Python 正则表达式
flags 编译标志位
正则表达式工作流程
正则表达式工作流程如下图1:
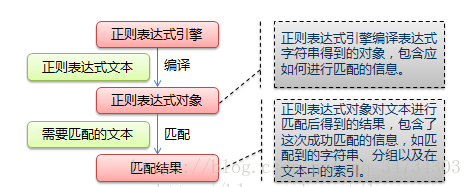
首先语言中的正则表达式引擎会将用户使用的正则表达式文本编程成正则表达式对象,然后依次拿出表达式对象和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,将会有相关语法的解决办法,在后期学习中慢慢摸索,都容易理解。
Python中flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,对多行数据进行匹配等。常用的flags如下:
标志 含义
re.S(DOTALL) 匹配包括换行在内的所有字符
re.I(IGNORECASE) 使匹配对大小写不敏感
re.L(LOCALE) 做本地化识别(locale-aware)匹配,法语等
re.M(MULTILINE) 多行匹配,影响^和$
re.X(VERBOSE) 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解
re.U 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
(1)re.I 使匹配对大小写不敏感,如下:
# re.I 的学习,忽略大小写
S1 = 'CoN' #定义字符串i1
S2 = 'www.xiao.con' #定义字符串i2
#print(re.search('CoN','www.xiao.con').group()) #区分大小写的子组输出,报有错
print(re.search(S1,S2,re.I).group()) #不区分大小写的子组输出
结果: 输出 con
备注:输出字符的大小以被匹配的字符串的大小写为主,如S2为’www.xiao.CON’,则输出的为:CON
(2)re.M 使用^ 和 $ 符号,实现多行多行匹配。如将所有行的末尾字符串输出得:
# re.M 的学习,将所有行的尾字母或者首部输出
S3 = '''I am girl
you are boy
we are friends
''' #定义初始字符串
print(re.findall(r"\w+$",S3,re.M)) #输出S3的每行最后一个字符串
输出为:['girl','boy','friends']
(3)re.S匹配包括换行在内的所有字符。如下:
s1 = '''jduedhhelloworld:
11630
passgrthgdg
''' #初始字符串,有换行所以用三引号
b = re.findall('hello(.*?)pass',s1) #findal返回字符串中某个正则表达式模式全部的非重复出现的情况,不包含换行,返回列表
c = re.findall('hello(.*?)pass',s1,re.S) #包含换行
print('b is',b) #输出B匹配的结果
print('c is',c) #输出C,包行匹配输出的结果
结果输出对比为:

总结:flags 编译标志位就相当于一些特殊的指令,就如上面提的比如是否忽略大小写。并不是必须使用,不用的时候定义flags=0即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号