博雅大数据机器学习十讲第一讲
机器学习第一讲
- 大数据是指数据采集、数据清洗、数据分析和数据应用的整个流程中的理论、技术和方法。
- 机器学习是大数据分析的核心内容。机器学习解决的是找到将X和Y关联的模型F,从Data到X的步骤通常是人工完成的(特征工程)。
- 深度学习是机器学习的一部分,其核心是自动找到对特定任务有效的特征,也即自动完成Data到X的转换。
- 如果我们的任务Y是模拟人类(自动驾驶、围棋AlphaGO)的行为,则这类任务称为人工智能。深度学习也是目前AI中的核心技术
机器学习方法分3类:
- 有监督学习(supervised learning)
- 数据集中的样本带有标签,有明确目标
- 回归和分类
- 无监督学习(unsupervised learning)
- 数据集中的样本没有标签,没有明确目标
- 聚类、降维、排序、密度估计、关联规则挖掘
- 强化学习(reinforcement learning)
- 智慧决策的过程,通过过程模拟和观察来不断学习、提高决策能力
- 例如:AlphaGo
有监督学习:
- 数据集中的样本带有标签
- 目标:找到样本到标签的最佳映射
- 应用场景:垃圾邮件分类、病理切片分类、客户流失预警、客户风险评估、房价预测等。
- 典型方法
- 回顾模型:线性回归、岭回归、LASSO和回归样条等
- 分类模型:逻辑回归、k近邻、决策树、支持向量机等
无监督学习:
- 聚类:讲数据集中相似的样本进行分组,使得:
- 同一组对象之间尽可能相似;
- 不同组对象之间尽可能不相似。
- 应用场景:
- 基因表达水平聚类
- 篮球运动员划分
- 客户分析
强化学习:
- 基本概念
- agent:智能体
- environment:环境
- state:状态
- action:行动
- reward:奖励
- 策略:π
- 目标:
- 求解最大化效用E的最优策略
过拟合问题
- 模型过于复杂,导致所选模型对已知数据预测得很好,但对未知数据预测很差。
度量结构:以文本处理为例,计算两篇文章词频向量的余弦相似度。
k近邻算法最常用的数据结构为k-d树,它是二叉搜索树。
PageRank算法:
-
在网络结构上定义邻接矩阵A=[aij],其中aij定义为节点i与j相连为1否则为0
-
从邻接矩阵得到概率转移矩阵,T=[tij],其中
\[t_{ij}=\frac{a_{ij}}{ \sum_{j} a_{ij}} \] -
如果用πi表示节点i的重要性,求解方程π=πT
-
可见PageRank的解是转移矩阵特征值1对应的特征向量
案例1:使用KNN对新闻主题进行自动分类
- 读入数据文件并查看数据
import pandas as pd
%matplotlib inline
raw_train = pd.read_csv("./input/train_sample_utf8.csv",encoding="utf8")
raw_test = pd.read_csv("./input/test_sample_utf8.csv",encoding="utf8")
