
MySQL用错了,99%的人已中招
在我们日常工作中,可能会经常使用MySQL数据库,因为它是开源免费的,而且性能还不错。
在国内的很多公司中,经常被使用。
但我们在MySQL使用过程中,也非常容易踩坑,不信继续往下看。
今天这篇文章重点跟大家一起聊一聊使用 MySQL 的15个坑,希望对你会有所帮助。
(我最近开源了一个基于 SpringBoot+Vue+uniapp 的商城项目,欢迎访问和star。)[https://gitee.com/dvsusan/susan_mall]
1查询不加where条件
有些小伙伴,希望在代码中,一次性把表中的所有数据都查出来,然后在内存中处理业务逻辑,认为代码性能更好。
反例:
SELECT * FROM users;
在查询数据的时候不加where条件。
这种情况下数据量小还好。
但如果数据量很大,每个业务操作,都需要查出表中的所有数据,可能会导致程序出现OOM问题。
如果数据太多,处理速度也会集聚下降。
正例:
SELECT * FROM users WHERE code = '1001';
使用具体的where查询条件,比如code字段,先过滤数据,再做处理。
2 没有使用索引
有时候,我们的程序,在刚上线的时候,数据比较少,没有加索引,问题不大。
但随着用户量越来越多,表中数据在呈指数级的增加。
突然有一天发现,查询数据变慢了。
例如:
SELECT * FROM orders WHERE customer_id = 123;
我们可以给customer_id字段加个索引:
CREATE INDEX idx_customer ON orders(customer_id);
这能大大提升速度!
3 不处理 NULL 值
问题描述:统计时忘了 NULL 的影响,以为结果准确,结果却大相径庭。
反例:
SELECT COUNT(name) FROM users;
这些只能统计name字段非NULL的数量。
其实,没有统计完全。
如果想统计所有的记录行数,我们可以使用COUNT(*)。
正例:
SELECT COUNT(*) FROM users;
这样就能统计所有行数。
4 数据类型选错
有些小伙伴,在创建表时,随意使用 VARCHAR(255),会导致性能低下,还浪费存储。
反例:
CREATE TABLE products (
id INT,
status VARCHAR(255)
);
这种情况的性能不佳。
我们可以将status字段该成tinyint类型:
CREATE TABLE products (
id INT,
status tinyint(1) DEFAULT '0' COMMENT '状态 1:有效 0:无效'
);
更节省空间。
5 深分页问题
我们在日常工作中,经常会遇到需要分页查询数据的场景。
我们一般会使用limit关键字。
例如:
SELECT * FROM users LIMIT 0,10;
如果数据多的时候,第一页、第二页、第三页可能查询性能还OK。
但如果查询到第10万页,可能查询性能,就会变得非常差。
这就出现了深分页问题。
如何解决深分页问题?
5.1 记录上一次的id
我们现在的主要问题是,在分页的查询过程中,假如要查询第10万页的数据,要先扫描第9万9999页的数据。
但如果我们把上一次查询的位置记录下,后面再查询下一页的时候,就可以直接从之前的位置开始,往后查询。
例如下面这样的:
select id,name where order
where id>1000000 limit 100000,10
上一次查询获取到的最大的id是1000000,那么本次查询直接从1000000的下一个位置开始查询。
这样就可以不用查询前面的数据,提升不少的查询效率。
但这套方案有两个需要注意的地方:
需要记录上一次的查询出的id,适合上一页或下一页的场景,不适合随机查询到某一页。
需要id字段是自增的。
5.2 使用子查询
先用子查询查询出符合条件的主键,再用主键id做条件查出所有字段。
select * from order where id in (
select id from (
select id from order where time>'2024-08-11' limit 100000, 10
) t
)
这样子查询中,可以走覆盖索引。
我们之前的SQL,查询10条数据,但需要回表100010次。
实际上,我们只需要查询10条数据,也就是我们只需要10次回表其实就够了。
通过子查询的方式,能够减少回表的次数。
因此,我们可以通过减少回表次数来优化深分页的问题。
5.3 使用inner join关联查询
根据子查询类似:
select * from order o1
inner join (
select id from order
where create_time>'2024-08-11'
limit 100000,10
) as o2 on o1.id=o2.id;
在inner join子语句中,也是先通过查询条件和分页条件过滤数据,返回id。
然后再通过id做关联查询。
可以减少回表的次数,从而提升查询速度。
6 没有用explain分析查询
有些现在sql语句,查询慢,却不去分析执行计划,结果就只能盲目优化。
正例:
EXPLAIN SELECT * FROM users WHERE email = 'test@example.com';
EXPLAIN 会告诉你查询是怎么执行的,帮助你找到瓶颈。
如果大家想进一步了解explain关键字,可以看看我的另一篇文章《SQL性能优化神器》,里面有非常详细的介绍。
7 字符集设置不当
有些小伙伴,喜欢将MySQL的字符集设置成utf8。
我几年之前也喜欢这干。
