

性能测试关于数据结果分析方法的一些总结
一、在和历史数据做对比时候,要注意环境的一致性,比如:
- 都是Stage环境
- 服务端是同样多的机器数量
- 客户端的机器的配置,如CPU/memory等
- 测试数据的一致性
二、测试方案的确定--由测试目的确定
- 跑API还是跑workflow?
- 并发用户数10?20?40?并发用户数的梯度?--可根据线上用户的情况确定。
- 跑哪些API?--根据用户的场景及代码的修改
三、测试数据分析-对于代码修改后,或者tomcate升级后评估对系统性能的影响。
- 测试数据的基准是什么?假如去年已经有性能测试的数据,在同样条件下当前数据和历史数据的对比,如果百分比,请求总数差距太大,考虑在当前新跑多轮数据后选择一个新的基准。
- 同一条件下跑出多组数据后,比较这多组数据的差距,如果内部数据差距大,是不考虑外在环境条件需要重跑后再对比。
- 是不是依赖的三方服务的条件不一致?跑脚本的时候第三方的任务是不都处理完了,比如转换任务
- 服务器条件不一致导致?CPU、Mermory是否降下来了等
- 历史产生了更多的脏数据导致?过程中产生了很多model/propsal数据等
- 网络条件导致?有没有链接VPN,服务器所在区域的影响等
- 不同的用户并发数下,RPS的对比,比如20并发下RPS是10,50并发下RPS也是10左右,这个时候就需要考虑是客户端或者服务端是不是有问题了。
- 客户端:从发的请求数去分析
- 服务端:从CPU、memory去分析,处理请求的机器的数量。
- 脚本运行一段时间后,RPS比较快的降低
- 对比历史数据,分析是否已经达到了并发用户瓶颈
- 是否是历史数据产生了影响,随着用户逐步增多,代码在执行接口的过程中,是不是查询某个接口的等待时间太长了,接口超时报错
- 同去年的数据对比,今年有某个接口的测试结果特别多
- 是不是今年的测试数据和去年不一致,比如在一次测试过程中,测试案例里面有30几个子文件,后来修改成1个子文件后,测试结果和历史基本接近了。
- 在运行不同用户并发数下,如果发现结果明显错的多了,需要第一去确认下服务器该服务的CPU和memory
