
Redis是一个开源( BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件MQ。它支持多种类型的数据结构,如字符串( strings),散列( hashes),列表(lists),集合(sets),有序集合(sorted sets)与范围查询,bitmaps,hyperloglogs 和地理空间( geospatial )索引半径查询。Redis 内置了复制( replication) , LUA脚本( Lua scripting),LRU驱动事件( LRU eviction) , 事务( transactions )和不同级别的磁盘持久化( persistence ) , 并通过Redis哨兵( Sentinel )和自动分区( Cluster )提供高可用性( high availabiliy)。
Redis是单线程的,Redis是基于内存操作, CPU不是Redis性能瓶颈, Redis的瓶颈是机器的内存和网络带宽。
Redis单线程快的原因:多线程并不一定比单线程快,其原因是多线程的上下文切换是一个耗时的操作,redis是将所有的数据全部放在内存中的,针对内存系统使用单线程省去上下文切换操作效率就是最高的。(速度:cpu>内存>硬盘)。
Redis的五大数据类型(端口号默认6379)
- String key-value的形式
-
设置值:set key value
-
取值:get key
-
指定key追加值(如果当前的key不存在,相当于set key):append key_name 数据
-
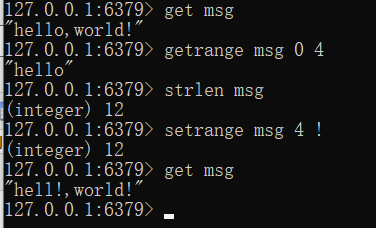
获取当前字符串的长度:strlen key_name
-
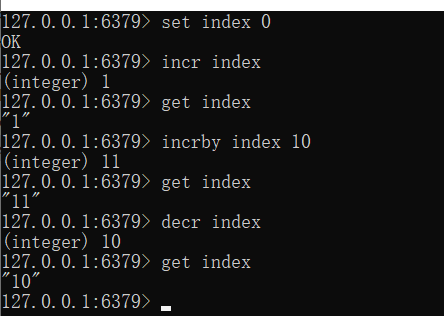
自增一:incr key_name (例如微信文章的浏览量,每次访问做一步该操作)
-
自减一:decr key_name
-
自增多个:incrby key_name 10 (每次增加10)
-
自减多个:decrby key_name 10 (每次减少10)
![]()
-
截取值的一部分:getrange key_name start_index end_index (取得是闭区间)、
- 替换值的一部分:setrange key_name start_index 替换的值
![]()
- 设置过期时间:setex key_name 时间(秒) 值
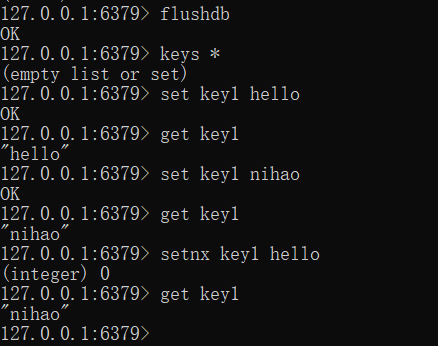
- 不存在再创建:setnx key_name 值
![]() 由此可以看出setnx的作用,如果key存在的话,就不会修改其中的值,返回0,但是set 会修改当前key的值,无论以前是否存在值。
由此可以看出setnx的作用,如果key存在的话,就不会修改其中的值,返回0,但是set 会修改当前key的值,无论以前是否存在值。- 批量设置值:mset
- 批量获取值:mget
- 批量的不存在然后设置值:msetnx (原子操作)
- 得到原来的值并且更新为新值:getset key_name 值
List 可以实现栈,队列的操作。(可以存在重复值)
-
- 从左侧插入元素:lpush key_name 值
- 从右侧插入元素:rpush key_name 值
- 取出元素:lrange key_name 范围值
- 移出数据:lpop key_name rpop key_name
![]() 相当于双端队列的,左边插入是头插法,右边则进行尾插。
相当于双端队列的,左边插入是头插法,右边则进行尾插。-
获取某一个元素:lindex key_name 下标值
- 获取列表长度:llen key_name
- 移除指定的值:lrem
- 更新值:lset
- 插入值:linsert
- 设置值:hset
- 取值:hget
- 取所有值:hgetall (key-value形式)
- 删除指定的key:hdel
- 插入值:sadd
- 查看指定set的所有值:smembers
- 查看元素个数:scard
- 移除元素:srem
- 随机删除一个元素:spop
- Zset 有序集合
 由此可以看出setnx的作用,如果key存在的话,就不会修改其中的值,返回0,但是set 会修改当前key的值,无论以前是否存在值。