但后面出现问题了,比如在用户评价输入框中,用户输入了表情符合,可能会直接导致程序保存。
字符集设置错误,也可能会导致汉字变乱码,用户体验直线下滑。
正例:
CREATE TABLE messages (
id INT,
content TEXT
) CHARACTER SET utf8mb4;
建议大家在建表时,将字符集设置成使utf8mb4,它能够支持更多的字符,包括:常用中文汉字和一些表情符号。
8 SQL注入风险
用拼接 SQL 的方式,容易被 SQL 注入攻击,安全隐患大。
在一些自定义排序规则,使用order by 动态拼接用户选择的排序字段,或者排序方式,比如:升序或降序时,如果处理不好,就可能会出现SQL注入问题。
反例:
String query = "SELECT * FROM users WHERE email = '" + userInput + "';";
尽量少在sql中直接拼接字符串,而应该使用PreparedStatement预编译的方式。
正例:
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM users WHERE email = ?");
stmt.setString(1, userInput);
在MyBatis中在使用$符号赋值时要注意,最好使用#符号赋值。
如果大家对sql注入问题比较感兴趣,可以看看我的另一篇文章《卧槽,sql注入竟然把我们的系统搞挂了》,里面有非常详细的介绍。
9 事务问题
有些小伙伴,在日常工作中,写代码时可能会忘掉事务。
特别是在更新多个表时不使用事务,数据容易出现不一致的情况。
反例:
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
用户1给用户2转账100元,如果不用事务,可能会出现用户1转出了100,用户2却没收到的情况。
我们使用使用START TRANSACTION命令开启事务,使用COMMIT命令提交事务。
正例:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
这样如果用户1转出100成功了,但用户2转入100失败了,则用户1的数据会回滚。
在Spring中可以使用@Transactional注解声明式事务,或者使用TransactionTemplate类这种编程式事务。
建议优先使用TransactionTemplate这种编程式事务。
10 校对规则问题
我们的表和字段上,有个COLLATE参数,可以配置校对规则。
它主要包含了三种:
- 以_ci结尾的。
- 以_bin结尾的。
- 以_cs结尾的。
ci是case insensitive的缩写,意思是大小写不敏感,即忽略大小写。
cs是case sensitive的缩写,意思是大小写敏感,即区分大小写。
还有一种是bin,它是将字符串中的每一个字符用二进制数据存储,区分大小写。
使用最多的是 utf8mb4_general_ci(默认的)和 utf8mb4_bin。
我们的brand表在创建表的时候,使用的COLLATE是utf8mb4_general_ci,它不区分大小写。
CREATE TABLE `brand` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(30) NOT NULL COMMENT '品牌名称',
`create_user_id` bigint NOT NULL COMMENT '创建人ID',
`create_user_name` varchar(30) NOT NULL COMMENT '创建人名称',
`create_time` datetime(3) DEFAULT NULL COMMENT '创建日期',
`update_user_id` bigint DEFAULT NULL COMMENT '修改人ID',
`update_user_name` varchar(30) DEFAULT NULL COMMENT '修改人名称',
`update_time` datetime(3) DEFAULT NULL COMMENT '修改时间',
`is_del` tinyint(1) DEFAULT '0' COMMENT '是否删除 1:已删除 0:未删除',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='品牌表';
这样在使用下面sql语句查询数据时:
select * from brand where `name`='yoyo';
就能把大写的YOYO查出来。
如果我们的表中设置的COLLATE是不区分大小写,但是业务代码中,却区分了大小写,二者不一致,就可能会出问题。
这时候,在业务代码中,就不能直接使用equals方法判断字符串是否相同,而应该改成equalsIgnoreCase方法了。
11 使用过多的 SELECT *
有些小伙伴,在写的sql语句中,习惯性使用select *,一次性查询所有的字段。
反例:
SELECT * FROM orders;
这种做法每次都会查出很多没用的字段,不仅浪费带宽,也增加了查询开销。
好的做法是,每次只查询要用到的字段。
正例:
SELECT id, total FROM orders;
我们的业务中,只需要用到id和total字段的数据,其他的字段就可以无需查询。
12 索引失效
不知道你有没有遇到过,生成环境明明创建了索引,但数据库在执行SQL的过程中,索引竟然失效了。
由于索引失效,让之前原本很快的操作,一下子变得很慢,影响了接口的性能。
我们可以通过explain关键字,查看sql的执行计划,可以确认索引是否失效。
如果索引失效了,可能是哪些原因导致的问题呢?
