
第一次个人编程作业
https://github.com/83675299/test1/tree/main/031902505
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 5 | 5 |
| · Analysis | · 需求分析 (包括学习新技术) | 220 | 300 |
| · Design Spec | · 生成设计文档 | 5 | 5 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 30 | 120 |
| · Coding | · 具体编码 | 600 | 900 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 600 | 600 |
| Reporting | 报告 | 60 | 60 |
| · Test Repor | · 测试报告 | 10 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 1635 | 2165 |
二、计算模块接口
2.1 计算模块接口的设计与实现过程
2.1.1 概述
本次作业实现的是敏感词过滤的功能,我在最开始没有查阅资料前,是想遍历解决,但这样效率太低了,于是就通过查阅资料,发现DFA算法是一个不错的解题算法,然后又和同学讨论发现AC自动机是DFA的升级版,效率更高,最后决定使用AC自动机作为主要算法。然后这次作业还需要很多其他细节功能,也花费了很大的力气,最后还是没能全部完成,左右偏旁拆字未实现,首字母拼接只实现了一部分,其余功能都完成了。
Node节点:
class Node(object):
# value是该节点存的字,fail是指向的节点,next是子字典,word是目前建立的trie树
def __init__(self, value=None):
self.value = value
self.fail = None
self.next = dict()
self.word = ''
self.isend = False
2.1.2 项目设计结构
我设计了两个类和五个方法,类分为节点类和AC自动机类,方法分为文件读入,汉字转拼音,建树,实现fail指针和search搜索。先建树,然后在建树的基础上增加fail指针提升搜索效率,再通过AC自动机对文章进行搜索,这就是主要框架,其他的细节功能都加在了建树和搜索的方法里了。
2.1.3 AC自动机及search
AC自动机就是先通过给定的敏感词建立trie树,如下图:

再在trie树的的基础上增加fail指针,首字母的fail指针指向根节点,其他节点的fail指针是指向他父亲节点的fail指针指向的相同字母的子节点,像图中的'b'指向'b'。假如搜索的是abd,如果用DFA算法的话,在搜索ab后,发现'c'不是'd',就要对下一个字母重新搜索,而使用fail指针后,a的子节点b指向了root的子节点b,继续搜索就找到了d,这样效率会提高很多。
在search方法里先把读进来的字符串拆成字母或特殊字符,特殊字符就直接跳过;字母的话先变成小写,然后顺着trie树和fail指针搜索,看起来比较容易实现,但细节方面我经过多次修改,还是很费力气的。
2.1.4 汉字变成拼音等功能的实现
python里有个拼音的库,可以直接使用,树的每个节点就是用汉字拆成的字母来建成的,这样方便搜索。首字母的功能较难解决,如"fa lun gong","f l g"都是敏感词,那"gong"的两个g,在第一个g结束的话,后面"ong"就没有了,如果在第二个g结束的话,"f l g"就不能被识别出来,这两点我只能解决一点,还没有想到好的解决方法。最后文件读入和输出功能也走了一些弯路,用了不少时间,我采用的是python里的sys.argv[]。
2.2 计算模块接口部分的性能改进
2.2.1 用cprofile进行性能测试,如图所示
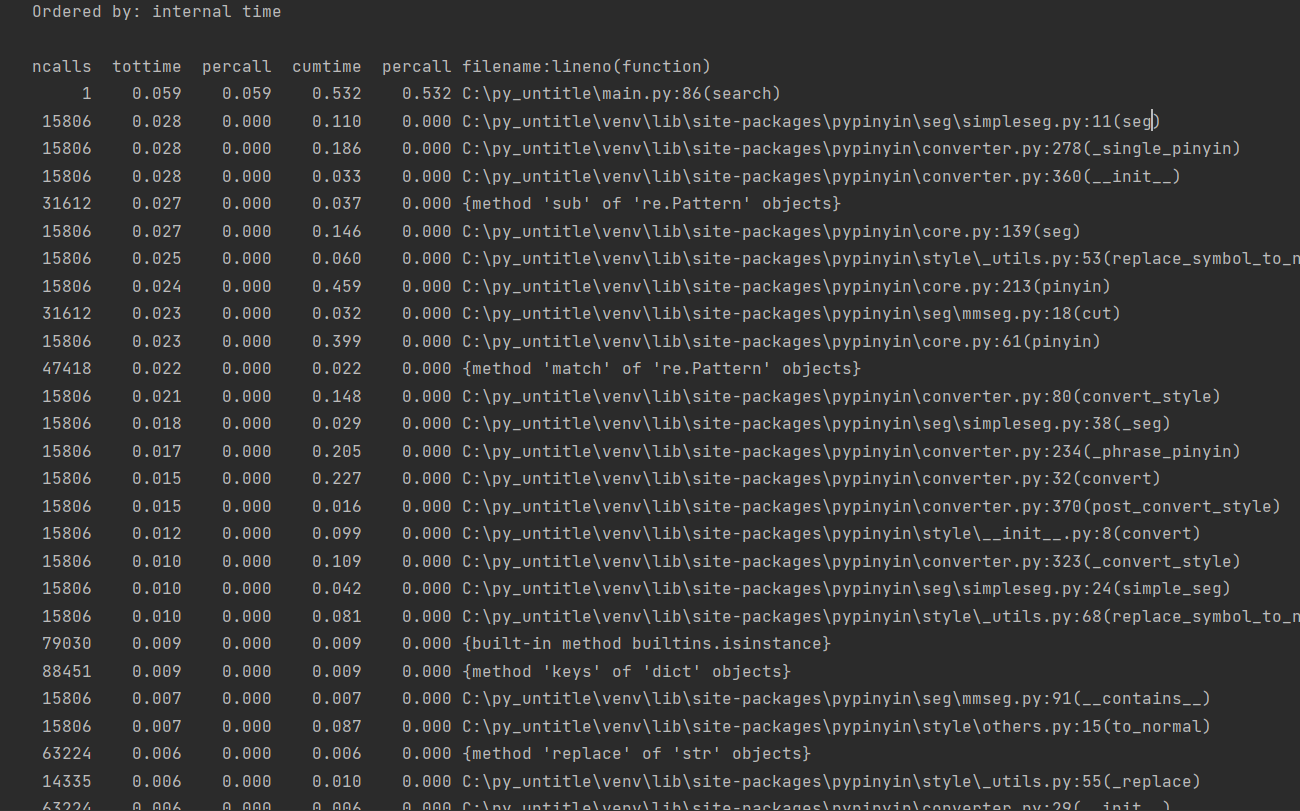
对性能影响较大的大部分都是pypinyin库,还有一部分是字典功能耗性能较大,要改进性能的话需要不使用pypinyin的库,而是通过汉字输入的原理来自己写功能,但会很麻烦,所以这次我没有选择改进。
2.2.2 耗时最大的函数
耗时最大的函数是search()函数,具体代码在git中,不在此占用篇幅了。
2.3 计算模块部分单元测试展示
def test4(self):
words = ['比赛', '大龙', '上单', '分钟']
org = ['在今天的比#$%%^赛中 RNG 1:3 LNG 告负,随着本场比,,,赛的落幕,',
'RNG2021年LPL夏季赛的征程就此结束。']
ac = AC(words)
ac.search(org, r'C:\Users\hqk\Desktop\rgzy\answer1.txt')
f1=read_file(r'C:\Users\hqk\Desktop\rgzy\answer1.txt')
f2=read_file(r'C:\Users\hqk\Desktop\rgzy\answer2.txt')
self.assertEqual(f1,f2)
测试了search()函数,看search()函数能否成功检测并输出敏感词检测结果。
这是单元测试的覆盖率。
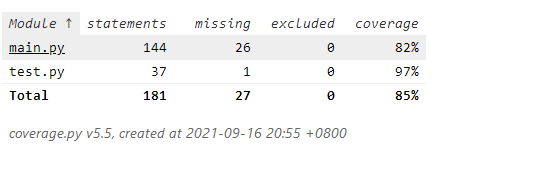
与参考答案的对比,实在能力有限,还有40个解不来了,缺的应该是左右拆字和部分首字母。

2.4 计算模块部分异常处理说明
2.4.1 命令行参数读取
def test1(self):
x = sys.argv[0]
y= sys.argv[1]
print(x+'\n'+y)
这个是我卡了好久的难题,可能本身这个读取参数并不难,但pycharm在哪里输入参数是个难点,我在python的控制台调试了半天都没弄好,最后在编辑配置里找到了输入参数的地方。
2.4.2 fail指针的使用
def test2(self):
root = tree_build(r'C:\Users\hqk\Desktop\rgzy\words.txt')
root = ac_build(root)
p = root
p = p.fail
if 'a' in p.next.keys():
print('True')
在我写完这行代码后:
p = p.fail
再打下这一行代码会报错:
if 'a' in p.next.keys():
print('True')
这是因为在实现fail指针的最后需要写:
root.fail = root
如果不加这一句话的话,系统不知道root的fail指向哪,就会提示编译错误。
三丶心得
我之前有学习过python的语言,但没有实战过,这次实战接触了pychram这个工具,还使用了pypinyin等第三方库,发现python确实是一门方便的语言,也学习了Cprofiler的使用和单元测试。在完成此次的作业中,遇到的难题真的是一道又一道,一个小点可能都要啃好几个小时,还好有同是柯老板班的同学在,大家都不是大佬(我是最菜的),一起讨论,把这些难题几乎都解决了,这次的作业,对我的影响应该是巨大的吧,让我了解了很多之前都从来没有了解过的代码知识,期待下一次作业带给我的提升。

这是一个ans.txt生成的词云,大概就这样。

