一、dict字典表
特性:通过键(key) 不是通过下标访问数据
包含任意对象的无序集合
可变长度,可任意嵌套
属于“可变映射” 分类
对象引用表(Hash Table)
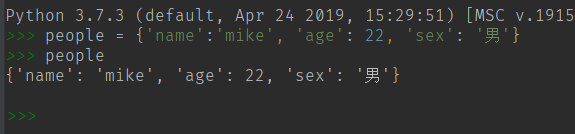
声明:{key: value}
key 只能是不可变的元素(∴可变类型List就不可以)。
一个空的字典表:d = { }
dict 字典表 是一个无序的集合。
通过内部Hash算法排序的
key 只能是不可变类型的数据。
可变类型就会抛出错误信息

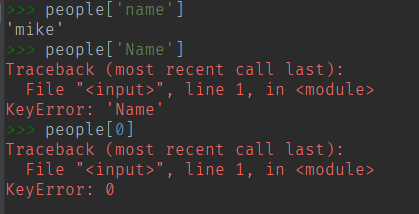
访问 dict 字典表的元素:dict[key]
不能通过索引访问,会报错。 。 Key不存在也会报错。
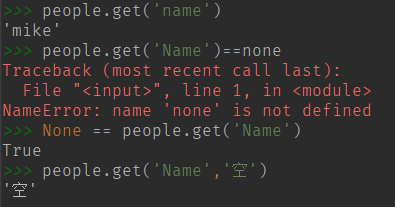
获取 Value:get(key)
通过get 访问, Key 不存在的时候不会抛出异常,而是返回None
get 方法后面的参数可以设置没有找到时返回的默认值
常用操作
(1) dict() 内置函数,转为 dict 字典表 【当key没有指定类型的时候,默认为字符串】


(2) fromkeys(keys) 将一组数据转化为 dict 字典表的 键

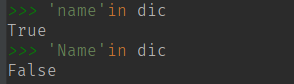
(3) in 判断 Key 是否存在
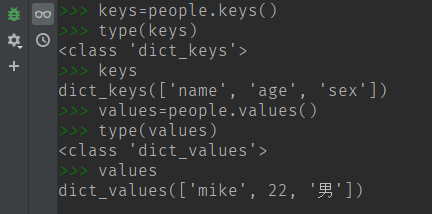
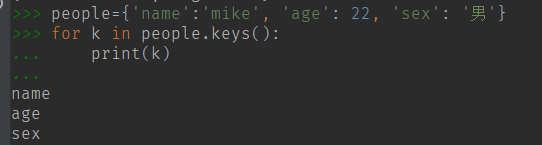
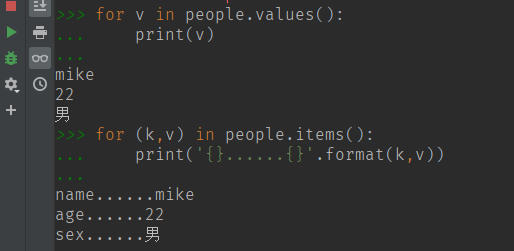
(4) keys() 获取 dict 字典表的所有键
(5) values() 获取 dict 字典表中所有的值
(6) items() 获取所有的项 ,返回一个数组类型的元组

(7) len(dict) 获取 dict 字典表的长度

(8) copy() 复制 dict 字典表

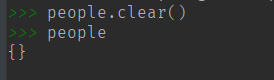
(9) clear() 清空 dict 字典表
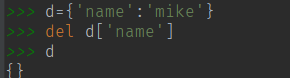
(10) 删除 del 与 pop() 方法 。
pop()方法是将 key:value 删除, 并返回 value 值。
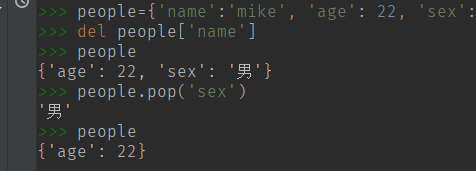
pop() 方法第二个参数如果删除的 key:value 不存在,则返回该值 。

