刘浩毅---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息, 将采集到的评论信息做成词云图 |
| 作业源代码 | https://github.com/1362776157/first-personal-work |
| 学号 | 211811129 |
| 1.流程 | |
| 步骤 | 简易做法 |
| ---------- | --------- |
| 数据采集 | 使用正则提取 |
| 词频统计 | 利用jieba进行分析 |
| 绘制词云图 | 使用worldcloud库进行绘制 |
| 2.具体步骤 | |
| (1)数据采集 | |
根据《在一起》的所有评论页如图所示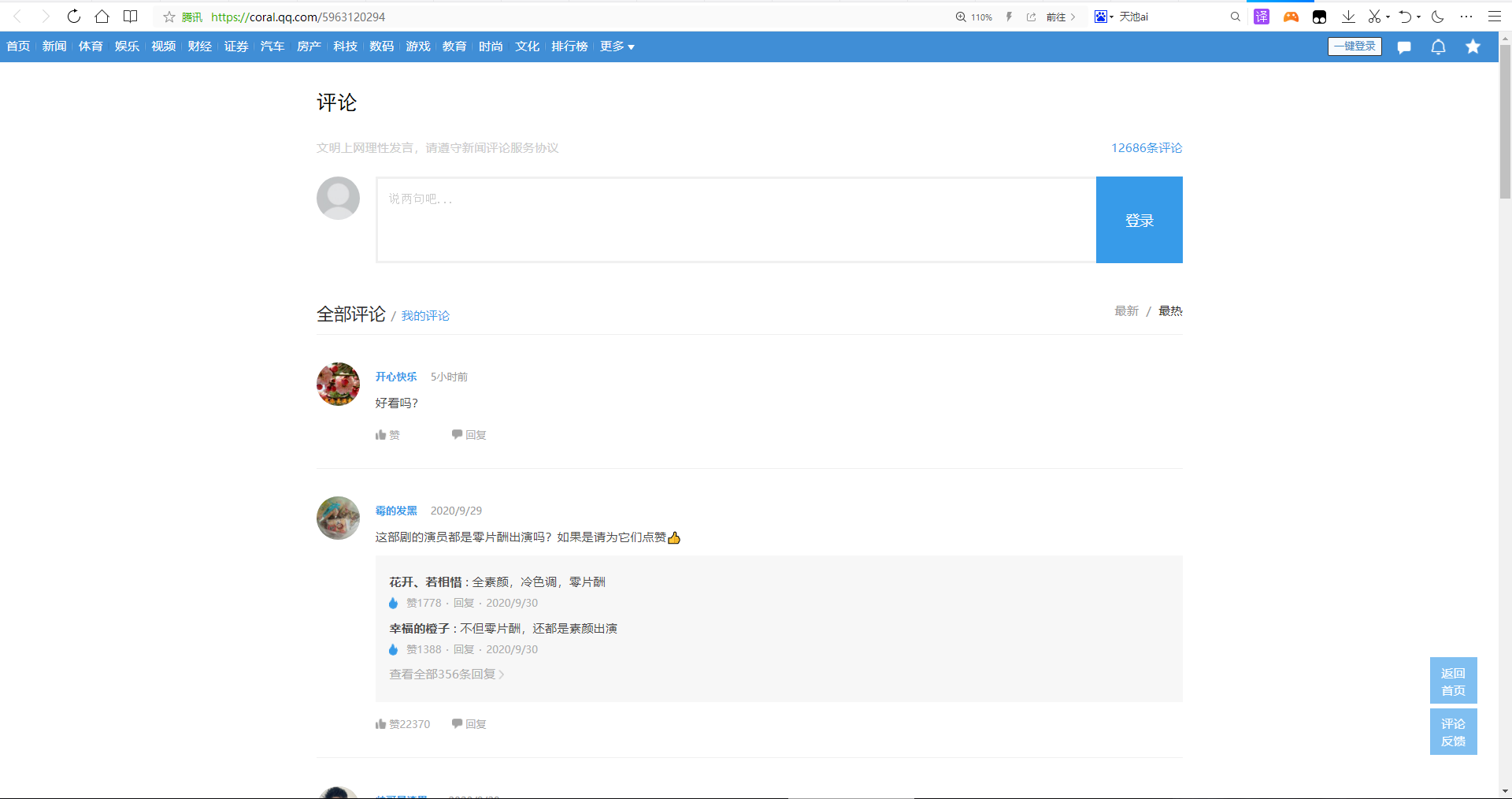 |
|
| 按下F12刷新并点击底部的加载更多可以发现 | |
 |
|
| 这时打开这些js发现评论就在content里面 | |
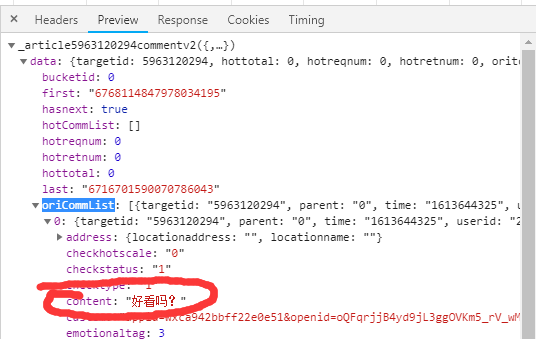 |
|
| 多次点开底部的加载更多可以发现该request url的地址是有规律的, | |
这是第一页 |
这是第二页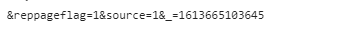
所以尾部的那一串数字加一就是下一页面的url,其次会发现url的cursor变化多端,将第一页评论的url打印出来查询第二页的sursor数值发现下一页的sursor数值为当前页最后一名用户的id
此为当前页的最后一名用户id
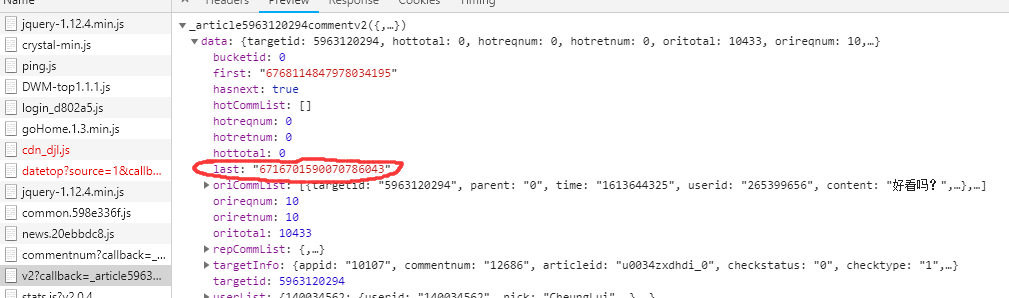
此为下一页的url中的cursor值
发现这些规律之后便开始使用正则爬取
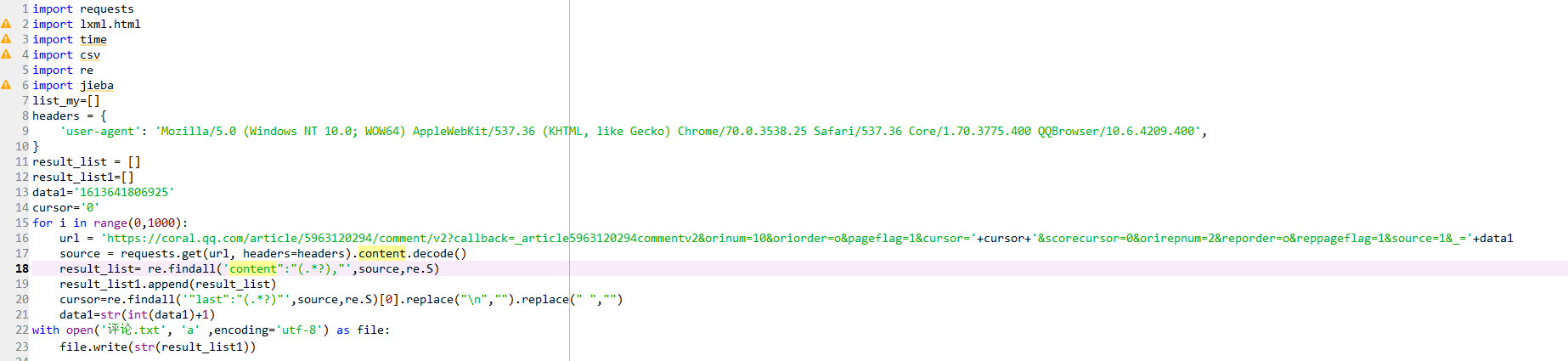
将爬取的数据保存至"评论.txt"文件中
(2)词频统计
第13行的代码为统计出现频率前100的词语(该数值只为测试用)