由此可以看出setnx的作用,如果key存在的话,就不会修改其中的值,返回0,但是set 会修改当前key的值,无论以前是否存在值。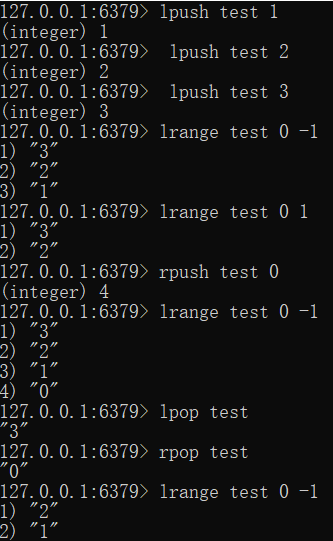 相当于双端队列的,左边插入是头插法,右边则进行尾插。
相当于双端队列的,左边插入是头插法,右边则进行尾插。三种特殊类型
- geo
- hyperloglog
- bitmap
切换数据库:select index(默认16个库 index取0~15,默认index为0)
查看库的大小: dbsize
查看所有的key:keys *
删除key:del key_name
移动key到另一个库:move key_name 库
查看类型:type key_name
删除数据库:flushdb
删除所有数据库:flushall
判断一个key是否存在:exists key_name
设置数据过期时间:expire key_name 10(second) 数据十秒后过期
查看剩余的时间: ttl key_name
事务
Redis单条命令保证原子性,但是事务无原子性。redis事务本质是一组命令的集合,一个事务中的所有命令都会被序列化,在事务执行过程中,按顺序执行。即在一个队列中一次性,顺序性,排他性执行一系列命令。
Redis事务:
- 开启事务 multi
- 命令入队列
- 执行事务 exec
取消事务:discard (事务开启以后,命令放入队列,执行该操作以后,队列的任务不会被执行)。
命令出现错误时,事务中的所有命令都不会被执行;但是在事务队列中某一条命令出现错误(入队列时么有报错),则会抛出错误,其他事务队列的命令可以正常执行。
悲观锁 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
CAS
乐观锁 就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会, 上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量 乐观锁策略:提交版本必须大于记录当前版本才能执行更新
- 采用watch监控
- 获取version
- 比较version的值,相同才会改变。
持久化(Redis是内存数据库,断电即失,因此持久化很重要)
- RDB 在指定的时间间隔内将内存中的数据集快照写入磁盘,它恢复时是将快照文件直接读到内存里。
- 在安装完Redis后,所有的配置都在redis.conf文件中,在这其中就提供了两种持久化方式,分别是RDB和AOF,默认的就是RDB,他所对应的文件名称是dump.rdb。
- 触发方式:(执行flushall命令也会产生dump.rdb文件,但是里面是空的,无意义。)
- save方式 该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止,执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。当数据量很大时,这种方式显然是不可取的。
- bgsave方式 执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。Redis会单独创建( fork ) 一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何I/0操作的。这就确保了极高的性能。
- save配置的规则满足(redis.conf文件),自动触发bgsave。
save 900 1 //表示15分钟内如果至少有 1 个 key 的值变化,则保存 save 300 10 //五分钟秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000 //一分钟内如果至少有 10000 个 key 的值变化,则存
- 数据恢复只需要将rdb文件放在我们redis启动目录就可以, redis启动的时候会自动检查dump.rdb恢复其中的数据,可以通过config get dir来获取该dir目录。
- 优点
- 适合大量数据的恢复
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
- 缺点
- 需要一定的时间间隔,如果redis意外宕机,会丢失数据。
- fork进程时会占用一定的内存空间。
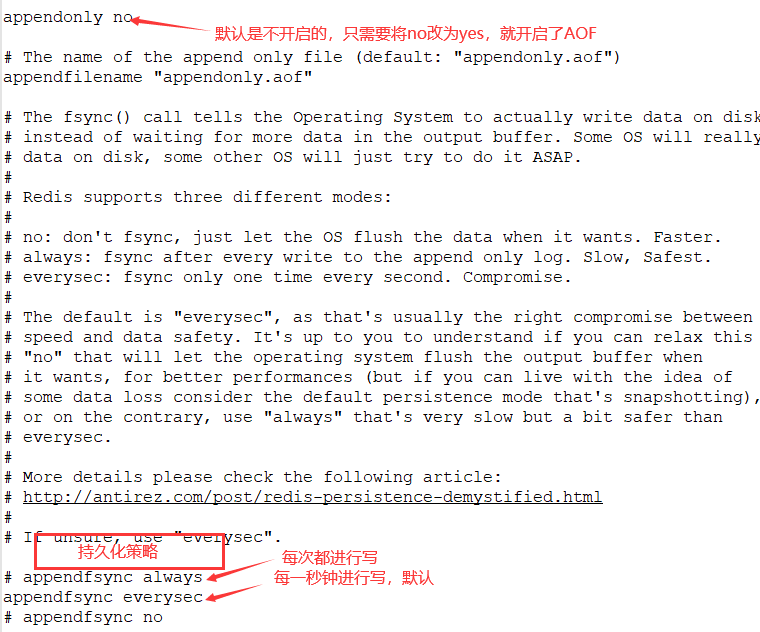
