
垃圾收集器
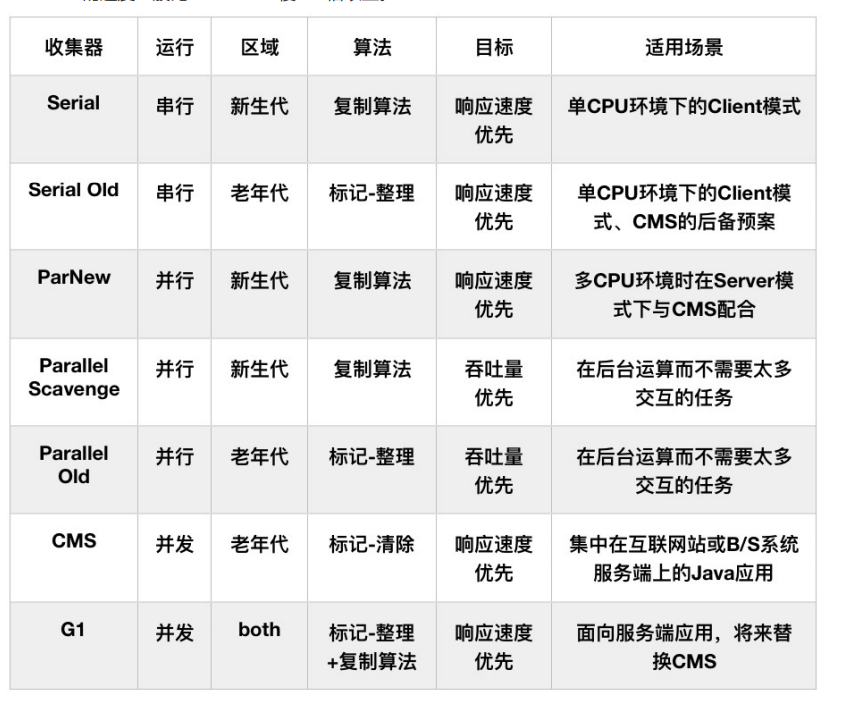
垃圾收集器依赖于具体的虚拟机实现。在本文中,我们采取的是 HotSpot,其内置了 7种类型的垃圾收集器实现。
Serial
Serial,最基本最老的收集器。其存在的主要问题是"Stop The World",即在垃圾回收的时候,必须要暂停所有的其他工作线程,直到收集完成。此外在工作的时候,其垃圾收集线程是单线程的。
ParNew
ParNew 其实就是 Serial 的多线程版本。其除了垃圾收集线程是多线程意外,其他功能与 Serial 一样,如收集算法、Stop The World 的特性、对象分配规则、回收策略等。
Parallel Scavenge
Parallel Scavenge 大多数特性与 ParNew 相似,其最主要的特点是其设计的目标是达到一个 可控制的吞吐量,所谓吞吐量就是 CPU 用于运行用户代码的时间和 CPU 总消耗时间的比值,即 吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)。高吞吐量意味着高效率地利用 CPU 时间,尽快完成程序计算任务,适合在后台运算而不需要太多交互的任务。
Serial Old
其是 Serial 的老年代版本,其他特性和 Serial 类似,不多赘述。
Parallel Old
其是 Parallel Scavenge 的老年代版本,适合跟 Parallel Scavenge 一起组成一个 吞吐量优先 的收集组合。
1、串行垃圾收集器、
串行:整个扫描和复制过程均采用单线程的方式,适合于单CPU、客户端级别。
采用多线程的方式来完成垃圾收集;适合于吞吐量要求较高的场合,比较适合中等和大规模的应用程序。
2、并行/吞吐量收集器
并行收集器是串行收集器的分代收集器; 主要区别在于多个线程用于加速垃圾收集。使用命令行选项启用并行收集器
可以使用命令行选项控制垃圾收集器线程的数量
CMS
1、初始标记
初始标记是简单标记一下 GC Roots 能关联到的对象,因此速度很快。并发标记则需要进行 GC Roots Tracing,重新标记是为了修正在并发标记期间因用户程序继续运行而导致标记产生变动的对象,最终执行并发清除过程。
在收集过程中,只有初始标记和重新标记需要 Stop The World, 耗时较多。而耗时较多的并发标记和并发清除阶段都是可以和用户线程一起执行的,因此其可以大大减少停顿时间。
优点:
1).将stop-the-world的时间降到最低,能给电商网站用户带来最好的体验。
2).尽管CMS的GC线程对CPU的占用率会比较高,但在多核的服务器上还是展现了优越的特性,目前也被部署在国内的各大电商网站上。
缺点:
1).对CMS在单核和多核机器上做测试。发现CMS在收集过程中会大量占用CPU的时间。所以在第二个阶段会比较漫长,所以一般将其设置在多核机器上。并且对于CMS在单核机器上的表现设计了一套启发式控制。这种控制将收集器看作一个掠夺者,而收集器会尽量赶在用户线程分配新的对象之前完成收集的工作。同样也有可能会出现用户线程希望分配对象,但目前空间不够,则需要停下收集器,这样会让整个收集时间大大加长。所以这时候一搬会选择扩张堆的大小。
2).Mark Sweep算法一直令人诟病的碎片问题,造成了堆空间的浪费以及利用率的下降。
3).需要较大的内存空间去运行,因为在很多并行的阶段,要考虑到用户程序运行时也要分配空间。所以一般选择在堆利用率达到一个常数的时候就开启CMS的收集。可以在VM argument里来设置这个阀值。(–XX:CMSInitiatingOccupancyFraction =n,n=0~100)
4).会产生浮动垃圾,由于CMS并发清理阶段用户线程还在运行着,伴随程序自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在当次收集中处理掉它们,只好等到下一次GC去处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号