
Python jieba库的使用
写在前面:
昨天的课堂测试中有这样一道题目要求:“使用中文分词算法解析所有新闻正文,并统计每个词语出现的数量”。Python的jieba库是优秀的中文分词第三方库,本篇博客用来记录jieba库的基本使用。
一.jieba库基本介绍
(1)概述
-
中文文本需要通过分词获得单个的词语
- jieba库提供三种分词模式,最简单只需掌握一个函数
(2)jieba分词的原理
- 利用一个中文词库,确定汉字之间的关联概率
- 汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
二.jieba库使用说明
(1)jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
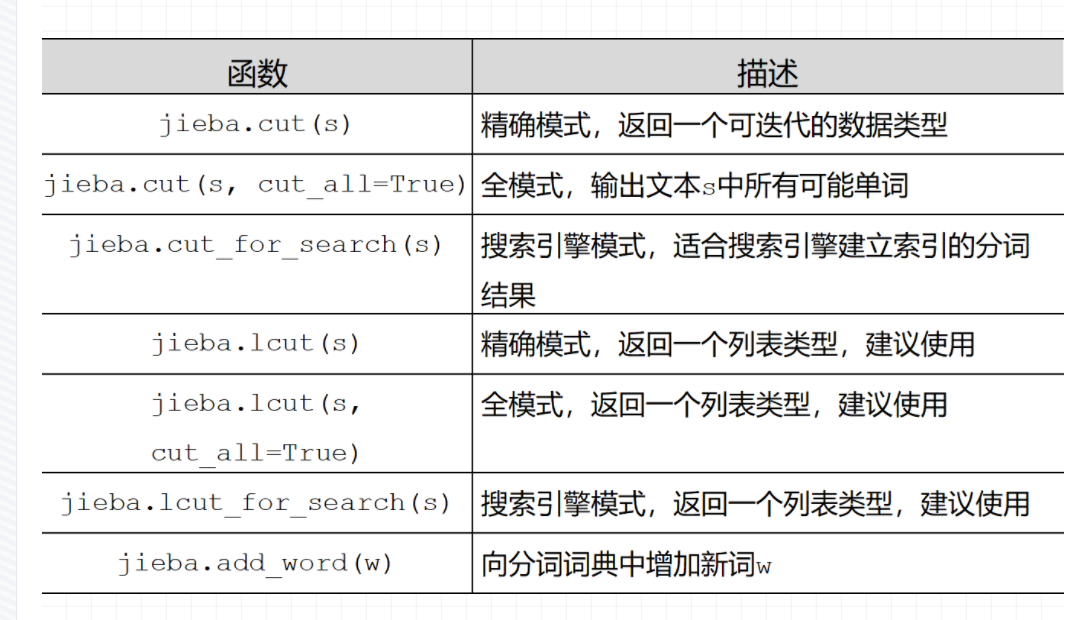
(2)常用函数
三.实例
用jieba统计csv文件里所有的中文词语并将结果插入数据库
1 import jieba 2 txt = open("房产.csv", "r", encoding='utf-8').read() 3 words = jieba.lcut(txt) # 使用精确模式对文本进行分词 4 counts = {} # 通过键值对的形式存储词语及其出现的次数 5 6 for word in words: 7 if len(word) == 1: # 单个词语不计算在内 8 continue 9 else: 10 counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1 11 12 items = list(counts.items()) # 将键值对转换成列表 13 items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序 14 15 for i in range(1000): 16 word, count = items[i] 17 import pymysql 18 19 db = pymysql.connect(host="localhost", user="root", password="156132", database="cloud1", charset="utf8mb4") 20 cursor = db.cursor() 21 sql = "insert into fangchan(word,count) values ('" + str(word) + "','" + str( 22 count) + "')" 23 try: 24 cursor.execute(sql) 25 db.commit() 26 # print(school_shengfen + "\t" + school_name + "添加成功") 27 except: 28 print("插入出错") 29 db.rollback() 30 31 print("{0:<5}{1:>5}".format(word, count))