- AOF 以日志的形式来记录每个写操作,将Redis执行过的所有指令记录下来(读操作不记录) , 只许追加文件但不可以改写文件, redis启动之初会读取该文件重新构建数据,换言之, redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
- 对应的文件是appendonly.aof文件。
![]()
- always 同步持久化每次发生数据变更会被立即记录到磁盘性能较差但数据完整性比较好
- everysec 默认推荐,异步操作,每秒记录如果一秒内宕机, 有数据丢失。
- no
-
- Rewrite AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阀值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
- 重写原理 AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
- 触发机制 Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
- 优点
- Rewrite AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阀值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
-
AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据,每一次同步都修改,文件完整性高。
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite(重写)还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据。
-
-
- 缺点
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大,修复的速度也比RDB慢。
- 缺点
RDB与AOF可以同时存在,同时存在时先加载AOF文件,如果 appendonly.aof 文件损坏,redis服务器就无法启动,可以采用 redis-check-aof --fix appendonly.aof 命令来恢复该文件。
主从复制 主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master(主)以写为主,Slave(从)以读为主。(info replication 命令查看其角色身份)
作用
- 读写分离
- 容灾恢复
使用
- 从机通过 SLAVEOF 主库IP+端口 绑定到主机同步主机的内容,丛机只能读取,不能写入命令。
- 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件,否则slave变成master;但是master断开重连后仍是master,并且master断开后,丛机会原地待命(等待主机的重新连接),丛机也可以用SLAVEOF no one 命令转成主库,使当前数据库停止与其他数据库的同步(反客为主)。
- (薪火相传)上一个Slave可以是下一个slave的Master, Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻master的写压力;中途变更转向:会清除之前的数据,重新建立拷贝最新的。
复制原理
- Slave启动成功连接到master后会发送一个sync命令|
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中(首次全量)。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步。
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行。
哨兵模式 反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。(通过新建sentinel.conf文件,并且配置,启动哨兵模式,当产生新的master后,以前的master重新连接后,会将其变成新的master的salve,不会出现双master的问题)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号