下面这张图给大家列举了常见原因:
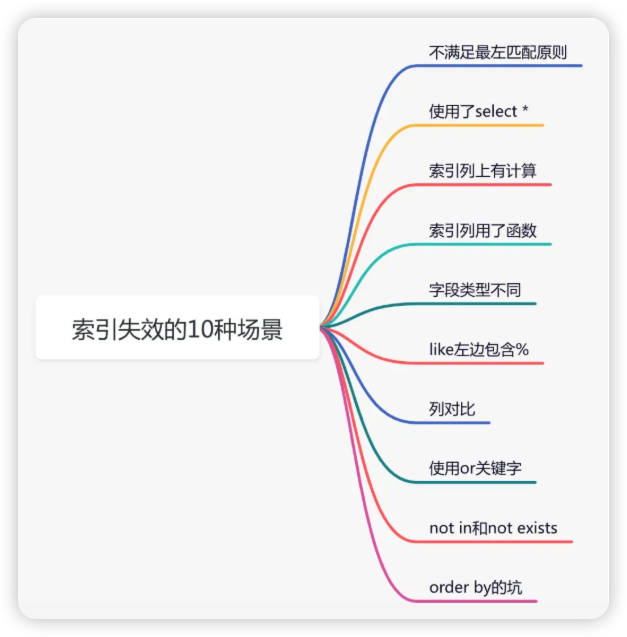
想进一步了解索引失效问题的小伙伴,可以看一下我的另一篇文章《聊聊索引失效的10种场景,太坑了》,里面有非常详细的介绍。
13 频繁修改表或数据
在高并发场景下,频繁添加、修改字段,或者批量更新数据,导致系统性能下降。
我们在使用alter添加或者修改表字段,或者使用update批量更新,或者使用delete批量删除数据时,都可能会锁表。
如果此时正好有大量的用户请求过来了,会导致系统响应变慢。
在高并发场景下,update或者delete的数据量,不要太多,可以分批,多次执行。
对于一些alter或drop修改表结构的操作,应该避免在用户高峰期执行,最好选择在凌晨,用户少的时候执行。
此外,可以使用Percona Toolkit、gh-ost等在线工具,可以在不锁表的情况下,进行alter操作。
14 没有定期备份
在工作中,最怕遇到猪队友误删数据。
我遇到过好几次。
将测试环境的表中的数据全删了。
数据全没了就后悔,太晚了。
建议定期备份,使用mysqldump:
mysqldump -u root -p database_name > backup.sql
我们可以写一个定时任务,每个一段时间,比如:一天或,备份一次数据。
后面如果哪天又被误删数据了,可以直接通过mysql命令,将数据还原。
15 忘了归档历史数据
有些小伙伴,经常吐槽,表中的历史数据太多,查询速度像蜗牛一样慢。
这时候,我们需要将历史数据归档了。
用户一般最关心的是最近:一个月、三个月、半年或者一年的数据。
他们极少会去查询一年以上的数据。
因此,建议将历史数据做归档。
在MySQL中只保存最新的数据,历史数据可以迁移到归档库中。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
本文收录于我的技术网站:http://www.susan.net.cn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号