前言
在19年的4月份,我要写一篇论文,涉及生境质量的,用到了InVEST中的生境质量模型(Habitat Quality),模型要求的数据比较多,需要用ARCGIS进行数据处理,数据处理不难,就是属性表统计计算,栅格计算,裁剪等过程,但是略繁琐,本文的目的就是捋清思路,整理出清晰的数据处理流程,对有需要的人提供一点帮助。
InVEST生境质量模型(Habitat Quality)原理就不做介绍了,因为太复杂了,我也不是很懂,生境质量模型(Habitat Quality)只是InVEST其中的一个模型,InVEST还包含了很多其它的模型。软件下载直接搜InVEST就可以,网上也有安装教程,把用户手册也要下下来,方便查阅。本文需要与InVEST用户手册中的生境质量模型(Habitat Quality)的说明一起看。
流程
直接看生境质量模型(Habitat Quality)的数据需求,该模型数据有的是可选的,有的是必须的,这里只讲必须的:
1.土地利用数据(LULC/LUCC)
获取途径很多,可以买;可以在网上下载免费的,提供一个免费网址:http://data.ess.tsinghua.edu.cn/?tdsourcetag=s_pcqq_aiomsg
这个数据是世界首套10m空间分辨率的全球土地覆盖产品(FROM-GLC10);还可以用专业的遥感处理软件进行分类或者目视解译。
2.威胁因子数据
是一个表格数据,要csv格式,名字就命名为threats.csv,具体的要求可以参考模型的用户手册,有几个注意点:①表格要符合用户手册里的要求。下图1是用户手册里模板,图2是参考的文献里的,对应上即可;②第一列中的各种威胁因子名字可以自己定义(类名用英文),不需要跟模板中的名字一样;③表头名一定要跟模板一致。模型里都有示例数据,也可以作为参考。至于最大影响距离和权重,可以多参考一些文献、专家咨询等,根据实际情况决定。参考一下图3中我做论文时完整威胁因子数据表格。
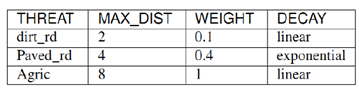
图1
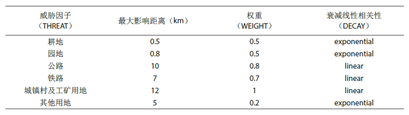
图2

图3
3.威胁源数据
先讲下如何获取,其实还是从LUCC/LULC里获取,举个例子:如上图2,耕地是威胁因子,首先把LUCC/LULC数据栅格转矢量(因为转为矢量后对属性表操作较为容易),再将矢量数据属性表中的所有耕地赋值为1,其他的赋值为0,随后将矢量数据转回为栅格数据,耕地威胁源数据就完成了,其他的威胁源数据以此类推。下面是具体的操作流程。所用的数据就是上面提到的10m空间分辨率的全球土地覆盖数据,下载的全国的(图4),下载和拼接的工作量都很大。裁剪一小块作为示例数据(图4)。这里有个注意的点,很重要,用户手册里也提到了:“请不要在威胁地图上留下任何为‘NoData’的空值,如果某个区域没有威胁,则设置威胁等级为0”。这句话的意思是说,所有Nodata区域值都得为0。这里讲一下,在arcgis软件中每个栅格数据都默认有一个最小外接矩形,在外接矩形中栅格数据之外的空白部分,值都为nodata,如图5中,选择一块区域查看信息,值为nodata,这些空白区域的值要赋值为0,这个一定要注意!
图4
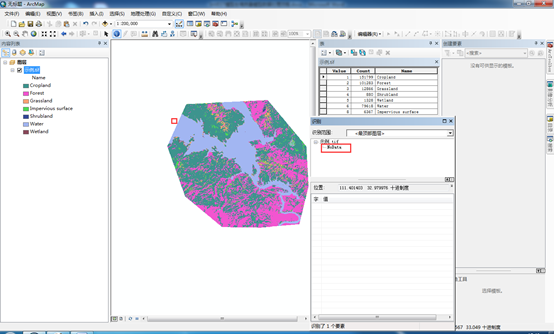
图5
3.1.nodata处理
威胁源数据提取之前,先把nodata的问题搞定:依次找到arctoolbox->spatial analyst工具->地图代数->栅格计算器,输入计算公式:“Con(IsNull("示例.tif"),0,"示例.tif")”,不要直接复制或者自己用键盘打出公式,要在函数列表中选择相应的函数,con函数就是第一个,isnull函数把列表拉到底,即可找到,如图6所示。运行等待结果。
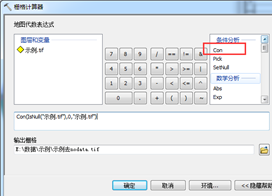
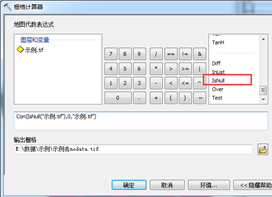
图6
结果如图7所示,nodata值都变成了0。
图7
3.2威胁源因子数据的提取
下面开始进行威胁源因子数据的提取(以耕地为例,按照分类体系,耕地的value值为1):
3.2.1栅格转矢量
依次找到arctoolbox->转换工具->由栅格转出->栅格转面,输入数据lucc/lulc数据,字段默认value字段,输出结果保存路径,简化面取消勾选,运行后等待结果。结果如图8,gridcode字段就是由value字段转化而来。
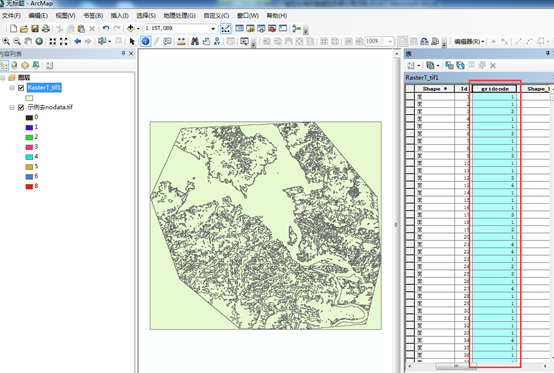
图8
3.2.2创建value
右键打开属性表添加字段,操作如图,名称一定要命名为“value”,类型选择短整型即可,添加完毕,此时的value值为空。
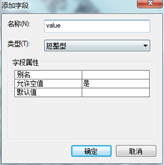

