软工作业2:个人项目-论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade21-12/homework/13014 |
| 这个作业的目标 | 学习PSP,完成论文查重代码项目并分析 |
1.GitHub仓库地址:https://github.com/13ugYellow/13ugYellow
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 890 | |
| Development | 开发 | 420 | 480 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 40 |
| Coding | 具体编码 | 60 | 60 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 30 | 50 |
| Test Report | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 890 | 980 |
3.计算模块接口的设计与实现过程
读取文本——>通过re库的sub去除标点符号获取纯净文本并通过jieba的搜索引擎模式拆分——>用simhash算法计算simhash值——>用simhash值计算海明距离——>用海明距离计相似度即重复
1)接口:
2)算法:
利用了jieba、re、Simhash、memory_profiler和line_profiler五个库对算法进行构造。首先是通过re库中的sub函数对标点符号进行删除,得到纯文字的字符串,然后用jieba的lcut_for_search函数上述字符串进行分词,得到分词列表。再通过分词列表,使用simhash中的Simhash函数计算两篇文章分词列表的simhash值,再计算两者的海明距离,通过海明距离以及公式1-(海明距离/64)得到重复度,其中64是Simhash中的特征向量的长度。性能分析方面通过memory_profiler和line_profiler分别对内存和时间的占用进行分析。
3)算法关键及独到之处:
关键在于使用re库的sub方法和jieba库的搜索引擎分词方法对文章进行处理,以及用simhash算法的特征向量来计算文章之间的重复度。独到之处是re库的sub一句代码就将整篇文章的标点符号进行了去除,大大降低了代码的复杂度。
4.计算模块接口部分的性能改进
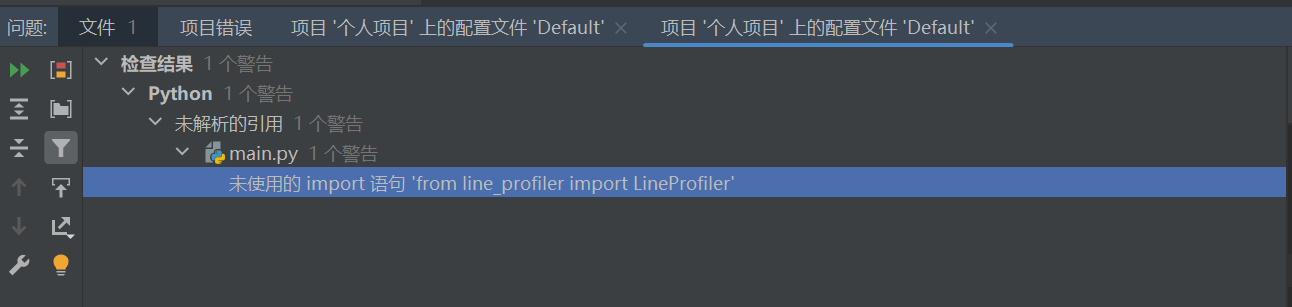
使用pycharm自带的代码审查插件,图中警告是由于line_profiler和memory_profiler两个无法同时分析,除此之外的警告已经全部清除。
1)时间:
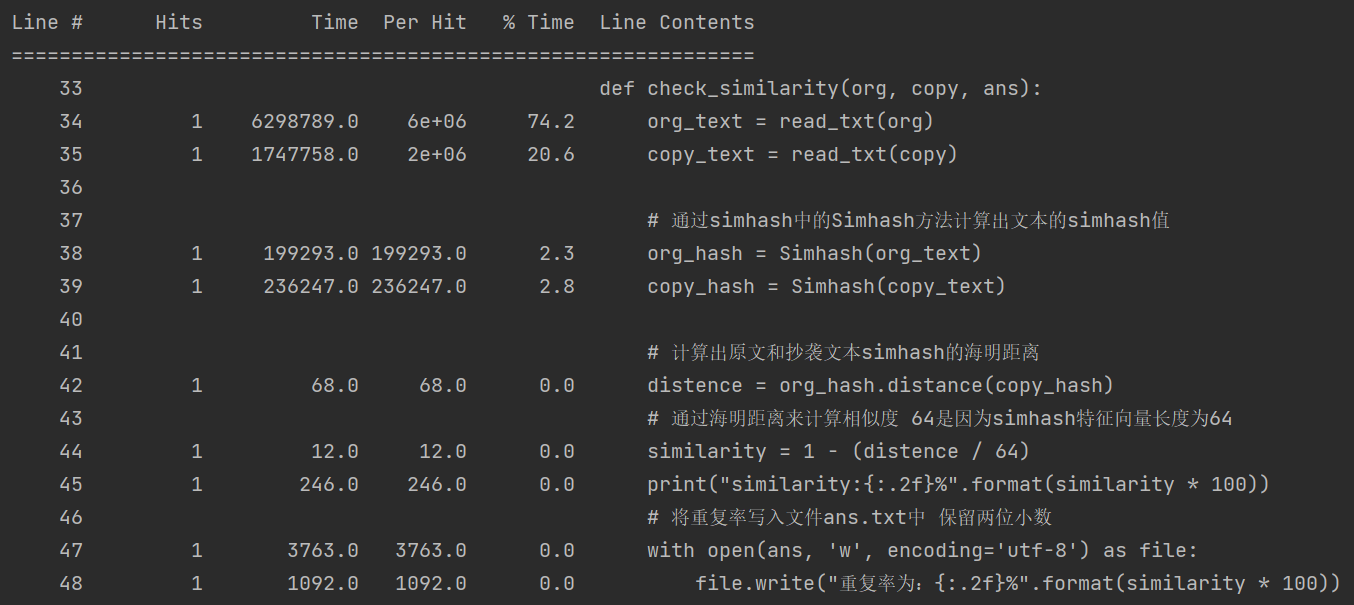
从入口函数时间分析看到在调用read_text()方法时间占比最大,再转而观察read_text()方法的时间占比图:
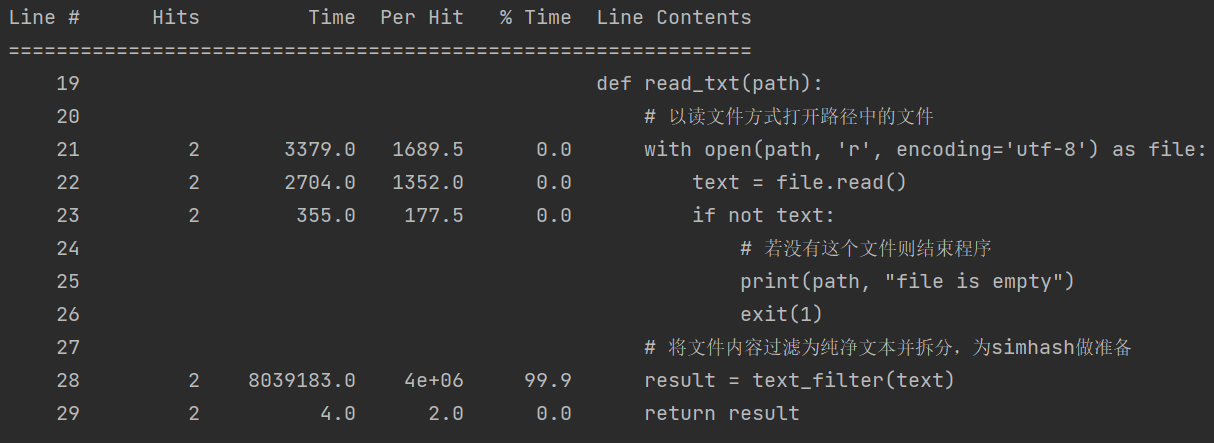
可以看到在调用text_filter()方法时时间占比最大,转而观察text_filter()方法的时间占比图:
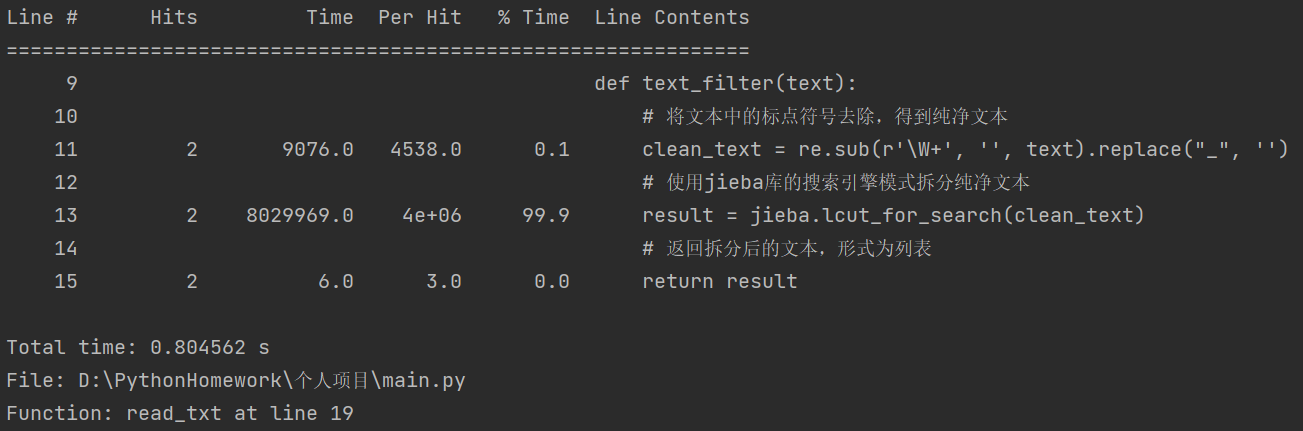
可以看到在调用jieba.lcut_for_search()方法时时间占比最大,说明分词操作是消耗的时间最大的。
2)内存:
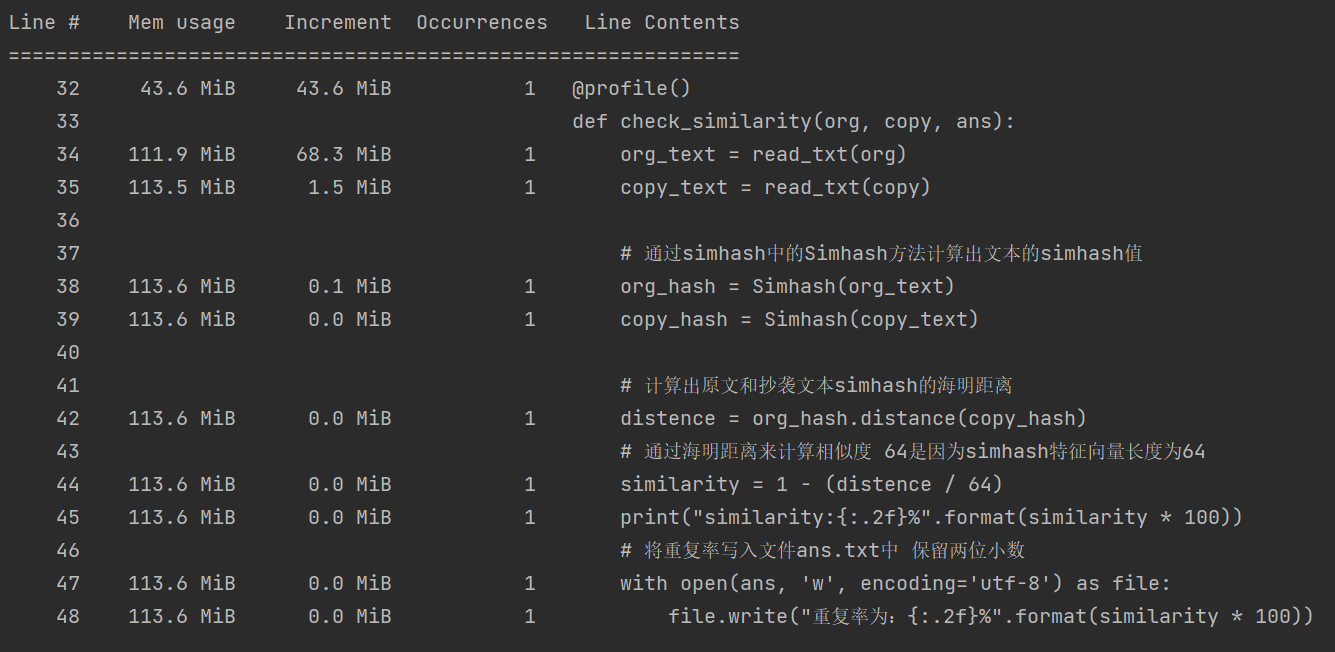
观察到入口函数内存占比在调用read_text()方法时内存增长了68.3MiB,转而观察read_text()中的内存占比:
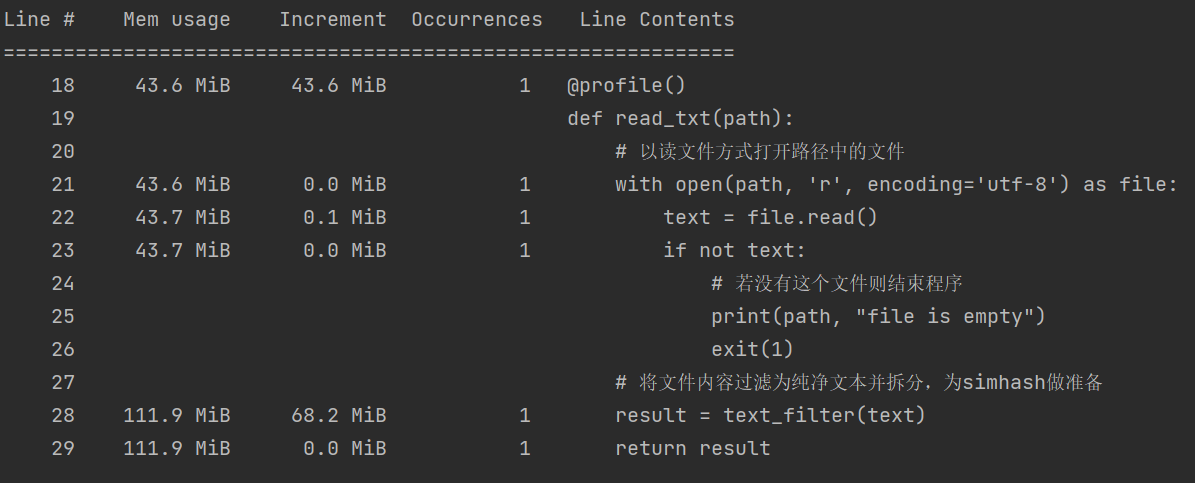
可以看到在调用text_filter()方法时内存增加了68.2MiB,转而观察text_filter()方法的内存占比图:
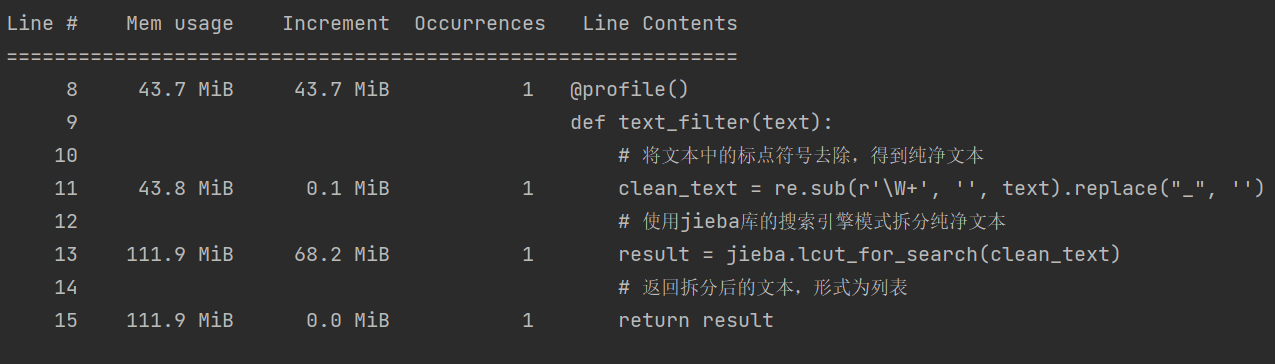
可以看到在调用jieba.lcut_for_search()方法时内存增加了68.2MiB,说明分词操作消耗的内存是最大的。
综上,可以得知调用了jieba.lcut_for_search()方法的text_filter()函数是小号最大的,其代码如下:
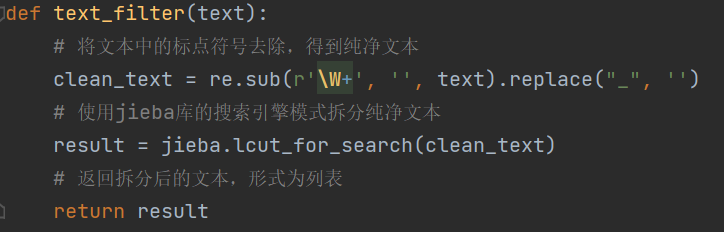
另外,由于分词操作是必须的操作,所以性能暂时无法改进。
5.计算模块部分单元测试展示
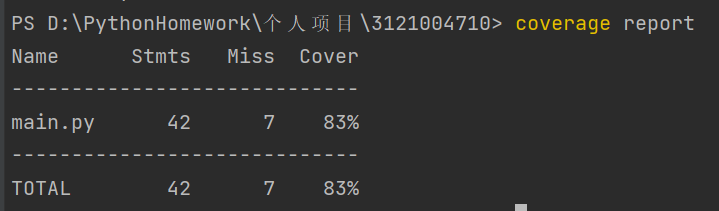
正常运行代码覆盖率为83%,是由于代码中有一部分为对异常的处理,删去后可以提高代码的覆盖率但是降低了代码的健壮性,故保留。
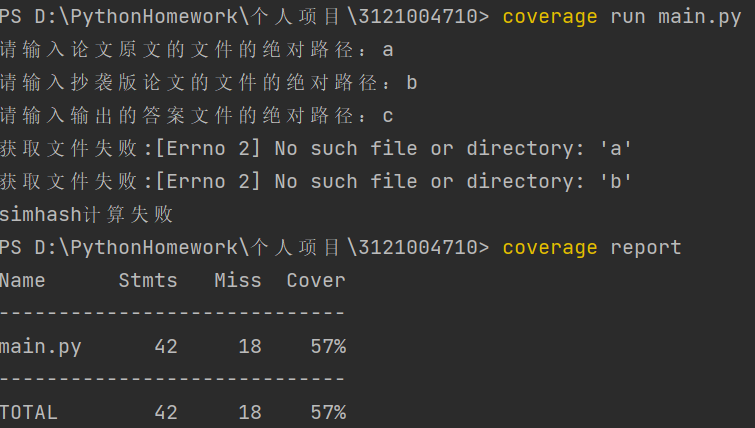
出现异常代码的覆盖率降低到了57%,测试到了上述的对异常处理的部分。
6.计算模块部分异常处理说明
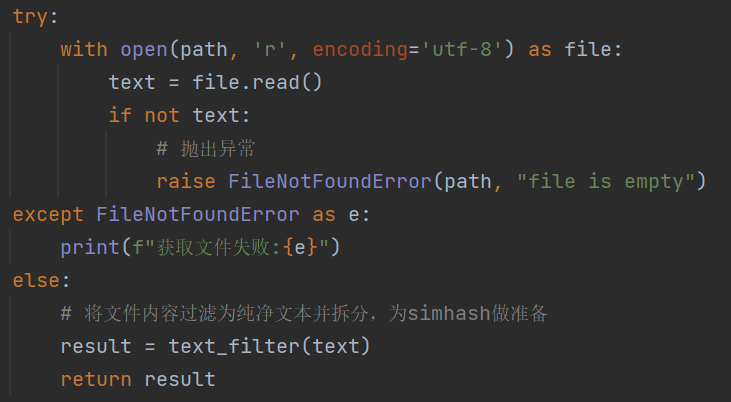
文件读取异常,一般是由于文件路径名输入错误引发,将其抛出。
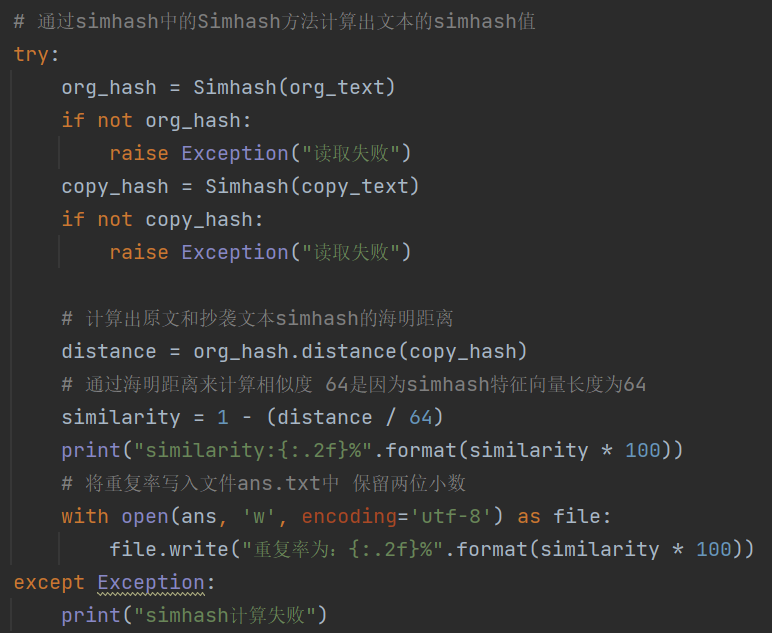
由于文件读取异常引发的simhash值计算错误,处理方式是将其抛出。
7.测试
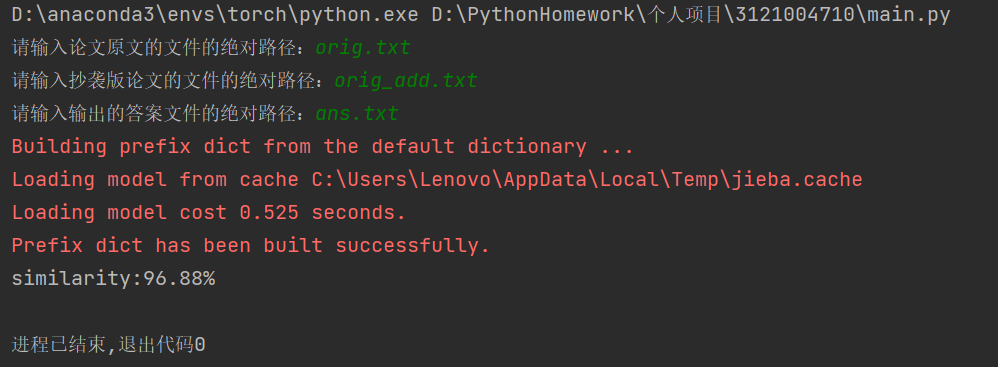
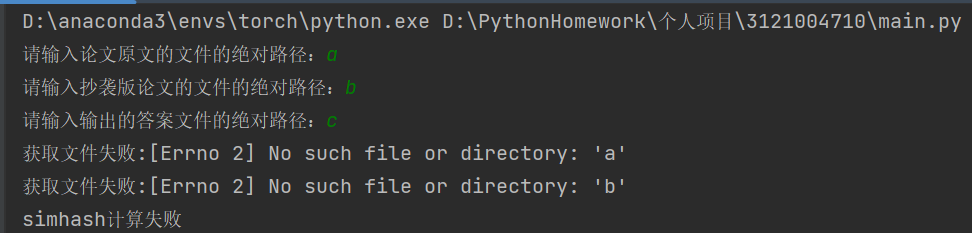
文件路径不正确时由于将异常抛出使得代码运行可以正常结束。
PS:Github中的代码commit了两次以上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号