【kettle & postgresql】temporary file size exceeds temp_file_limit解决办法
使用kettle从postgresql拉取数据时,可能会因为数据量过大,出现“ERROR: temporary file size exceeds temp_file_limit(16777216kB)”的报错
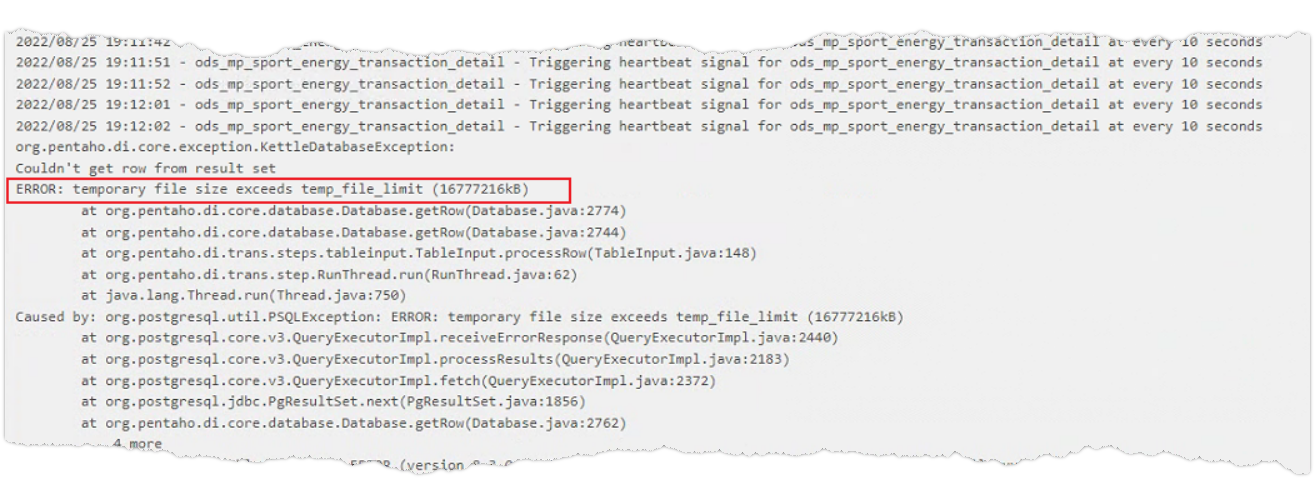
这个临时文件大小限制是postgresql的参数temp_file_limit设置的(参考:PostgreSQL配置参数temp_file_limit_wx5bcd90b347f01的技术博客_51CTO博客),其参数含义是
指定一个进程可以占用的最大的磁盘空间。该磁盘空间可以用于temporary files(sort及hash使用)或者持有cursor的storage file。试图超过该限制的transaction会被取消。
在没有权限修改此参数的情况下,如果从pg取数的SQL只是简单的select ... from ... where 语句,我们可以通过设置【文本文件输出】中的“分拆...每一行”设置每个文件放多少行数据,解决临时文件过大的问题。
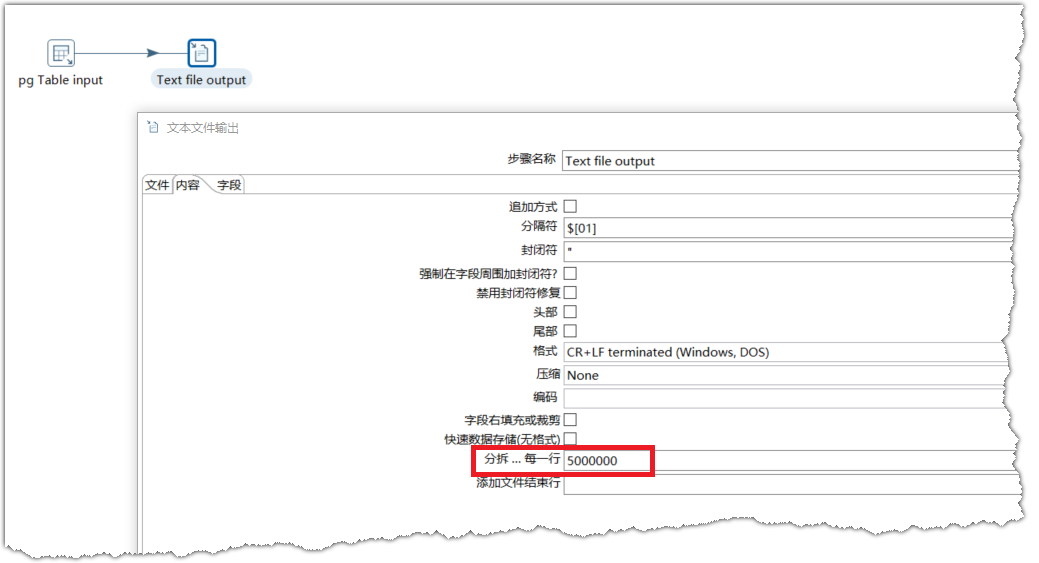
为何此种方式能生效,可参考
数据库游标及其优点 - 苏晓敏 - 博客园 (cnblogs.com)
