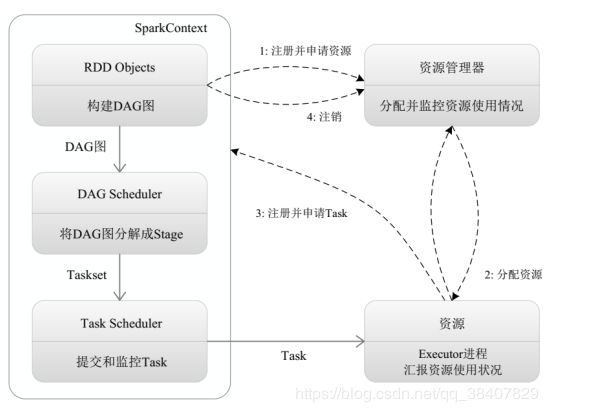
当一个Spark Application 被提交时,首先需要为这个应用构建起基本的运行环境,即由Driver创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向在资源管理器注册并申请运行Executor的资源
资源管理器为Executor分配资源,并启动Executor 进程,Executor运行情况将随着心跳发送到资源管理器上。
Sparkcontext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler进行解析,将DAG图分解成Stage,并且计算出各个stage之间的依赖关系,然后把一个个taskset提交给底层调度器taskScheduleer进行处理;Executor向sparkcontext申请task,taskScheduler将task发放给executor进行,同时。Sparkcontext将应用程序代码发放给executor
Task在Executor上运行,把执行结果反馈给taskexecutor。然后反馈给DAGScheduler,运行完毕后写入数据并释放资源
(1)每个 Application 都有自己专属的 Executor 进程,并且该进程在 Application 运行期 间一直驻留。Executor 进程以多线程的方式运行 Task; (2)Spark 运行过程与资源管理器无关,只要能够获取 Executor 进程并保持通信即可; (3)Task 采用了数据本地性和推测执行等优化机制。数据本地性是尽量将计算移到数据存储的地方
SPARK组件的应用前景:


