
人工智能简述
前些天公司办了个培训,是关于人工智能(以下简称AI)和数据分析的,有个同事去了,正好有兴趣,正好有机会,真好。
昨天有初中同学突然说想要了解下AI和大数据,但是对这些没有什么概念,所以让他去知乎上搜:如何自学人工智能,看完之后再聊。他想学AI的理由是这个东西最近很火,
目前手头上还没有这方面的科普的,也是自己想描述一下自己理解的这些东西,所以就写了这一篇“科普”,正文开始:
其实相关的还有数据挖掘,连同上面这几个东西呢,都是方法,或者说手段(中性词),逐一解释下吧:
1、python
是一种编程语言,类似于java、C,就是用来干活的工具,是做下面这些事的基础,与AI相关的还有lua,数据分析的话还有R,有些模型甚至能用js写,
2、大数据
现在已经很多都落地了,也不只是个概念了。大数据简单点说就是很多很多数据,而这个“很多”的衡量标准呢,可以是维度、可以是数据量,你能想象4维空间和1亿条数据么?举个大数据的栗子就是每天的视频监控数据和你每天刷抖音逛淘宝等动作所产生的日志数据,这些都是维度和量级都非常大的数据。你能想象256甚至上千的维度么?然后1TB的数据呢?1PB呢?但是这中间有用的数据可能只有1G,怎么找到这1G数据呢?就是下面这个,
3、数据分析
这貌似是一个很大的概念,平时看看报表找规律也是数据分析,用SPSS也是数据分析,感觉这个动作虽然操作方式有很多种,但是目的只有一个:寻找有价值的信息或者数据的内在联系。举个栗子来说的话,就是发现“啤酒尿布”规律的经典的关联规则分析,还有很多APP都在用的“推荐算法”——系统自动通过你过往的操作行为来分析“你喜欢的”信息。那么分析完数据,也知道数据的内在联系和相关的信息了,那么获得的这些东西要怎么用呢,那就是下面这个了。
4、建模
比如通过什么建模工具构造的模型,或者算法。一般商业建模都是通过用手头的数据建立某种模型,将这个模型的输出用于商业运作,这样就可以创造商业价值了。还有算法,其实也差不多吧,只不过就是用了某些数学上通用的方法来建模,比如机器学习、深度学习、迁移学习、强化学习和集成学习等等吧。举个栗子来说的话,前面说过的那个“推荐算法”就是建模的典型应用了,此外还有图像分析——AI智能美颜和自动抠图、语言文本方面的机器翻译、游戏领域的alphago zero 和医学领域各种影像中病灶的识别。这些呢都是通过对数据的分析建模获得某种模型,然后将模型应用于新的数据得到的结果。
为什么之前没听说过机器学习?深度学习?
其实,机器学习的方法一直都在研究,只是研究成果没有那么明显地冲击人们的生活,所以可能感觉不到,比如早期的“深蓝”、“更深的蓝”和专家系统。而最近的深度学习方面发展空前,取得了瞩目的成果,所以就“火”起来了。而这个发展是得益于GPU的性能提高。小规模数据用于机器学习方法的话,一般CPU很快就能算出来,但是面对大规模的并行计算的话CPU就有些吃力了,而用来渲染游戏的GPU却有一种神奇的力量,能用来做大规模并行计算,如果你看过《三体》的话应该看到过在某个纪元中三体星人用好多人来模拟门电路,实现CPU的运行过程,但总会有个计算瓶颈。业界流传,面对深度学习模型,GPU的训练效率是CPU的六倍。举个栗子吧,毕业前训练的最后一个模型是自然语言处理方面的,数据量大约在百万级,其中每个组里包含大约五六句子,平均每个句子二十词吧,当时是在一块1080ti上训练一个深度学习模型(融合了注意力机制的LSTM模型),差不多要运行三天左右才能训练完成。
