

一次浴火重生的MySQL优化(EXPLAIN命令详解)
一直对SQL优化的技能心存无限的向往,之前面试的时候有很多面试官都会来一句,你会优化吗?我说我不太会,这时可能很多人就会有点儿说法了,比如会说不要使用通配符*去检索表、给常常使用的列建立索引、还有创建表的时候注意选择更优的数据类型去存储数据等等,我只能说那些都是常识,作为开发人员是必须要知道的。但真正的优化并不是使用那些简单的手法去完成实现的,要想知道一条SQL语句执行效率低的原因,我们可以借助MySQL的一大神器---"EXPLAIN命令",EXPLAIN命令是查询性能优化不可缺少的一部分,本文在结合实例的同时会总结explain命令的使用及相关参数的说明。
首先说说我这次浴火重生的优化初衷吧,上个月在公司完成的统计模块中,其中就有几条SQL语句执行的速度稍微有点慢,心里一直留了一道坎。直到昨天晚上在家看了一篇文章,是关于MySQL优化的对EXPLAIN命令的详解,所以今天一到公司就想着把之前那些SQL语句的病赶紧给看看,虽然,我没有达到那种秒查的效果,但是优化的效果还是有明显的提升。
业务场景:
分区统计XXX省每月上传数据的企业数量,何为企业是否是未上传数据,即专门存放上传数据的数据表中没有记录的为未上传数据的企业,如果有那么代表已经上传数据。
下面是我之前写的SQL语句(未优化前的),它执行的时间是2.318sec,并且使用EXPLAIN命令进行分析:
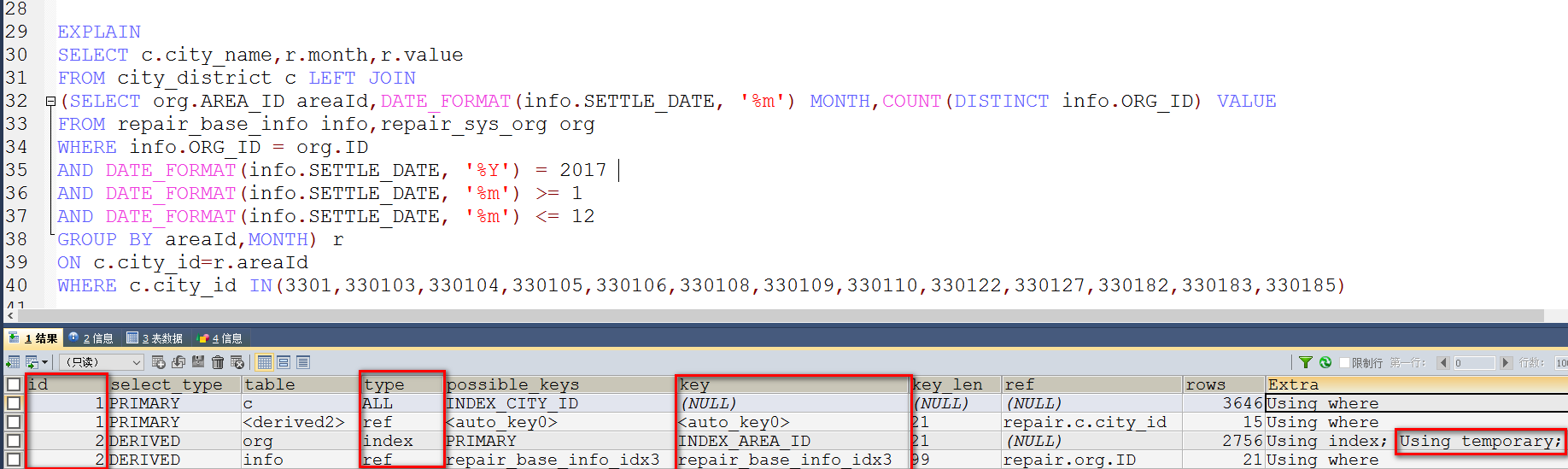
首先说说EXPLAIN命令查询后打印的数据列它们各个列代表的意思:
1、id :该列的值是用来顺序标识整个查询中SELELCT 语句的执行顺序,在嵌套查询中id越大的语句越先执行,该值可能为NULL。个人建议,可以在分析一条很长的SQL语句时可以依照它的值来按顺序进行切割分析优化。
2、select_type :表示当前select查询的类型,该列可能出现的值还有如下情况;

3、table :对应行正在访问哪一个表,表名或者别名(注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的);
-
关联优化器会为查询选择关联顺序,左侧深度优先
-
当from中有子查询的时候,表名是derivedN的形式,N指向子查询,也就是explain结果中的下一列
-
当有union result的时候,表名是union 1,2等的形式,1,2表示参与union的query id
4、type :该列的值代表的含义是访问数据表的检索类型,也是最为重要的优化指标之一,它的好坏情况依次是 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref级别,下面是各个值代表的意思。个人建议:可以在分析一条很长的SQL语句时,尽量让每个拆分的检索子句都到理想的优化级别;

5、possible_keys :显示查询使用了哪些索引,表示该索引可以进行高效地查找,但是列出来的索引对于后续优化过程可能是没有用的,也就是说该索引在查找的时候未必真正的使用上。
6、key :该列表示在检索时实际决定使用的键(索引)。如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
7、key_len :该列显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好 。
8、ref :该列表示使用哪个列或常数与key一起从表中选择行,个人翻译:就是当前检索中的语句与哪个表中的列联合查找数据的。
9、rows :该列显示MySQL认为它执行查询时必须检查的行数。注意这是一个预估值。个人建议:该值如果比整表总记录数越低,则越好。
10、Extra :该列的值是EXPLAIN输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息,MySQL查询优化器执行查询的过程中对查询计划的重要补充信息。我们通常根据该列的值来判断SQL语句是否需要优化;

根据上面的知识分析:
我通过MySQL EXPLAIN分析的思路是这样的:通常首先要根据id的值确定当前检索语句是何时执行的,注意分析的时候按顺序分析,其次在根据type列的值来判断当前检索语句是否需要优化,最后看决定性的一点就是根据Extra的值,上面表格中也说了,如果看到Using temporary一般就需要优化了。
因为我上面的那条语句是一个子查询,所以我首先根据id的值找到最先执行的检索语句,也就是嵌套在最内层的那条等值查询语句,它分别使用等值条件去连接企业表和上传数据表筛选出符合条件的数据,但是使用EXPLAIN命令分析得出,这条检索语句并不是真正的高效,在扫描org表的时候进行了全表数据连接而不是有条件的去刷选连接,而且在等值连接的时候并未真正使用主键索引去等值连接,再回过头来仔细想想我们的业务,就是拿着info表中的数据去org表中进行匹配,当然全表扫描info是避免不了的,但是org表不一定全部都扫描啊,所以我试着用左连接替代之前的等值连接,果然效果达到了,info表进行了全表数据匹配去连接org表中的数据,并且在匹配的时候org表的主键索引也真正使用到了,级别达到了eq_ref,至于info表的ALL级别,毋庸置疑业务需要必须就是要去扫描整表的;最后看到最外层的检索语句也未必是高效的,它关联的地区表也进行了全表数据匹配,但是我要的查询结果是根据子查询结果来得出的,肯定不比子查询结果的数据多,所以我将子查询结果作为左表去匹配地区表中的数据,果然,由ALL级别变成range级别,检查的行数也由3646减少到了15,经过分析优化执行速度提升1秒多,优化级别基本达到理想的状态,由于本人能力有限,只能做到这步:

以上都是本人经过实践得出,并非乱写,如果有地方总结不到位,希望各位留言补正,共同学习,共同进步,一直在优化的路上。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· 展开说说关于C#中ORM框架的用法!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?