raw_train.head(5)
raw_test.head(5)
raw_train.shape
raw_test.shape



- 可见,训练集包含 5521 条新闻,测试集中包含 3111 条新闻。那么,训练集和测试集中,不同主题的新闻分布如何?我们可以借助
DataFrame某列的value_counts方法完成统计。然后使用plot函数进行可视化显示。
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
raw_train["分类"].value_counts().sort_index().plot(kind="barh",title='训练集新闻主题分布')
plt.subplot(1, 2, 2)
raw_test["分类"].value_counts().sort_index().plot(kind="barh",title='测试集新闻主题分布')
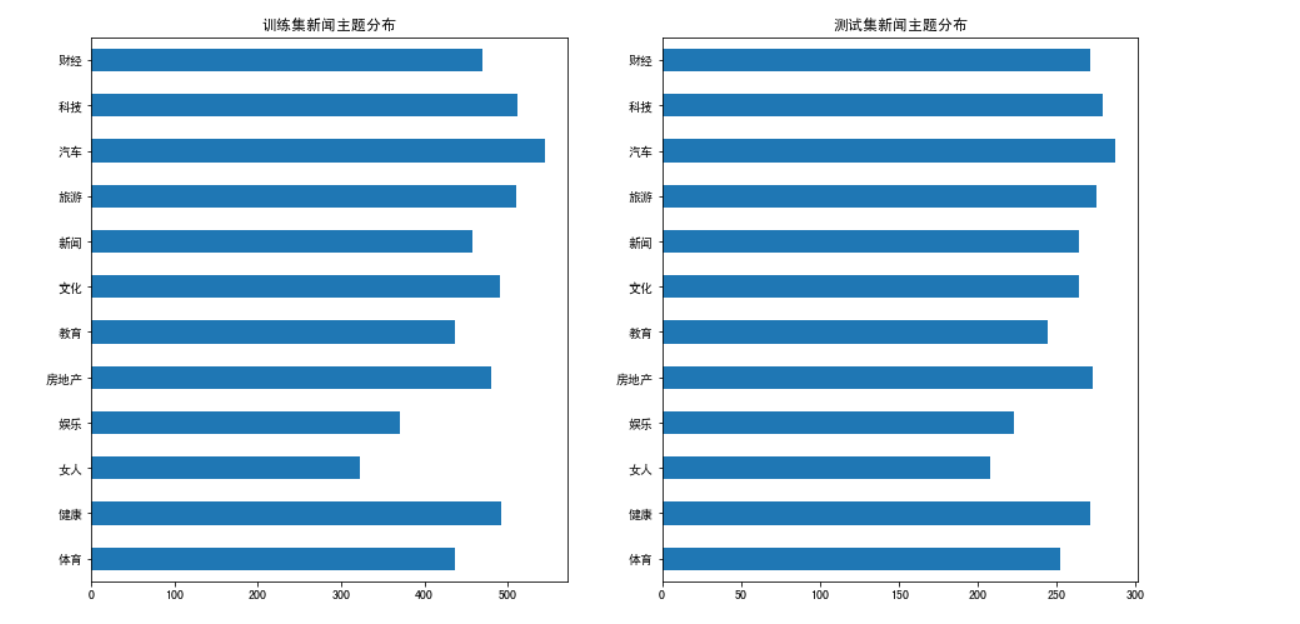
一共包含 12 种主题的新闻,无论是在训练集还是测试集,各个主题的新闻分布较均衡。
- 对新闻内容进行分词
由于新闻为中文,再进一步进行处理之前,我们需要先对新闻内容进行分词。简单来说,分词就是将连在一起的新闻内容中的词进行分割。这里我们使用 Python 中一个著名的中文分析器 jieba 完成这项任务。为了后续方便,我们封装一个 news_cut 函数,它接受的输入为新闻内容,输出为分词后的结果。分词后,词与词之间使用空格进行分隔。
import jieba
def news_cut(text):
return " ".join(list(jieba.cut(text)))
#简单测试下分词效果
test_content = "六月初的一天,来自深圳的中国旅游团游客纷纷拿起相机拍摄新奇刺激的好莱坞环球影城主题公园场景。"
print(news_cut(test_content))
现在利用封装的分词函数,对训练集和测试集中的新闻内容进行分词处理,分词结果保存到对应 DataFrame 对象的 ”分词文章“ 一列。这里我们使用了 Pandas 中的 Series 对象的 map 函数。它能够接受一个函数,对 Series 中的每一个元素作为该函数的输入,然后将函数的输出返回。
raw_train["分词文章"] = raw_train["文章"].map(news_cut)
raw_test["分词文章"] = raw_test["文章"].map(news_cut)
raw_test.head(5)
- 将新闻表示为向量
#加载停用词
stop_words = []
file = open("./input/stopwords.txt")
for line in file:
stop_words.append(line.strip())
file.close()
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(stop_words=stop_words)