人工智能的关键
解释下这个“训练模型”是什么意思。以决策树模型来说,就像一颗倒着的大树,树根在上。
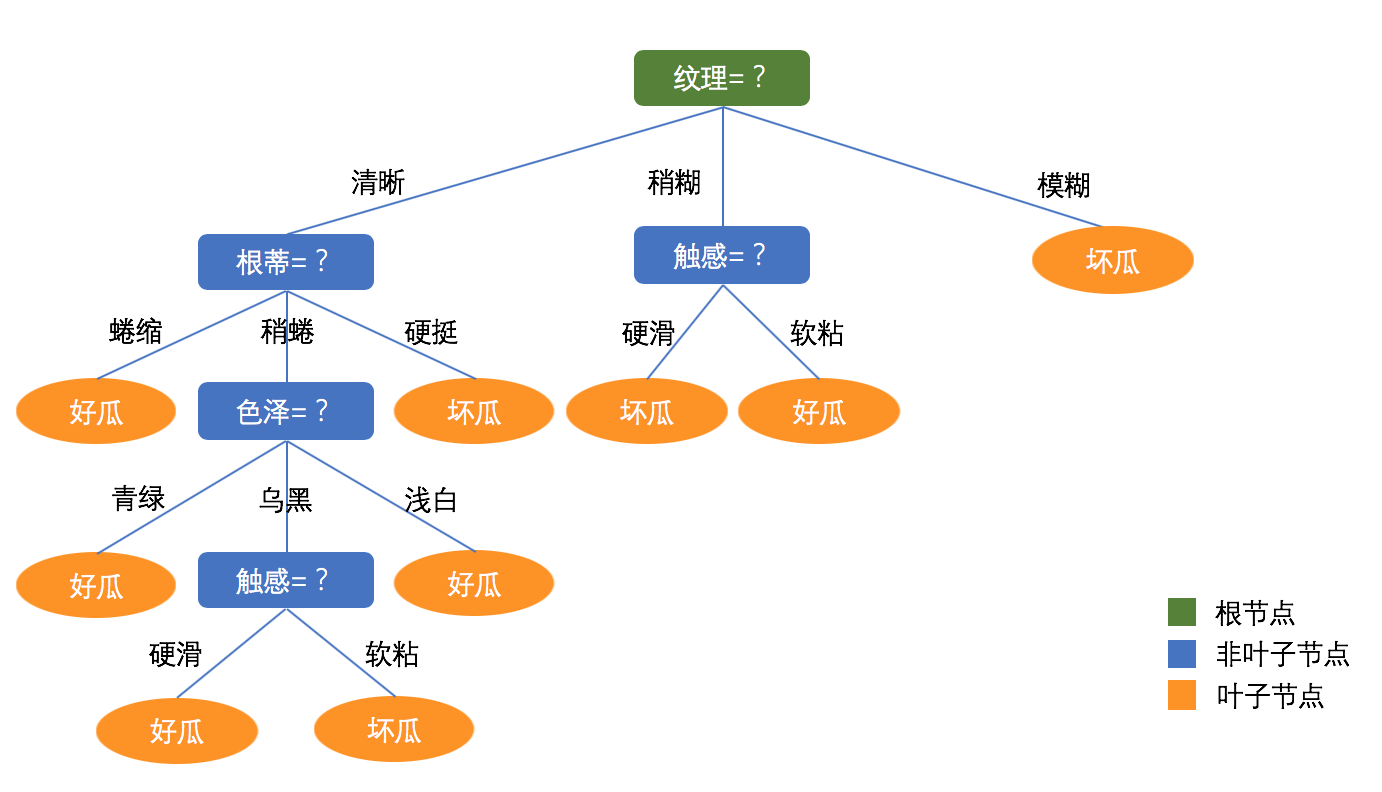
当一个数据进来之后会一路向下,在所有分叉的地方都会有一个人告诉你该向左走还是向右走。这样你就按照他们的指点找到你想要的答案了。那么这些人是怎么知道该让你往哪个方西走呢,这就是需要训练的了。不同的模型有着不同的训练方法,决策树这种也许可以直接指定各个节点的参数就能得到想要的模型,但是类似感知机、神经网络和深度学习模型这些的,需要经过数以千万次的监督性训练,也就是你告诉他每一次跑到最后的结果是正确还是错误,误差多大,他就知道该怎么调整参数了。简单提一句,有些模型你是知道参数数量的,比如决策树或者聚类,都可以提起知道要训练哪几个参数,但是到了神经网络就不行了,因为神经网络会自动训练参数,你有时候都不知道有多少参数,甚至拿到参数也是不可解释的,当然可视化也就更艰难了。曾经有团队训练的网络参数达到了上亿个。当然也正得益于此,神经网络获得了强大的拟合能力,所以能“进化出”你想要的模型。
有了模型就可以完成你想做的事了,比如训练模型玩星际争霸,打dota,实际应用的比如自动驾驶,自动翻译,YouTube的自动添加字幕,B站的弹幕自动跳过视频中的人物,自动导航,最最接地气的——自动美颜,也就是美颜相机。
想做AI但是又不知如何下手,那就简单了解下学术界是怎么做的吧
学术界研究算法的基本步骤
①想想自己想干什么:无人驾驶?看图说话?自动问答?生物信息?路径规划?
②看看别人做了什么:看论文文献,看看别人在用什么方法去解决这个问题的,解决到什么程度了,
③动动脑子做点什么:自己想办法去解决这个问题,而且要在某种程度上要比别人方法的效果更好, (只要取得了更好的效果了,就可以发文昭告天下了,如果是工业界那还得继续:)
④用用心思得点什么:也就是让模型落地,思考怎么用模型去为团队盈利,
当然工业界也可以直接用现有的模型,整体步骤就成了找模型-用模型了,
此外
当然做数据分析和人工智能需要的不仅仅是上面这些,其中还有数据预处理,有些工作中称为“特征工程”,还有算法的理论分析和实验验证,这样才会发现模型哪里不够好才能进一步优化,做的过程中这些工作都会自然展开的。现在已经有很多的模型了,比如基本的RNN,CNN,LSTM等等,也有了很多策略,比如迁移学习、强化学习这些,有兴趣可以了解下。
还有几句
或许你也想到了,这么多分析,还有算法的研究,就离不开数学了,当然还有线性代数、运筹学等学科的影子,甚至还有控制论的思想。 另外,前些天看到某大佬试图复现某顶会论文中的所有模型,但能复现比率只有60%。一般认为一个学术模型要经历大约5至6年的验证论证,才会进入实际生产。
python、AI和大数据这些只是知识,而公司需要的是能力,是能创造利润的能力。要正确认识这一点。
就这些吧,个人能力有限,若文中出现错误,还望指正。
了解更多欢迎关注公众号:


