使用Freemarker模板+docx4j进行docx文档与pdf文档导出
Freemarker介绍
Freemarker 是一款模板引擎,是一种基于模版生成静态文件的通用 工具,它是为Java程序员提供的一个开发包,或者说是一个类库,它不是面向最终用户的,而是为程序员提供了一款可以嵌入他们开发产品的应用程序。
Freemarker 生成静态页面,首先需要使用自己定义的模板页面,这个模板页面可以是最最普通的html,也可以是嵌套freemarker中的 取值表达式, 标签或者自定义标签等等,然后后台读取这个模板页面,解析其中的标签完成相对应的操作, 然后采用键值对的方式传递参数替换模板中的的取值表达式,做完之后 根据配置的路径生成一个新的html页面, 以达到静态化访问的目的。
建立Freemarker word模板
创建一个word文档,输入内容,需要进行替换用${}替换,然后另存为word xml文档类型

将xml文件导入项目,可根据具体业务逻辑修改Freemarker标签
eg:
<#list users as user>
<w:p>
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:t>姓名:${user.name}</w:t>
</w:r>
</w:p>
<w:p>
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:t>性别:${user.gender}</w:t>
</w:r>
</w:p>
<w:p>
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:t>年龄:${user.age}</w:t>
</w:r>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
</w:p>
<#if user_has_next>
<w:p>
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
</w:pPr>
<w:bookmarkStart w:id="0" w:name="_GoBack"/>
<w:bookmarkEnd w:id="0"/>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia" w:ascii="宋体" w:hAnsi="宋体" w:eastAsia="宋体" w:cs="宋体"/>
<w:lang w:val="en-US" w:eastAsia="zh-CN"/>
</w:rPr>
<w:br w:type="page"/>
</w:r>
</w:p>
</#if>
</#list>
<w:sectPr>
<w:pgSz w:w="11906" w:h="16838"/>
<w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="851" w:footer="992"
w:gutter="0"/>
<w:cols w:space="425" w:num="1"/>
<w:docGrid w:type="lines" w:linePitch="312" w:charSpace="0"/>
</w:sectPr>
导包
<!-- freemarker,生成 doc -->
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.30</version>
</dependency>
<!-- docx4j,doc转pdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.docx4j/docx4j -->
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.0.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-export-fo</artifactId>
<version>8.1.6</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-core</artifactId>
<version>8.1.6</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-JAXB-ReferenceImpl</artifactId>
<version>8.1.6</version>
</dependency>
实现
目录结构:
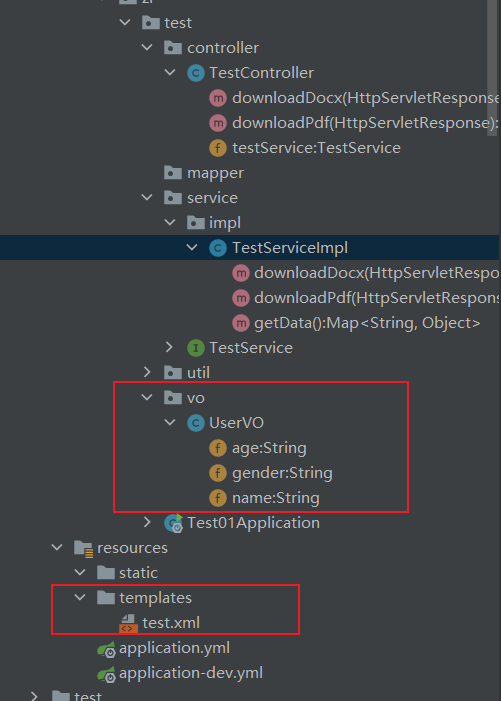
工具类
package com.zl.util;
import freemarker.template.Configuration;
import freemarker.template.Template;
import org.springframework.core.io.ByteArrayResource;
import org.springframework.core.io.InputStreamSource;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Map;
/**
* @program: world
* @description: doc工具类
*/
public class DocUtils {
public static void saveWord(String filePath, Map<String,Object> dataMap) throws IOException {
Configuration configuration = new Configuration(Configuration.VERSION_2_3_30);
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(DocUtils.class, "/");
Template template = configuration.getTemplate("templates/template.xml");
InputStreamSource streamSource = createWord(template, dataMap);
InputStream inputStream = streamSource.getInputStream();
FileOutputStream outputStream = new FileOutputStream(filePath);
byte[] bytes = new byte[1024];
while ((inputStream.read(bytes)) != -1) {
outputStream.write(bytes);// 写入数据
}
inputStream.close();
outputStream.close();
}
public static InputStreamSource createWord(Template template, Map<String, Object> dataMap) {
StringWriter out = null;
Writer writer = null;
try {
out = new StringWriter();
writer = new BufferedWriter(out, 1024);
template.process(dataMap, writer);
return new ByteArrayResource(out.toString().getBytes(StandardCharsets.UTF_8));
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
writer.close();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
}
代码:
package com.zl.test.service.impl;
import com.zl.test.service.TestService;
import com.zl.test.util.DocUtils;
import com.zl.test.vo.UserVO;
import freemarker.template.Configuration;
import freemarker.template.Template;
import org.docx4j.Docx4J;
import org.docx4j.convert.out.FOSettings;
import org.docx4j.fonts.IdentityPlusMapper;
import org.docx4j.fonts.Mapper;
import org.docx4j.fonts.PhysicalFonts;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.springframework.core.io.ByteArrayResource;
import org.springframework.core.io.InputStreamSource;
import org.springframework.stereotype.Service;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class TestServiceImpl implements TestService {
/**
* 生成docx文档
*/
@Override
public void downloadDocx(HttpServletResponse response) throws Exception {
Configuration configuration = new Configuration(Configuration.VERSION_2_3_30);
// 防止中文乱码
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(DocUtils.class, "/");
Template template = configuration.getTemplate("templates/test.xml");
StringWriter sw = new StringWriter();
Writer writer = new BufferedWriter(sw, 1024);
template.process(getData(), writer);
InputStreamSource streamSource = new ByteArrayResource(sw.toString().getBytes(StandardCharsets.UTF_8));
InputStream inputStream = streamSource.getInputStream();
String fileName = "测试文档.docx";
response.setCharacterEncoding("utf-8");
fileName = URLEncoder.encode(fileName, "UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
OutputStream out = response.getOutputStream();
byte[] bytes = new byte[1024];
while ((inputStream.read(bytes)) != -1) {
out.write(bytes);// 写入数据
}
out.flush();
out.close();
inputStream.close();
}
/**
* 生成pdf文档
*/
@Override
public void downloadPdf(HttpServletResponse response) throws Exception {
Configuration configuration = new Configuration(Configuration.VERSION_2_3_30);
// 防止中文乱码
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(DocUtils.class, "/");
Template template = configuration.getTemplate("templates/test.xml");
StringWriter sw = new StringWriter();
Writer writer = new BufferedWriter(sw, 1024);
template.process(getData(), writer);
InputStreamSource streamSource = new ByteArrayResource(sw.toString().getBytes(StandardCharsets.UTF_8));
InputStream inputStream = streamSource.getInputStream();
WordprocessingMLPackage mlPackage = WordprocessingMLPackage.load(inputStream);
// 设置字体,解决pdf生成不显示中文
Mapper fontMapper = new IdentityPlusMapper();
fontMapper.put("宋体", PhysicalFonts.get("SimSun"));
fontMapper.put("宋体 (中文正文)", PhysicalFonts.get("SimSun"));
fontMapper.put("隶书", PhysicalFonts.get("LiSu"));
fontMapper.put("微软雅黑",PhysicalFonts.get("Microsoft Yahei"));
fontMapper.put("黑体",PhysicalFonts.get("SimHei"));
fontMapper.put("楷体",PhysicalFonts.get("KaiTi"));
fontMapper.put("新宋体",PhysicalFonts.get("NSimSun"));
fontMapper.put("华文行楷", PhysicalFonts.get("STXingkai"));
fontMapper.put("华文仿宋", PhysicalFonts.get("STFangsong"));
fontMapper.put("宋体扩展",PhysicalFonts.get("simsun-extB"));
fontMapper.put("仿宋",PhysicalFonts.get("FangSong"));
fontMapper.put("仿宋_GB2312",PhysicalFonts.get("FangSong_GB2312"));
fontMapper.put("幼圆",PhysicalFonts.get("YouYuan"));
fontMapper.put("华文宋体",PhysicalFonts.get("STSong"));
fontMapper.put("华文中宋",PhysicalFonts.get("STZhongsong"));
// 设置默认字体
RFonts rFonts= Context.getWmlObjectFactory().createRFonts();
rFonts.setAsciiTheme(null);
rFonts.setAscii("SimSun");
mlPackage.getMainDocumentPart().getPropertyResolver().getDocumentDefaultRPr().setRFonts(rFonts);
mlPackage.setFontMapper(fontMapper);
String fileName = "测试文档.pdf";
response.setCharacterEncoding("utf-8");
fileName = URLEncoder.encode(fileName, "UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
OutputStream out = response.getOutputStream();
// docx转pdf
FOSettings foSettings = Docx4J.createFOSettings();
foSettings.setWmlPackage(mlPackage);
Docx4J.toFO(foSettings, out, Docx4J.FLAG_EXPORT_PREFER_XSL);
out.flush();
out.close();
}
/**
* 导出的数据
*/
private Map<String, Object> getData() {
List<UserVO> list = new ArrayList<>(0);
for (int i = 0; i < 3; i++) {
UserVO user = new UserVO();
user.setName("zhangsan" + i);
user.setAge(20 + i);
user.setGender("男");
list.add(user);
}
Map<String, Object> dataMap = new HashMap<>(0);