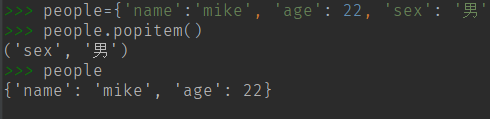
(11) popitem() 删除并返回顶层元组类型的元素 。
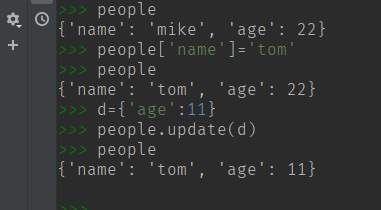
(12) 修改信息 : 直接赋值 或使用 update() 方法
(13)循环输出
二、元组 tuple
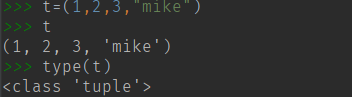
t = () 用圆括号表示
不可变序列(不支持原位改变,也不能像列表一样追加元素和扩展元素)
包含任意对象 可任意嵌套 通过下表访问
注意:
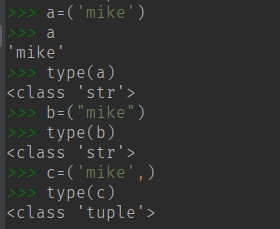
直接写 a = ('Mike') 会被当成字符串,所以申明元组则需这样子写 b = ('Mike', ) #加个逗号
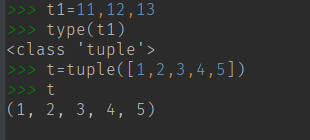
赋值元组的时候,圆括号是可以省略的,tuple() 函数将一个可迭代序列转化成元组
访问元组跟列表(list)访问是一致的
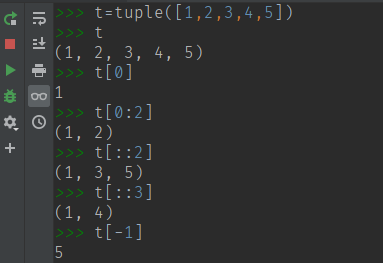
其他一些操作:(下面操作产生一个新的对象)
元组的通用操作,和列表的通用操作一致,如:
t in tuple1 某元素在元组里面
t not in tuple1 某元素不在元组里面
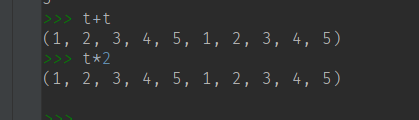
tuple1 + tuple2
tuple1 * 2
tuple[index]
tuple[ i : j ]
tuple[ i : j : k ]
len(tuple) 元组长度
min(tuple) 最小值
max(tuple) 最大值
sum(tuple) 总和
tuple.index(x) 某个元素第一次出现的元组下标
tuple.count(x) 某个元素出现几次
注意:
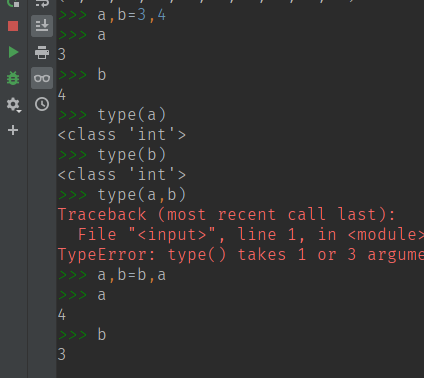
a , b = 5 , 10 这是分别给2个变量赋值。而不是声明一个元组
交换 a与b的值可以写成 a , b = b , a
三、文件
数据类型:指向一个特定的文件 。不管是文本或者文档。或者其他媒体文件。
声明方式: open('路径' , '模式' , encoding = '编码');
(1)路径
例如:‘C:\\Data\\temp.txt’ 斜杠需要转义,所以要写2个斜杠。 加 r 忽略转义 r'C:\Data\temp.txt'
(2)模式
区分下文件的形式有2种
【1】 文本模式:r 读 read 读取文本
w 写 write 写入文本 ,写模式会将内容替换掉
rw 读写
a 追加 append 向文本中追加内容
【2】二进制流:b
(3)encoding 编码 编码有 ACSII UTF8 .......
操作::
【读】
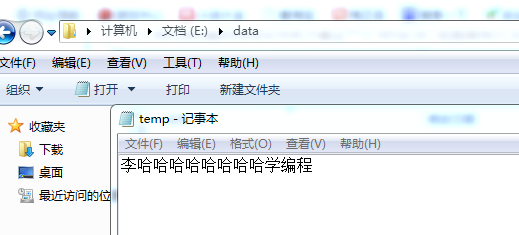
(1)我们在D盘的data文件夹下建立一个 temp.txt 在里面写入 欢迎使用Python
(2)接下来我们将文件读取输出到控制台上
我们通过 f.read() 方法将 temp.txt 文本文件的内容读取出来
(3)接下来使用 print() 方法将将 f.read() 的内容输出
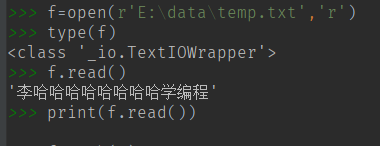
发现没有输出任何内容
原因是read() 函数的机制有一个指针,在读取的时候移动指针,当read结束的时候指针已经移动到了结尾。
所以,当我们调用 read() 函数的时候,指针继续移动,却读不到任何内容,所以打印出空的
解决方法:
【1】重新创建文件的实例 这种比较麻烦
【2】 seek(0) 将指针重新移动到开头
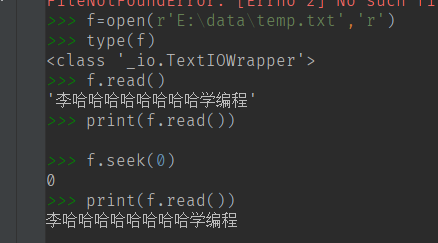
(4) 读取完,我们不需要在继续操作了,可以调用 close() 方法关闭

