
MySQL
javaEE:企业级java开发 Web
前端 (页面 :展示,数据! )
后台( 连接点:连接数据库JDBC ,链接前端(控制试图跳转,和给前端传递数据))
数据库( 存数据,Txt ,Excel ,word)
离散数学 ,数字电路 ,体系结构 ,编译原理 。
1.2为什么学习数据库
1.岗位需求
2.大数据时代 ,得数据者得天下
3.被迫需求:存数据
4.数据库是所有软件体系中最核心的存在 DBA
1.3 什么是数据库
概念:数据仓库,软件,安装在操作系统(window,linux,mac,……) 之上!SQL,可以存储大量的数据,500万!
作用:存储数据,管理数据
DB(数据库 )
DBMS(数据库管理系统)
1.4数据库分类
关系型数据库:(SQL)
-
MySQL ,Oracle ,Sql Server, DB2, SQLlite
-
通过表和表之间,行和列之间的关系进行数据的存储,学员信息表,……
非关系型数据库: (NO SQL) Not Only SQL
-
Redis , Mong DB
-
非关系型数据库,对象存储,通过对象的自身的属性来决定。
DBMS(数据库管理系统)
-
数据库的管理软件,科学有效的管理我们的数据.维护和获取数据:
-
MySQL,数据库管理系统
1.5 MySQL 简介
MySQL是一个 关系型数据库管理系统 ,
前世: 由瑞典MySQL AB 公司开发
今生:Oracle 旗下产品。
MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
开源的数据库软件
体积小,速度快,总体拥有成本低,招人成本比较低,所有人必须会~
中小型网站,或者大型网站,集群
1.6 安装MySQL
1.解压
2.把这个包放到自己的电脑环境目录下~
3.配置环境变量
4.新建MySQL配置文件ini
[mysqld]
basedir=C:\Program Files\Java\mysql-8.0.25\
datadir=C:\Program Files\Java\mysql-8.0.25\data\
port=3306
skip-grant-tables
5.启动管理员
………………
1.7 安装SQLyog
1.安装
2.注册
3.打开链接数据库
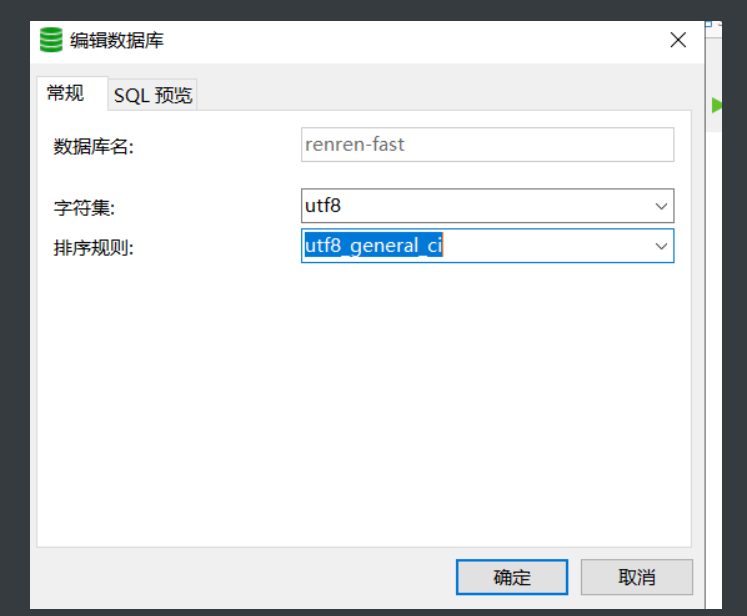
4.新建一个数据库 renren-fast
5.新建一个表
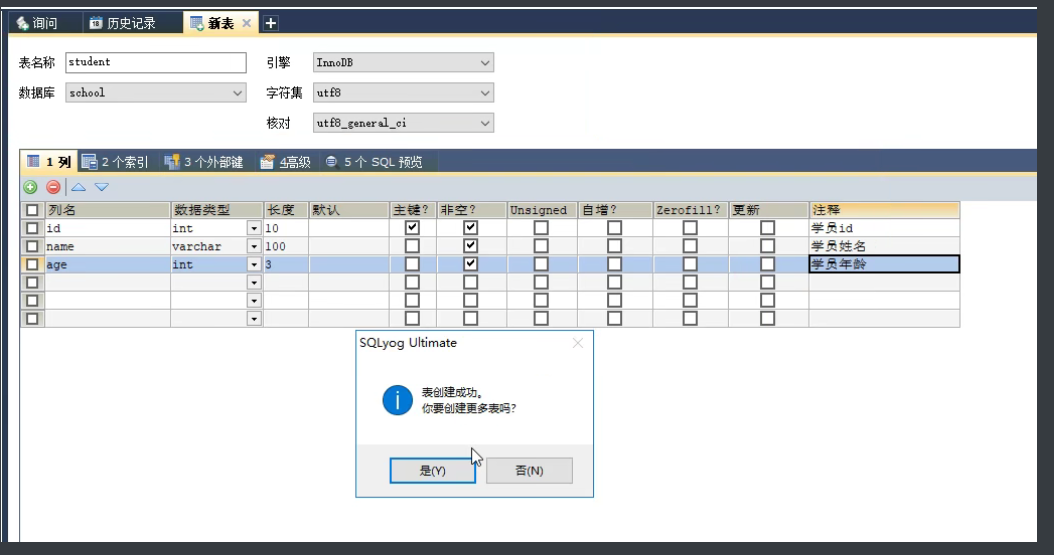
字段 : id . name .age
命令行
MySQL
show databases; --查看所有的数据库
mysql> use renren-fost --切换数据库中所用的表
describe student; --显示数据库中所有的表信息
crezte database westos; -- 创建一个数据库
exit ; --提出链接
--单行注释(sql 的 注释)
/*
多行注释
*/
数据库 xxx语言 CRUD 增删改查 !
DDL 定义
DML 操作
DQL 查询
DCL 控制
2.操作数据库
2.1操作数据库(了解)
1.创建数据
create database if not exists renren-fost
创建 数据库 存在 数据库名称
2.删除数据库
drop database if exists renren-fost
除名
3.使用数据库
---tab 上面 , 如果 你的表名或者字段名是一个特殊字符,就需要带``
use renren-fost
4.查看数据库
show database
2.2数据库的列类型
数值
-
tinyint 十分小的数据 1个字节
-
smalint 较小的数据 2个字节
-
mediumint 中等大小的数值 3个字节
-
int 标准的整数 4个字节
-
bigint 较大的数据 8个字节
-
float 浮点数 4个字节
-
double 浮点数 8个字节(精度问题!)
-
decimal 字符串形式的浮点数 金融计算的时候,一般是使用decimal
字符串
-
char 字符串固定大小的 0~255
-
varcher 可变字符串 0~65535 常用的变量 String
-
tinytext 微型文本 2^8 -1
-
text 文本串 2^16 -1 保存文本
时间日期
java.util.Date
-
date YYY-MM-DD, 日期格式
-
time HH: mm: ss: 时间格式
-
datetime YYYY-MM-DD HH: mm: ss 最常用的时间格式
-
timestamp 时间戳 , 1970.1.1 到现在的毫秒数! 也较为常用!
-
yeear 年份表示
null
-
没有值 ,
-
注意,不要使用NULL进行运算,结果为NULL
2.3数据库的字段属性(重点)
Unsigned :
-
无符号的整数
-
声明该列不能声明为负数
zerofill:
-
0填充的
-
不足的位置,使用0来填充, int(3), 1 --001
自增: AUTO_INCREMENT
-
通常理解为自增,自动在一条记录的基础上+1 (默认)
-
通常用来设计唯一的主键~ index , 必须整数类型
-
可以自定义设计主键自增的起始值和步长
非空 null not null
-
假设设置为 not null ,如果不给它赋值,就会报错!
-
null ,如果不填写值,默认就是null
默认:DEFAULT
-
设置默认值!
-
sex,默认值 为男,如果不指定该列的值,则会有默认的值!