dataMap.put("users", list);
return dataMap;
}
}
使用列表循环时注意:模板中的users传入的是
集合对象,user一定要是实体对象,不能是map对象,具体看getData()方法
生成结果
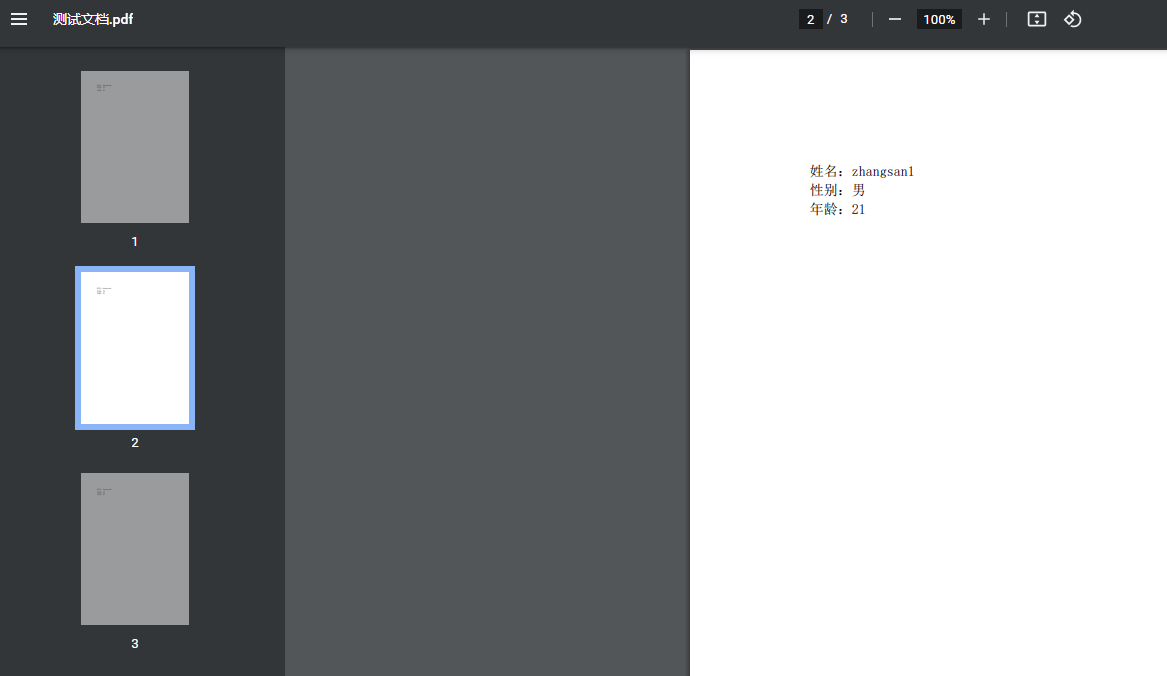
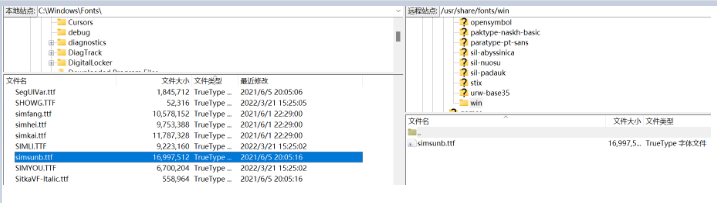
linux安装windows字体
在生成pdf时,windows字体在linux上可能没有,需要将windows字体安装
Windows 系统字体所在目录:C:\Windows\Fonts
Linux 系统字体所在目录:/usr/share/fonts
- 在 /usr/share/fonts 目录下新建 win目录,将需要用到的字体传过去
- 刷新配置
将解压后的字体文件夹复制到 /usr/share/fonts 目录下,然后运行 fc-cache -fv 命令以更新字体缓存。
- 出现
fc-cache -bash: fc-cache: command not found解决
# 1.使mkfontscale和mkfontdir命令正常运行
yum -y install mkfontscale
# 2.使fc-cache命令正常运行。如果提示 fc-cache: command not found
yum -y install fontconfig
# 3.把文件放进/usr/share/fonts
# 4.在fonts路径运行
mkfontscale
mkfontdir
fc-cache -fv
- 使用
fc-list查看字体列表
Freemarker部分语法
具体需要使用的语法百度即可
list
<#list nameList as name>
${name}
</#list>
等价与
for (String name : nameList) {
System.out.println(name);
}
if
<#if (name=="zhangsan")>
我的名字是${name}
</#if>
等价于
if("zhangsan".equals(name)){
System.out.println("我的名字是zhangsan");
}
include
这个导入标签非常好用,特别是页面的重用。
<#include “default.html”/>
if...elseif...else
<#if (name=="zhangsan")>
我的名字是zhangsan
<#elseif (name=="lisi")> <#–注意这里没有返回而是在最后面–>
我的名字是lisi
<#else>
我的名字是wangwu
</#if>
等价于
if("zhangsan".equals(name)){
System.out.println("我的名字是zhangsan");
}else if("lisi".equals(name)){
System.out.println("我的名字是lisi");
}else{
我的名字是wangwu
}
map
<#list usersMap?keys as key>
key------${key}:value------${usersMap[key]!("null")}
</#list>
fremarker 不支持null, 可以用!来代替为空的值。
也可以给一个默认值,value-----${usersMap[key]?default(“null”)}
还可以在输出前判断是否为null,<#if usersMap[key]??></#if>
对null处理
freemarker不支持null,如果值为null会报错。
1、过滤不显示
Hello ${name!} 在属性后面加感叹号即可过滤null和空字符串
<#if age??>无年龄值<#/if> ??判断是否有值
${age!'0'} 如果age为null,默认给'0'
2、提供默认值
${student1.user!"zhangsan"} 如果user为null,默认给'zhangsan'
3、判断是否存在值
${stduent.user?if_exists} 是否存在值
时间处理
<#if data.time??>${data.time?time}</#if>
或
<#if data.time!=null>${data.time?string('yyyy-MM-dd hh:mm:ss')}</#if>
三元运算符
${(user.name == 'zhangsan')?string('zhangsan','lisi')}
list处理第一个、最后一个元素
显示索引 _index 获取下标
<#list nameList as name>
索引:${name_index},值:${name}
</#list>
变量名字+
_index,就可以表示当前循环到第几项
对第一个元素处理,使用_index=0
<#if name_index=0>...</#if>
判断是否为最后一项,使用_has_next
eg:有时候需要循环的最后一项去除逗号
<#list nameList as name>
${name}<#if name_has_next>,</#if>
</#list>
输出结果:zhangsan,lisi,wangwu
break退出循环
<#list nameList as name>
${name}
<#if name=="lisi"><#break></#break>
</#list>
word xml 标签含义
<w:p> <!--表示一个段落-->
<w:val > <!--表示一个值-->
<w:r> <!--表示一个样式串,指明它包括的文本的显示样式,表示一个特定的文本格式-->
<w:t> <!--表示真正的文本内容-->
<w:rPr> <!--是<w:r>标签内的标签,对Run文本属性进行修饰-->
<w:pPr> <!--是<w:p>标签内的标签,对Paragraph文本属性进行修饰-->
<w:rFronts> <!--字体-->
<w:hdr> <!--页眉-->
<w:ftr> <!--页脚-->
<w:drawing > <!--图片-->
<wp:extent> <!--绘图对象大小-->
<wp:effectExtent > <!--嵌入图形的效果-->
<wp:inline > <!--内嵌绘图对象,dist(T,B,L,R)距离文本上下左右的距离-->
<w:noProof > <!--不检查拼写和语法错误-->
<w:docPr> <!--表示文档属性-->
<w:rsidR> <!--指定惟一一个标识符,用来跟踪编辑在修订时表行标识,全部段落和段落中的内容都应该拥有相同的属性值,若是出现差别,那么表示这个段落在后面的编辑中被修改。-->
<w:r> <!--表示关系,段落中以相连续的中文或英文字符字符串,做为开始和结束。目的就是要把一个段落中的中英文字符区分开来。 -->
<w:ind> <!--w:pPr元素的子元素,跟w:pStyle并列,ind表明缩进状况:有几个属性值:①firstLine(首行缩进)②left(左缩进)③当left和firstLine同时出现时表明下面的元素有两种属性首行和下面其余行都是有属性的④hanging(悬挂)-->
<w:hint> <!--字体的类型,w:rFonts的子元素,属性值eastAsia表面上的意思是“东亚”,指代“中日韩CJK”类型。-->
<w:bCs> <!--复合字体的加粗-->
<w:bookmarkStart> <!--书签开始-->
<w:bookmarkEnd> <!--书签结束-->
<w:lastRenderedPageBreak > <!--页面进行分页的标记,是w:r的一个属性,表示此段字符串是一页中的最后一个字符串。-->
<w:smartTag > <!--智能标记-->
<w:attr > <!--自定义XML属性-->
<w:b w:val=”on”> <!--表示该格式串种的文本为粗体-->
<w:jc w:val="right"/> <!--表示对齐方式-->
<w:sz w:val="40"/> <!--表示字号大小-->
<w:szCs w:val="40"/> <!---->
<w:t xml:space="preserve"> <!--保持空格,若是没有这内容的话,文本的先后空格将会被Word忽略-->
<w:spacing w:line="600" w:lineRule="auto"/> <!--设置行距,要进行运算,要用数字除以240,如此处为600/240=2.5倍行距-->
<w:jc w:val="center"/> <!-- 这句话表示段落对齐方式 -->
<!-- 设置了页的宽,高,和页的各边距。各项的值均是英寸乘1440得出 -->
<w:body>
<w:sectPr>
<w:pgSz w:w="12240" w:h="15840"/>
<w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="720" w:footer="720" w:gutter="0"/>
</w:sectPr>
</w:body>
<!--页眉和页脚-->
<w:sectPr wsp:rsidR="002C452C">
<w:hdr w:type="odd" >
<w:p>
<w:pPr>
<w:pStyle w:val="Header"/>
</w:pPr>
<w:r>
<w:t>这是页眉</w:t>
</w:r>
</w:p>
</w:hdr>
<w:ftr w:type="odd">
<w:p>
<w:pPr>
<w:pStyle w:val="Footer"/>
</w:pPr>
<w:r>
<w:t>这是页脚</w:t>
</w:r>
</w:p>
</w:ftr>
</w:sectPr>
<!--表示文档的视图是“print”,视图比例100%-->
<w:docPr>
<w:view w:val="print"/><w:zoom w:percent="100"/>
</w:docPr>
内容为表格时

如图:每个内容,如 姓名:zhangyanan 以<w:p></w:p>为单位,即
<w:p>……姓名:zhangyanan……</w:p>
每个单元格,如

以<w:tc></w:tc>为单位即
<w:tc>……<w:p>……姓名:zhangyanan……</w:p></w:tc>
<w:tc>……<w:p>……性别:nan……</w:p></w:tc>
每一行,如

以<w:tr><w:tc><w:p></w:p></w:tc></w:tr>为单位即
<w:tr><w:tc>……<w:p>……姓名:zhangyanan……</w:p></w:tc><w:tc>……<w:p>……性别:nan……</w:p></w:tc></w:tr>
<w:tr><w:tc>……<w:p>……出生日期:1953-08-15……</w:p></w:tc><w:tc>……<w:p>……职业:程序猿……</w:p></w:tc></w:tr>
整个表格以
<w:tbl>
<w:tr><w:tc>……<w:p>……姓名:zhangyanan……</w:p></w:tc><w:tc>……<w:p>……性别:nan……</w:p></w:tc></w:tr>
<w:tr><w:tc>……<w:p>……出生日期:1953-08-15……</w:p></w:tc><w:tc>……<w:p>……职业:程序猿……</w:p></w:tc></w:tr>
</w:tbl>
为单位
参考链接:
http://www.javashuo.com/article/p-uewatieg-gq.html
https://www.cnblogs.com/panchanggui/p/9342246.html
