
Python爬虫之xpath的基本使用
写在前面:
前段时间练习爬虫一直在使用Beautifulsoup,现在打算开始接触xpath,XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。
使用规则:
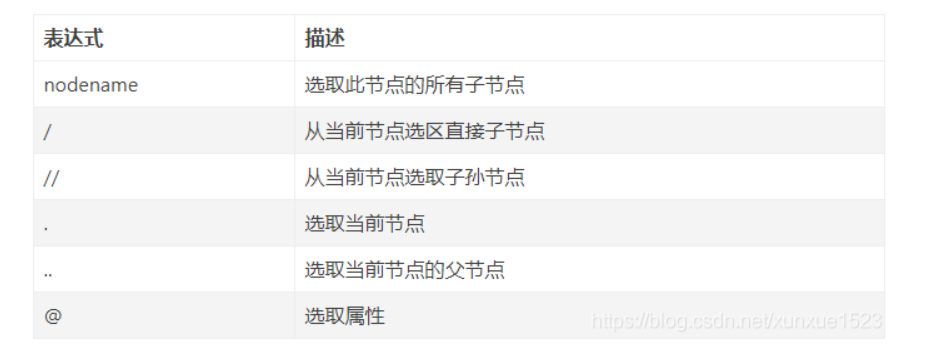
实例学习
<p>
<ul>
<li class="item-0"><a href="https://s1.bdstatic.com/">item 0 </a></li>
<li class="item-1"><a href="https://s2.bdstatic.com/">item 1 </a></li>
<li class="item-2"><a href="https://s3.bdstatic.com/">item 2 </a></li>
<li class="item-3"><a href="https://s4.bdstatic.com/">item 3 </a></li>
<li class="item-4"><a href="https://s5.bdstatic.com/">item 4 </a></li>
<li class="item-5"><a href="https://s6.bdstatic.com/">item 5 </a></li>
</ul>
</p>
'''
获取某个标签的内容
注意,获取a标签的所有内容,a后面就不用再加正斜杠,否则报错
html_data = html.xpath('/html/body/ul/li/a/text()') for i in html_data: print(i.text) 或 html_data = html.xpath('/html/body/ul/li/a') for i in html_data: print(i.text) text()是获取标签里的内容
打印指定路径下a标签的属性
这里可以通过遍历拿到某个属性的值,查找标签的内容,通过@属性名获取
html = etree.HTML(text) html_data = html.xpath('/html/body/ul/li/a/@href') for i in html_data: print(i)
[]里是具体属性,contains是包含,常用于属性匹配,而“//li[@class="item-1"]/a/text()”就是获取class为item-1标签的文本内容
from lxml import etree text = ''' <li class="zxc asd wer" name="222"><a href="https://s2.bdstatic.com/">1 item</a></li> <li class="ddd zxc eee" name="111"><a href="https://s3.bdstatic.com/">2 item</a></li> ''' html = etree.HTML(text) result = html.xpath('//li[contains(@class, "zxc") and @name="111"]/a/text()') print(result) # 运行结果:['2 item']
from lxml import etree print("------------") text = ''' <div> <ul> <li class="item-0"><a href="https://s1.bdstatic.com/">item 0 </a></li> <li class="item-1"><a href="https://s2.bdstatic.com/">item 1 </a></li> <li class="item-2"><a href="https://s3.bdstatic.com/">item 2 </a></li> <li class="item-3"><a href="https://s4.bdstatic.com/">item 3 </a></li> <li class="item-4"><a href="https://s5.bdstatic.com/">item 4 </a></li> <li class="item-5"><a href="https://s6.bdstatic.com/">item 5 </a></li> </ul> </div> ''' html = etree.HTML(text) # 获取第一个 result = html.xpath('//li[1]/a/text()') print(result) # 获取最后一个 result = html.xpath('//li[last()]/a/text()') print(result) # 获取前两个 result = html.xpath('//li[position()<3]/a/text()') print(result) # 获取倒数第三个 result = html.xpath('//li[last()-2]/a/text()') print(result) """ 运行结果: ['item 0 '] ['item 5 '] ['item 0 ', 'item 1 '] ['item 3 '] """