图9
3.2.3对value赋值
在属性表中选择按属性选择,在输入区输入“gridcode=1”,点应用,相应要素被选中并高亮显示,鼠标移至value字段表头,右键,左击字段计算器,按照如图10选择并输入,点击确定。

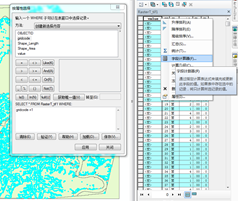
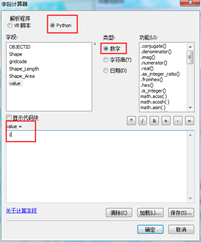
图10
上面是对gridcode=1的要素进行赋值,gridcode≠1的要素要赋值为0。在属性表中直接点击切换选择,就反选出了value剩余为空值的要素,重复字段计算器操作,输入0,点确定,剩余的空值都被赋值为0,如图11,到此赋值完成。

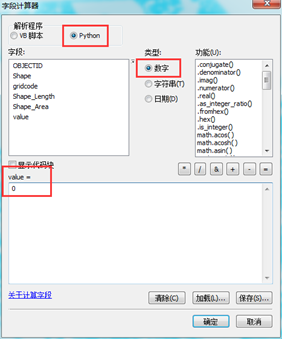
图11
3.2.4矢量转栅格
依次找到arctoolbox->转换工具->转为栅格->面转栅格,输入矢量数据,值字段选择value,输出栅格位置,最后一项像元大小,选择跟原始数据一样的像元大小,这里一个注意点:输出栅格数据一定要按照“xxx_c.tif”的格式命名,我这威胁源是耕地,所以命名成“gengdi_c.tif”。命名要求用户手册中有。
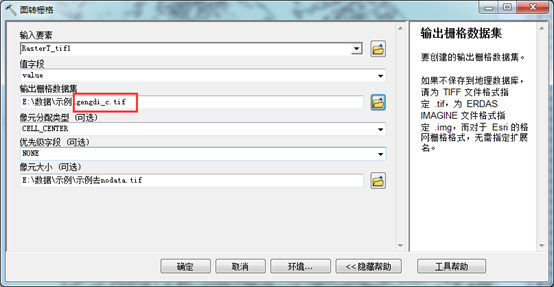
图12
输出结果,如图13,0为其他地类,1为耕地,至此,耕地威胁源因子栅格数据提取完成。其他危险源数据按照上述方法重复操作即可。
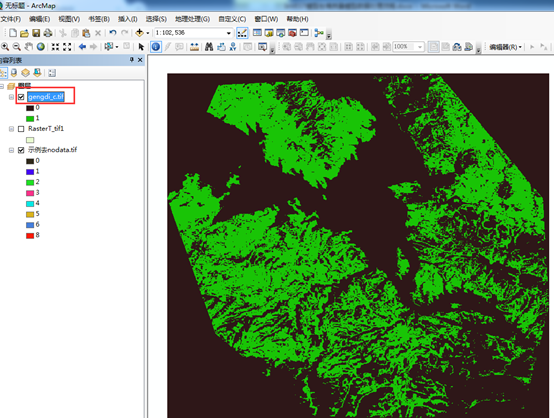
图13
4.退化源的可达性
用户手册中有一个数据提一下,退化源的可达性,这个数据是可选数据,但是如果有这个数据的加入,最终运行的结果准确性会大大增加,按照用户手册的翻译的内容来理解,就是将研究区域内的各种法定的禁止开发区矢量数据做并集,然后在属性表中添加access字段,并对access赋值,这个值范围0-1,根据不同级别的禁止开发区综合赋值,并集之内的区域access就是我们所赋的值,并集之外的区域access值默认为1,禁止开发区包括:保护区、森林公园、湿地等等,这些数据通常涉密,如果有条件拿到更好,没有条件的这个选项就空着吧。
5.生境类型及生境类型对威胁的敏感性
也是一个csv格式的表格数据,名字命名为sensitivity.csv,跟上面的威胁因子数据一样,直接拿示例数据(图14)和某参考文献中的数据(图15左)对比一下就明白了。示例数据只有一级地类,参考文献中是二级地类,这个没什么影响,你自己手中的数据是几级地类就按照几级地类分。
简单说明一下示例数据中每一列需要填的内容,LULC填的是各地类编码,如果你的土地覆被数据有二级地类则填二级地类代码,比如耕地是一级地类,编码1,其二级地类又分旱地11和水田12,那么LULC这一列11和12都要填进去,NAME这一列就填入相应的编码所代表的地类名称,HABITAT这一列填各地物生境适宜度,这个数值综合各个文献确定即可,范围是0-1;前三个表头名:LULC、NAME、HABITAT,按照示例数据来,名字必须一模一样,后面的表头名是L_+各威胁源因子地类名,地类可以根据你手里的土地覆被数据里来命名,即L_xxx,比如:我这份土地覆被数据耕地是Cropland(图15右),则在表头里命名成L_Cropland,有几个威胁源就一次新建列命名几个,格式注意即可,至于列中需要填的数值,根据其他文献综合来确定。有一个需要注意的地方:你手里的土地覆被数据有多少个地类,都要写到表里去,不能因为适宜度都是0而不写,表格一定要做完整,否则在后面运行模型的时候会报错。比如你手里的土地覆被数据地类编码是1,2,3,4,5,6,7;而7代表的地类对应的所有生境适宜度都是0,那么0就是0,按照格式全都写到表里,如果因为是0而不写了只写了1,2,3,4,5,6,则运行模型的时候会报错,最终导致模型运行失败;参照图16中我运行模型时所做的完整表格(这是另外一套土地覆被数据,有二级地类)。

图14
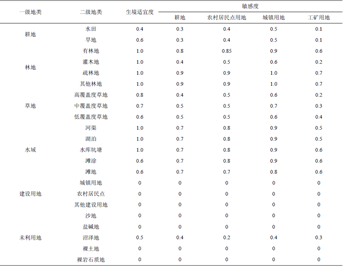
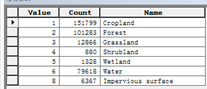
图15
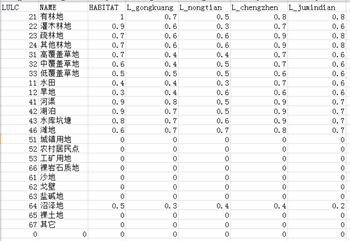
图16
6.半包和参数k值
就按照用户手册里定0.5好了。
其他说明
最后说一下各个数据之间的对应关系,①.threats.csv中的THREAT列与威胁源数据名字(xxx_c.tif)以及sensitivity.csv中的L_XXX对应,如图17所示,都是我做论文时处理的数据,感受一下。
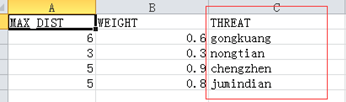
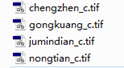

图17
②. sensitivity.csv中的LULC列与你手中的土地覆被数据中的地物编码要对应,顺序可以不对应,种类总量完全对应即可。
上述数据流程都处理完了就把各个数据输入然后等着结果出来就好了,结果会输出到output文件夹,quality_c_xx.tif就是生境质量结果,这里再说一句,因为之前做了nodata处理,最小外界矩形中除了正常的研究区范围其他范围值都是0,会对结果产生干扰,再拿研究区矢量数据裁剪一下即可。
其他的数据注意事项多看看用户手册即可,比如威胁源数据输入的是文件夹,因为威胁源数据可能不止一个,按照用户手册说明建立好文件目录就好,没什么坑了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号