X_train = vectorizer.fit_transform(raw_train["分词文章"])
X_test = vectorizer.transform(raw_test["分词文章"])
- 构建KNN分类器
使用 sklearn 中 neighbors 模块的 KNeighborsClassifier 类构建一个 KNN 分类器。我们将邻居数 n_neighbors 设置为 5 。使用邻居的标签进行投票时,用预测样本与邻居样本的距离的倒数作为权重。然后使用 fit 方法,在训练集中训练模型。
from sklearn.neighbors import KNeighborsClassifier#导入k近邻算法
knn = KNeighborsClassifier(n_neighbors=5,weights="distance")
knn.fit(X_train, raw_train["分类"])
- 测试集新闻主题预测
模型训练完成后,可以使用 predict 方法对测试集中的样本进行预测,得到预测标签列表 Y_test 。
Y_test = knn.predict(X_test)
- 新闻主题分类效果进行评估
下面使用混淆矩阵来分析模型在测试样本上的表现。混淆矩阵从样本的真实标签和模型预测标签两个维度对测试集样本进行分组统计,然后以矩阵的形式展示。借助混淆矩阵可以很好地分析模型在每一类样本上的分类效果。为了更直观地分析,我们借助 Python 中可视化包 seaborn 提供的 heatmap 函数,将混淆矩阵可视化。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9, 7))
## 设置正常显示中文
sns.set(font='SimHei')
## 绘制热力图
ax = sns.heatmap(confusion_matrix(raw_test["分类"].values,Y_test),linewidths=.5,cmap="Greens",
annot=True, fmt='d',xticklabels=knn.classes_, yticklabels=knn.classes_)
ax.set_ylabel('真实')
ax.set_xlabel('预测')
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
ax.set_title('混淆矩阵热力图')
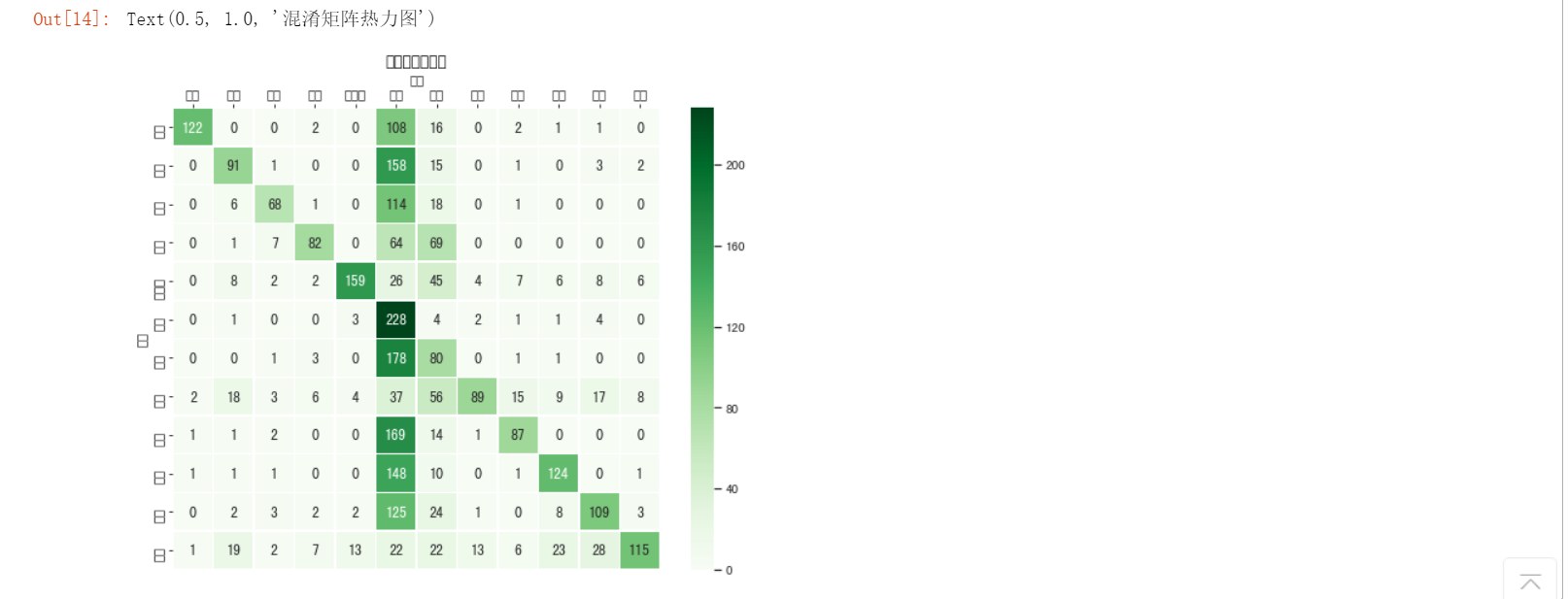
这还不是一个完美的新闻主题分类器,这个分类器倾向于将主题预测为"教育"或"文化"。要获得更好的效果,我们可能还需要做很多工作,例如更好的文本预处理和表示,尝试不同的 K 值的效果,甚至利用其它的机器学习算法等。
案例2:使用PageRank算法对全球机场进行排序
- 数据集介绍
文件 ./input/out.opsahl-openflights.csv 中的有向网络包含世界各机场之间的航班。有向边表示从一个机场到另一个机场的飞行航线。这个数据集是从Openflights.org 数据中提取出来的,与 Tore Opsahl 在数据集列表中的网络14c相对应,来源网址为:toreopsahl.com。
利用 networkx 中的 read_edgelist 函数,将网络加载到内存中。注意,由于我们处理的是有向网络,所以需要将 create_using 参数设置为 nx.DiGraph()。
import networkx as nx
flights_network = nx.read_edgelist("./input/out.opsahl-openflights.csv",create_using=nx.DiGraph())
print("航班数:" + str(len(flights_network.nodes)))
print("航线数:" + str(len(flights_network.edges)))

在这个航线网络中,一共包含 2939 个机场,30501 条航线。下面我们使用 nx.draw 函数,将网络进行可视化。
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(24, 16))
pos_flights = nx.kamada_kawai_layout(flights_network) #网络布局
ax.axis("off")
plt.box(False)
nx.draw(flights_network, node_size=30,node_color = "green", edge_color = "#D8D8D8",width=.3, ax=ax)
- 找出最大连通子图
从上图中很容易看出,这个网络不是一个连通图。我们从航线网络中提取出最大连通子图进行进一步分析。 对于有向网络, networkx 中的 weakly_connected_component_subgraphs 函数可以返回网络中的连通子图列表。我们只提取最大连通子图。
largest_component = max(nx.weakly_connected_component_subgraphs(flights_network), key=len)#找出最大连通子图
print("航班数:" + str(len(largest_component.nodes)))
print("航线数:" + str(len(largest_component.edges)))
在最大连通子图中,一共包含 2905 个机场和 30442 条航线。下面将最大连通子图进行可视化。
fig, ax = plt.subplots(figsize=(24, 16))
pos_flights2 = nx.kamada_kawai_layout(largest_component)
ax.axis("off")
plt.box(False)
nx.draw(largest_component, node_size=30,node_color = "green", edge_color = "#D8D8D8",width=.3,pos = pos_flights2, ax=ax)
- PageRank算法简介
PageRank算法是由谷歌创始人拉里·佩奇(Larry Page)和谢尔盖·布林(Sergey Brin)所设计出来的谷歌搜索引擎上的页面排序算法,最早作为论文发表于 1998 年。 论文发表之后没多久,佩奇和布林就以此论文为基础创立了谷歌公司。
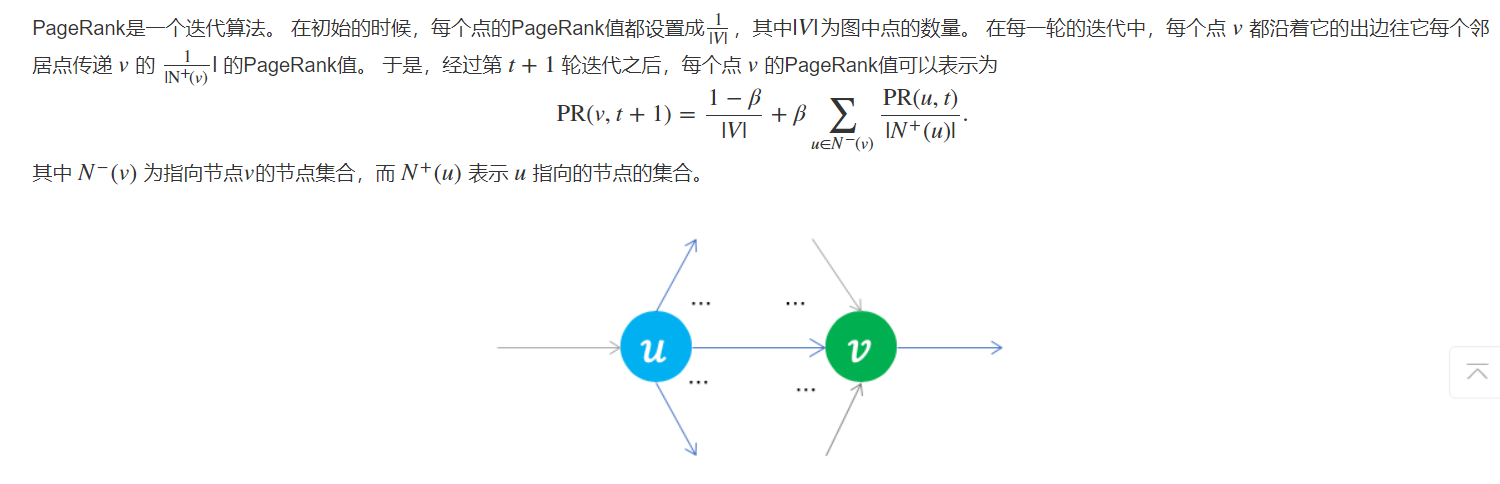
阻尼系数 β 用来表示在PageRank迭代过程中一个点沿着出边跳转到下一个点的概率。 (1−β)表示在浏览过程不沿着边跳转,而是在所有点中随机挑选下一个点的概率。 实际试验证明 β 被设置成 0.85 时 PageRank 的计算结果最符合实际情况。
- 使用PageRank算法对机场进行排序
在 networkx 中,使用 pagerank 函数即可计算网络中节点的 PageRank 值。
pr_dict = nx.pagerank(largest_component)
import pandas as pd
pr_df = pd.DataFrame.from_dict(pr_dict,orient="index")
pr_df.columns = ["pr_value"]
pr_df.sort_values(by = "pr_value").head(20)
pr_df.head(20)
- 将节点大小与PageRank值关联并可视化
实现一个函数 get_nodesize_pagerank ,将网络中节点的 PageRank 值,映射为网络中节点的大小。
def get_nodesize_pagerank(pagerank, min_size, max_size):
nodesize_list = []
pr_max = max(pagerank.values())
for node, pr in pagerank.items():
nodesize = (max_size - min_size)*pr/pr_max + min_size
nodesize_list.append(nodesize)
return nodesize_list
fig, ax = plt.subplots(figsize=(24, 16))
pos_flights2 = nx.kamada_kawai_layout(largest_component)
ax.axis("off")
plt.box(False)
nx.draw(largest_component, node_size=get_nodesize_pagerank(pr_dict,1,100),node_color = "green", edge_color = "#D8D8D8",width=.3,pos = pos_flights2, ax=ax)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号