(5) read(num) 指定读取数量 【注:read() 不指定读取数量则一次性读取所有信息,假设文件很大,那么读取效率问题】
可以看到指定参数读取多少个字符

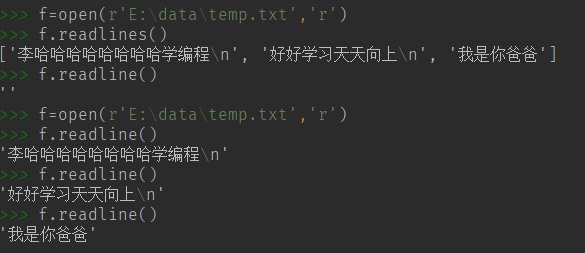
(6) readlines() 读取行,返回一个数组
(7) readline() 读取一行 ,调用一次,读取一行。
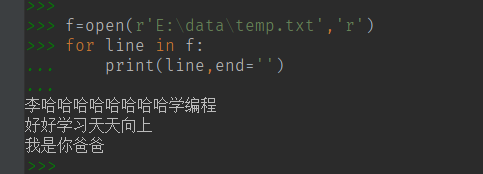
循环输出 :会看到隔一行
因为print() 函数本身带一个 \n 换行。 可以指定print() 函数的第二个参数 end,结束符号
【写】
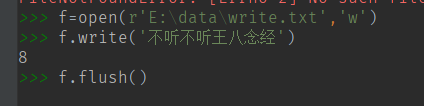
(1)新建一个 write.txt 文件进行写入操作 (不创建也可以,你open的时候也会帮你创建)
(2) write(str) 写入,返回写入字符的长度

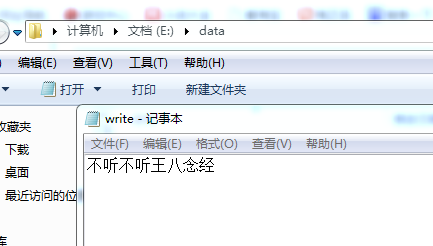
打开文本却发现什么都没有。

write(str) 只是将文本写入到内存中,还没有保存,如果想保存,可以调用 flush() 或者当已经操作完了可调用close()
flush() 方法将内存的操作进行映射到文本文件上 (不关闭文件情况下,输出缓存到硬盘上)
(3) writelines(list) 写入多个
产生文件并写入内容
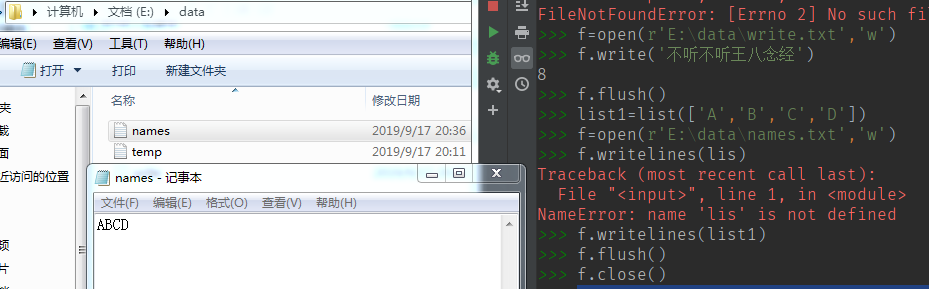
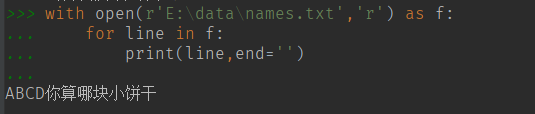
我们往 names.txt 中追加内容
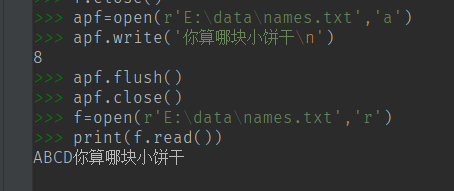
关于路径:
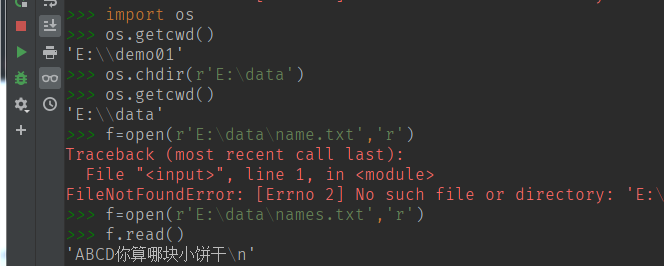
当我们省略掉盘符的时候,他是从系统的环境变量中找到Python的安装目录找文件

引用 os 使用 os.getcwd() 方法可以获取我们Python的安装目录
os.chdir(path) 指定操作目录
关于 f.close() 即使我们不手动close() 内存到一定程度也会自动回收
Python 提供了一种了一种上下文的语法
代码段执行完成之后会自动调用回收 (应用场景,文件读写,数据库读写)
with 后面就是上下文的语法: