
工作常用mysql命令以及函数
1.表中添加字段ddl
alter table tb_item_group add column tb_place_id varchar(20) comment'场馆表id';
alter table 表名 add column 新增字段名 类型 cimment '注释';
2.修改表字段ddl
ALTER TABLE tuser CHANGE name user_name varchar(32) DEFAULT NULL COMMENT '姓名';
# ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型;
3行转列
数据图

比如想将uuid >3的role_name转化为一列
SELECT GROUP_CONCAT(role_name SEPARATOR ',') namex FROM mooc_film_actor_t WHERE UUID>2
SEPARATOR ',' 值中间加入逗号

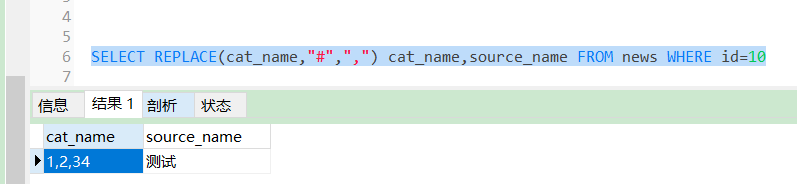
4字符串替换函数 REPLACE
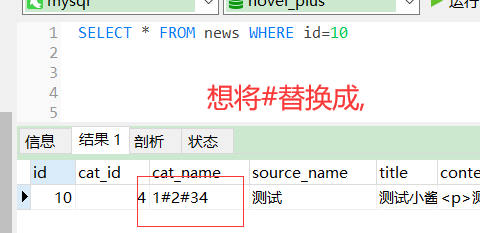
SELECT REPLACE(cat_name,"#",",") cat_name,source_name FROM news WHERE id=10
5 TRIM 函数
完整格式:TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
简化格式:TRIM([remstr FROM] str)
mysql> SELECT TRIM(' aaa ');
-> 'aaa'
mysql> SELECT TRIM(LEADING '.' FROM '...aaa...'); //删除指定的首字符 .
-> 'aaa...'
mysql> SELECT TRIM(LEADING '.' FROM '..a.aaa...'); //只能删除首字符,第一个a后面的.不能删除
-> 'a.aaa...'
mysql> SELECT TRIM(TRAILING '.' FROM 'aaa...'); //删除指定的尾字符 .
-> 'aaa'
mysql> SELECT TRIM(BOTH '.' FROM '...aaa...'); //删除指定的首尾字符 .
-> 'bar'
6 FIND_IN_SET函数
CREATE TABLE `tb_test` ( `id` int(8) NOT NULL auto_increment, `name` varchar(255) NOT NULL, `list` varchar(255) NOT NULL, PRIMARY KEY (`id`) ); INSERT INTO `tb_test` VALUES (1, 'name', '石头,狮子,椅子'); INSERT INTO `tb_test` VALUES (2, 'name2', '大石头,狮子,桌子'); INSERT INTO `tb_test` VALUES (3, 'name3', '白色,黑色,椅子');
比如,我们想获取 list中有石头的数据
SELECT id,name,list from tb_test WHERE '石头' IN(list); --没有数据

用like查询 ,发现【大石头】的这列也查了出来,但是我们只想要石头
SELECT id,name,list from tb_test WHERE list like '%石头%';

用FIND_IN_SET 函数 ,就查出来了
SELECT id,name,list from tb_test WHERE FIND_IN_SET('石头',list);

mysql中 like和find_in_set区别:
mysql字符串函数 find_in_set(str1,str2)函数是返回str2中str1所在的位置索引,str2必须以","分割开。
like是广泛的模糊匹配,字符串中没有分隔符,Find_IN_SET 是精确匹配,字段值以英文”,”分隔,Find_IN_SET查询的结果要小于like查询的结果。
8:删除重复数据
-- 删除重复数据(根据手机号判断是否重复) DELETE FROM user WHERE id IN ( SELECT tempout.id FROM ( SELECT user.id AS id FROM `user` ,(SELECT mobile,MAX(id) maxId FROM `user` GROUP BY mobile HAVING COUNT(id) >= 2) tempt WHERE user.mobile = tempt.mobile AND user.id < tempt.maxId ) tempout)
9:索引相关
9.1:索引创建
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
在创建索引时,可以规定索引能否包含重复值。如果不包含,则索引应该创建为PRIMARY KEY或UNIQUE索引。对于单列惟一性索引,这保证单列不包含重复的值。对于多列惟一性索引,保证多个值的组合不重复。
PRIMARY KEY索引和UNIQUE索引非常类似。事实上,PRIMARY KEY索引仅是一个具有名称PRIMARY的UNIQUE索引。这表示一个表只能包含一个PRIMARY KEY,因为一个表中不可能具有两个同名的索引。
9.2 索引删除
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
9.3 查看索引
show index from tbName;
show keys from tbName;
Table:表的名称。
Non_unique:如果索引不能包括重复词,则为0。如果可以,则为1。
Key_name:索引的名称。
Seq_in_index:索引中的列序列号,从1开始。
Column_name:列名称。
Collation:列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
Cardinality:索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
Sub_part:如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
Packed:指示关键字如何被压缩。如果没有被压缩,则为NULL。
Null:如果列含有NULL,则含有YES。如果没有,则该列含有NO。
Index_type: 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
9.4索引使用场景
表的主关键字
表的字段唯一约束
直接条件查询的字段
在SQL中用于条件约束的字段 :select * from user_info where mobile=’1533333333’
查询中与其它表关联的字段
查询中排序的字段
查询中统计或分组统计的字段
9.5索引不考虑场景
表记录太少
经常插入、删除、修改的表
数据重复且分布平均的表字段:假如一个表有10万行记录,有一个字段只有A和B两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
经常和主字段一块查询但主字段索引值比较多的表字段