- 如果在运行性能测试的过程中,遇到了某个错,开发一时半会也不能解决,但是又不想影响测试进度,考虑看是不可以先把这个错误的接口屏蔽,在基于这个基础上去跑出新的baseline和新的数据对比此次改动,当然要评估一下当前变更需测试的内容和当前屏蔽的接口之间的关系。
四、测试案例数据的一致性,否则可能会影响结果,比如对于download 相关的API,文件的大小会对响应时间产生明显的变化,这就需要考虑输入的测试案例的文件一定要是一致。
五、调试某接口的时候,也可以修改其API的比例权重,或者按照指定tag来跑等。
- 如何修改比例权重跑:
2. 如何修改tag跑:
env ConfigFile=us-stg-app.py /usr/local/bin/locust -f loadtest-app-api.py MssBIMAPI -T all #在这里 all就是tag的名称。
六、测试过程中关于error的分析
- 这个error在发布前(baseline)中是存在的吗?假设存在,那存在在接口数中的占比是多大呢?如果发布前和发布后这个数据占比的差距都不是很大,说明不是本次代码修改有影响,不需要在这个需求中针对性排查这个错误。
- 这个error在历年数据中是存在的吗?假设存在,存在的接口数的占比是多大,如果去年这个错占比很小,今年占比特别大,说明这个系统在去年到今年有退化,需要排查这个错误。
- 这个error在发布前和发布后中占比有比较大的变化吗?如果发布前后占比差别很大,说明此次代码变动对此有影响,需要排查这个错误。
- 这个error假设是今年新出现的,需要分析下这个错在什么场景下容易出现(和用户多少有没有关系),这个错误在今年每组新数据中的占比是多大,出现的频率高不高,如果进行了该场景下进行了多组测试,只有一组数据出现了,并且其他场景下并未出现这个错误,或许这个错误也是可以暂时忽略的。
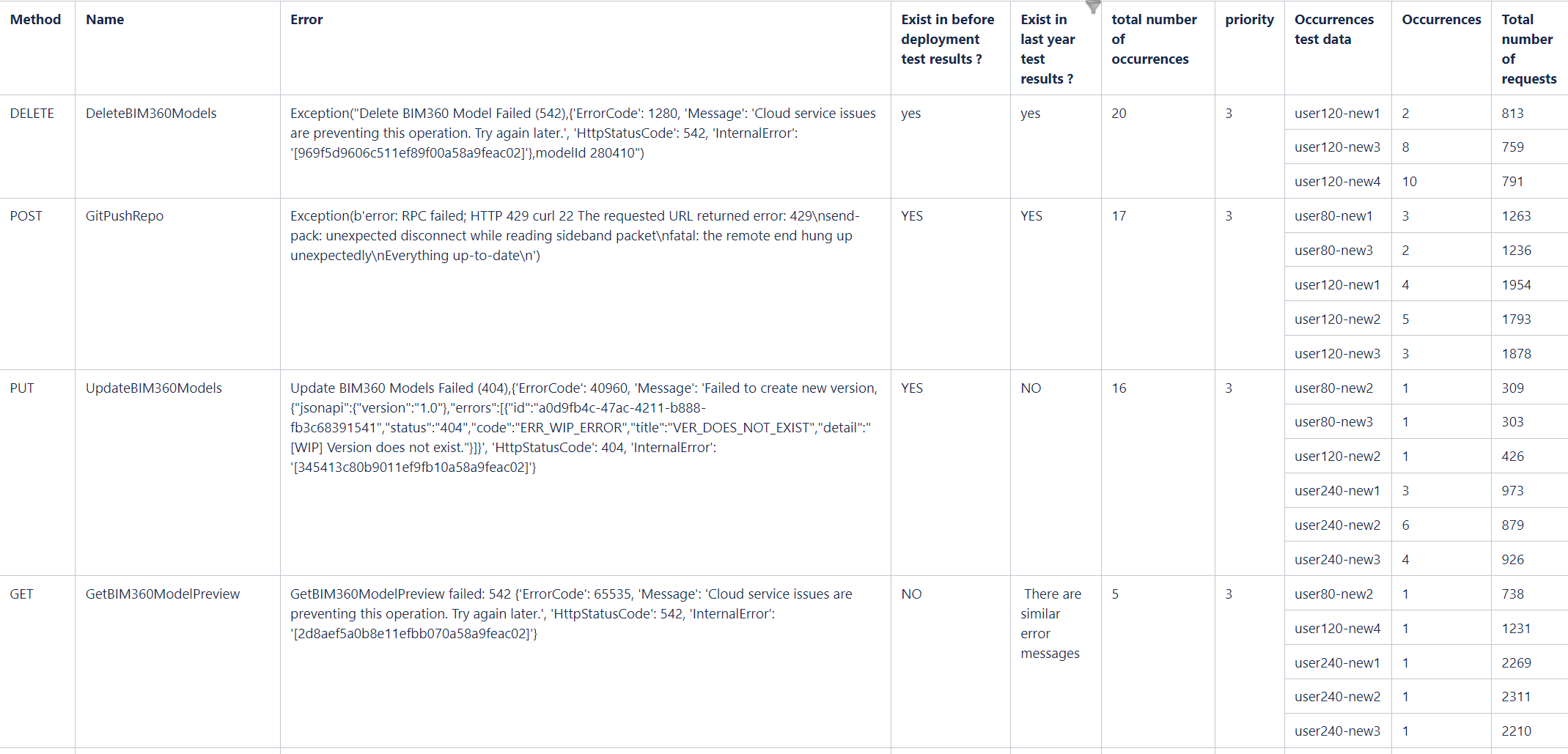
- 这里有一组分析错误举例:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现