完整代码
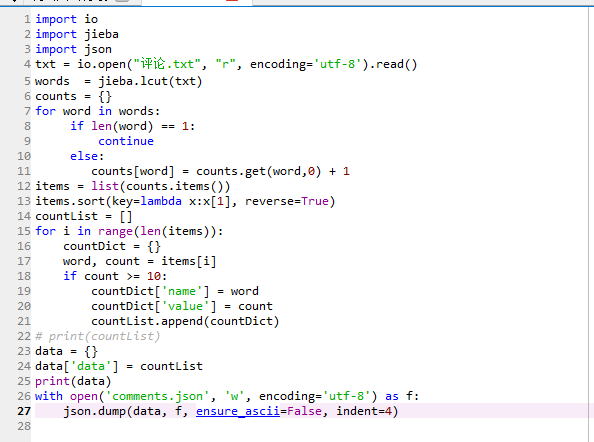
将统计的词频保存至"comments.json"
(3)绘制词云图
(这里使用开源库里的echart.js)

效果图如下

3.git操作
(1)克隆到本地
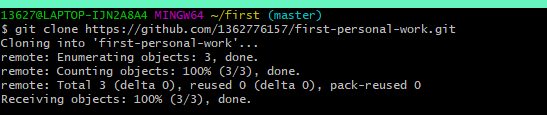
(2)切换分支

(3)往本地添加修改后的文件

(4)每次修改都得git add .之后git commit(由于是第一次使用所以是全部做完才上传,导致commit信息不足)
(5)上传git push
参考资料
| 标题 | 网址 |
|---|---|
| Python基于jieba的中文词云 | https://www.cnblogs.com/yuxuanlian/p/9781762.html |
| Python爬虫实战:爬取腾讯视频的评论 | https://my.oschina.net/u/4397001/blog/3421754 |
| 创建与合并分支 | https://www.liaoxuefeng.com/wiki/896043488029600/900003767775424 |
小结:熬了会夜把这作业肝完了,基本上除了爬取数据以外其他的全靠度娘,原本想着看下题目能做多少做多少因为我没多少时间复习(3.13教资),结果就停不下来了ε(┬┬﹏┬┬)3都已经凌晨2.30了!!博文就草草的写了日后有时间再说,希望这是假期的最后一次作业o(╥﹏╥)o
