

Python爬取猫眼影评-----以《南方车站的聚会》为例
文本信息的获取
本文所使用的数据均为网络上的公开数据,可以通过Python网络爬虫获取,数据获取流程如下:
-
找到目标网站的URL:
在目标网站比较简单或者爬取网站的数量不大时,可以自行获取所有的URL。但当数量过大时,则可以查找URL的变化规律,利用爬虫对目标网站进行数据爬取,而猫眼平台的数据只有部分保留在网页中,需要进一步解析网页获取数据接口。
进入待爬取的网页网址,F12进入开发者模式,把浏览模式(响应式设计模式)更改为手机模式。效果图所示。
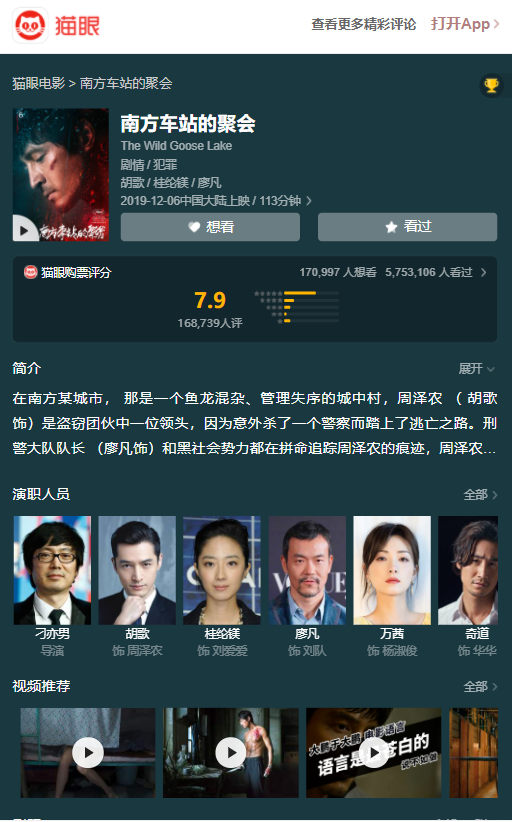
-
利用浏览器的响应式设计模式解析网页:
爬虫爬取数据通常会由于不同的网页源码结构从而选择不同的网页解析方法。利用爬虫爬取数据时需要先对目标网页结构进行查看,再择优选择最合适的网页工具去完成网页数据的解析。
同时,长时间或持续性的获取单一网站数据请求及其容易触发这些网站的反爬虫机制,因此利用爬虫获取数据时需要对Python爬虫做一个伪装,比如:加入请求头(user-agent),加入Cookie并存储在 request 中等等。
在响应式设计模式下寻找我们所需要的数据包,界面加载完成后进行下滑,选择我们要获取的数据,刷新使得继续加载,直到找到含有offset的信息条,点击进入后发现它的Response内容中包含本本文研究所需要的数据,数据的格式是json格式。网页数据效果如图所示。
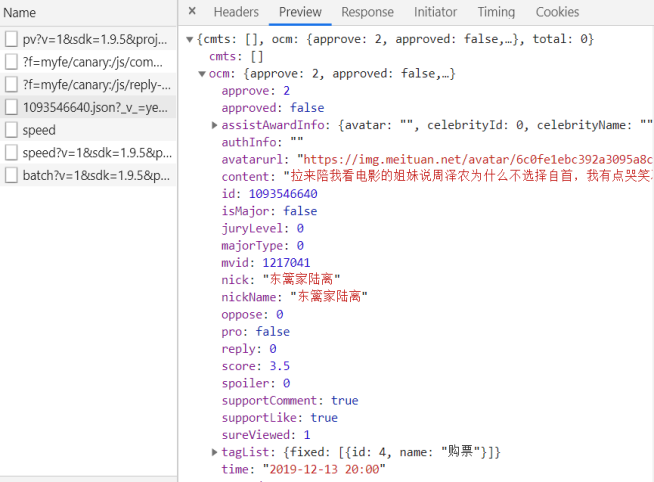
并在RequestURL中找到所需要的数据接口:
https://m.maoyan.com/mmdb/comments/movie/1217041.json?v=yes&offset=0&startTime=0 21%3A09%3A31
- 对数据接口进行多次调试,几次调试数据如表所示:
| 次数 | Offset | startTime |
|---|---|---|
| 第1次 | 0 | 0 |
| 第2次 | 15 | 2019-12-07 |
| 第3次 | 30 | 2019-12-07 |
| 第N-1次 | 15 | 2019-12-05 |
| 第N次 | 30 | 2019-12-05 |
分析对比上表中的各项数据变化,可以看出:offset是数据接口数据的偏移起始位置,每页有15条数据,startTime是数据接口的时间,其格式固定为:年-月-日(xxxx-yy-dd),另外接口最后的%2021%3A09%3A31是可以固定保持不变的。
由于猫眼有强大反爬虫机制,同时部分技术原因,本本文中无法获取全部的评论数据,最终只能汇总获取到40000余条记录,具体爬取代码见附录1。
通过以上所述技术最终得到的是电影《南方车站聚会》中40000余条评论。原始评论如表图所示:

数据集简介
数据集为电影的影评和部分信息数据。该数据集拥有40000余条用户的14项相关信息,该数据集的特征为英文,所对应的中文翻译如表特征翻译所示:
数据集主要特征介绍表
| 英文特征 | 中文特征 |
|---|---|
| Approve | 点赞数 |
| NickName | 用户名 |
| CityName | 城市 |
| Gender | 性别 |
| Content | 评论内容 |
| ID | 评论ID |
| UserLevel | 用户等级 |
| MovieId | 电影ID |
| Reply | 评论回复数量 |
| Score | 评分 |
| StartTime | 评分时间 |
| SureViewed | 推荐度 |
| UserId | 用户ID |
| FilmView | 电影的观点 |
关于爬取数据的代码
json可以看到的数据
json内容简单介绍
"approve":0, #点赞
"approved":false,
"assistAwardInfo":"avatar":"","celebrityId":0,"celebrityName":"","rank":0,"title":""},
"authInfo":"","avatarurl":"https://img.meituan.net/avatar/0abdd0bf24c6db28d6f5a672aad2b9d623674.jpg",
"cityName":"三河", #所在城市
"content":"胡歌演的 满分", #评论内容
"filmView":false,
"id":1109262057,
"isMajor":false,
"juryLevel":0,
"majorType":0,
"movieId":1217041, #电影标识符
"nick":"我旗恋真如稚", #用户名
"nickName":"恋真如稚", #昵称
"oppose":0,
"pro":false,
"reply":0, #回复
"score":5.0, #评分
"spoiler":0,
"startTime":"2020-11-01 23:20:15", #评分时间
"supportComment":true, #支持评论
"supportLike":true, #支持喜欢
"sureViewed":1, #推荐度
"tagList":{"fixed":[{"id":1,"name":"好评"},{"id":4,"name":"购票"}]},
"time":"2020-11-01 23:20",
"userId":932507117,
"userLevel":2, #用户等级
"videoDuration":0,
"vipInfo":"", #VIP所属