(89条消息) mysql的查询原理_数据库SQL SELECT查询的工作原理_曹阳明的博客-CSDN博客
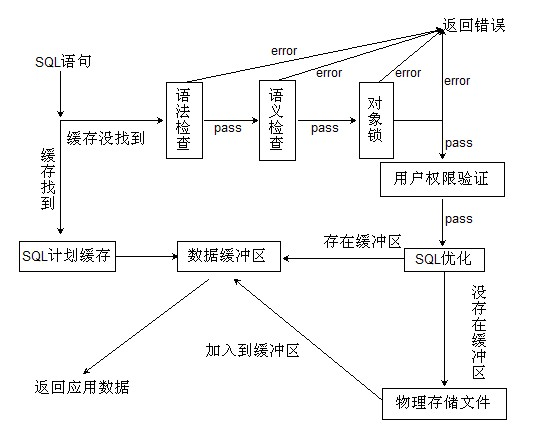
问题的关键点在生成的【物理存储文件】,通过设置每个文件的存储行数,即将结果进行了切分后,物理存储文件(temp_file_limit)没有超过限制,那么有很大一个可能是这种情况下kettle对select添加了LIMIT offset,row_count的处理
SELECT * FROM xxx LIMIT OFFSET,ROW_COUNT
(待求证这种方式是否会进行执行计划优化)
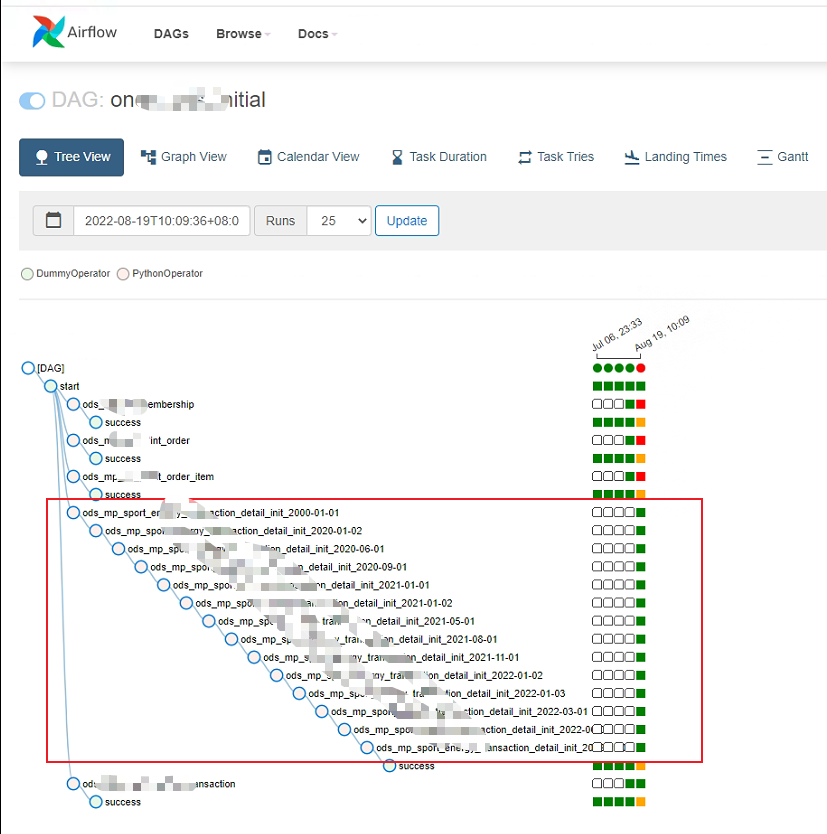
但是当取数的SQL中存在join,那此方法就不管用了,要取得有join操作的sql的结果,必须获取到整个sql的结果然后取偏移的数据,但是输出结果的时候就超出了临时文件大小限制,任务就失败了,解决办法就是增加where条件,或者缩小where条件取数的数量,使得结果不超出限制。比如原来时间范围是1年,现在改为1个月,或者采用更精确的做法:根据数据表每行数据占用的存储空间来估计最大的行数,从而设置where条件。
下图为这种处理方式的一个示例,airflow任务会调用kettle取数脚本,通过将取数时间分段拆分成多个任务(缩小where条件的能获取到的数据量),解决了全量取数时数据量超出pg临时文件大小限制的问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?