"vipType":0 #VIP类型
具体的执行代码
# coding=utf-8
from urllib import request
import json
import time
from datetime import datetime
from datetime import timedelta
import random
#选择性开启
#获取随机请求头
# from fake_useragent import UserAgent
#禁用服务器缓存
# ua = UserAgent(use_cache_server=False)
# 获取数据,根据url获取
def random_UA():
user_agent=[]
for i in range(20):
ua=UserAgent().random
user_agent.append(ua)
headers = {'User-Agent': random.choice(user_agent)}
return headers
def get_data(url):
# headers=random_UA()
# print(headers)
# print('\n\n\n')
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
'Accept':'*/* ',
#选择性开启
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control': 'max-age=0'
# 'Connection': 'keep-alive'
'Cookie': '自己找下自己的cookie',
'Host': 'm.maoyan.com'}
req = request.Request(url, headers=headers)
response = request.urlopen(req)
if response.getcode() == 200:
return response.read()
return None
def parse_data(html):
data = json.loads(html)['cmts'] # 将str转换为json
comments = []
for item in data:
comment = {
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else '',
'content': item['content'].replace('\n', ' ', 10),
'score': item['score'],
'startTime': item['startTime'],
'gender':item['gender'] if 'gender' in item else ''
}
comments.append(comment)
return comments
def save_to_csv():
start_time = '2019-12-12 18:18:25' # 获取时间,从什么时候开始获取
# start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间,从当前时间向前获取
end_time = '2019-12-12 00:00:00'
while start_time > end_time:
url = 'https://m.maoyan.com/mmdb/comments/movie/1217041.json?_v_=yes&offset=0&startTime=' + start_time.replace(' ', '%20')
print('--------------------------------\n\n\n')
print(url)
print('-------------------------------------\n\n\n')
html = None
try:
html = get_data(url)
except Exception as e:
html = get_data(url)
else:
time.sleep(random.randint(2, 5))
comments = parse_data(html)
# print(comments)
start_time = comments[14]['startTime'] # 获得末尾评论的时间
start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1) # 转换为datetime类型,减1秒,避免获取到重复数据
start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S') # 转换为str
for item in comments:
with open('comments.csv', 'a', encoding='utf-8') as f:
f.write(str(item['id'])+'\t'+item['nickName'] + '\t' + item['cityName'] + '\t' + item['content'] + '\t' + str(item['score'])+ '\t' +str(item['gender']) +'\t' + item['startTime'] + '\n')
if __name__ == '__main__':
save_to_csv()
爬着玩,所以没考虑多线程干活