注释:comment
/*
每个表,都必须存在一下五个字段! 未来做项目用的,表示一个记录存在意义!
id 主键
version 乐观锁
is_delete伪删除
gmt_create 创建时间
gmt_update 修改时间
*/
2.4创建数据库(重点)
--目标:创建一个数据库
/*
创建一个学生表(列,字段)使用SQL 创建
学号int 登录密码varcher(20) 姓名,性别varcher(2), 出生日期(datatime),家庭地址 ,email
注意点 使用英文() ,表的名称 和 字段 尽量使用 `` 括起来
字符串使用单引号括起来!
所有语句后面加, (英文的),最后一个不用加
*/
create TABLE if NOT exists `student`(
`id`INT(10) NOT NULL AUTO_INCREMENT COMMENT'学号',
`NAME` VARCHAR(10) NOT NULL DEFAULT '匿名' COMMENT'姓名',
`pwd`INT(10) NOT NULL DEFAULT(123456) COMMENT'密码',
`sex`VARCHAR(2) NOT NULL DEFAULT'男' COMMENT'性别',
`birthday` DATETIME DEFAULT NULL COMMENT'出生日期',
`address` VARCHAR(100) DEFAULT NULL COMMENT'家庭地址',
`email` VARCHAR(50) DEFAULT NULL COMMENT'邮箱',
PRIMARY KEY (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
格式:
create TABLE [if NOT exists] `student`(
'字段名' 列类型 [属性] [索引] [注释]
………………
……
)
常用命令
show create database 表明 --查看创建数据库的语句
show create table 表名 -- 查看表数据表的定义语句
desc 表名 --显示表的结构
2.5数据库的类型
-- 关于数据库引擎
/*
INNODB 默认使用~
MYISAM 早些年使用
*/
| MYISM | INNODB | |
|---|---|---|
| 事物支持 | 不支持 | 支持 |
| 数据行锁定 | 不支持 | 支持 |
| 外键约束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空间的大小 | 较小 | 较大,约2倍 |
常规使用操作:
-
MYISM 节约空间,速度较快
-
INNODB 安全性高 ,事物的处理,多表多用户操作
在物理空间存在的位置
所有的数据库文件都存在 data目录下
本质还是文件的存储!
MySQL 引擎在物理文件上的区别
-
INNODB在数据库表中只有一个*.frm文件,以及上级目录下的 ibdata1文件
-
MYISAM 对应文件
-
*.frm 表结构的定义文件
-
*.MYD 数据文件(data)
-
*.MYI 索引文件(idex)
-
设置数据库表的字符集编码
1.CHARSET=utf8
不设置的话,会是mysql 默认的字符集编码~(不支持中文!)
MySQL默认编码是Latin1,不支持中文
在my.ini中配置默认的编码
character-set-server=utf8
2.6修改和删除表
修改
--修改表名: ALTER TABLE 旧表名 rename AS 新表名
ALTER TABLE student rename AS student1
奥特
--增加表的字段: ALTER TABLE 表名 ADD 字段名 列属性
ALTER TABLE student ADD age INT(3)
--修改表的字段(重命名,修改约束!)
--ALTER TABLE 表名 MODIFY 字段名 列属性 []
ALTER TABLE student MODIFY age varchar(11) --修改约束
--ALTER TABLE 表名 change 旧名字 新名字 列属性[]
ALTER TABLE student change age age1 int(1)--字段重命名
--删除表的字段 :ALTER TABLE 表名 DROP 字段名
ALTER TABLE student DROP age1
删除
--删除表(如果表纯在在删除)
drop table if exists student1
3Mysql 数据管理
3.1 外键(了解即可)
方式一 : 在创建表的时候,增加约束(比较麻烦)
create table grade(
`gradeid` int(10) not null auto_increment comment'年级id',
`gradename` varchar(5) not null comment'年级名称',
PRIMARY KEY (`gradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
/*
学生表的gradeid 字段 要去引用年级表的 gradeid
定义外键key
给这个外键添加约束(执行引用) references引用
*/
CREATE TABLE if not exists `student` (
`id` int(10) NOT NULL auto_increment COMMENT 'id',
`NAME` varchar(10) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` int(10) NOT NULL DEFAULT (123456) COMMENT '密码',
`sex` varchar(2) NOT NULL DEFAULT '男' COMMENT '性别',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`address` varchar(100) DEFAULT NULL COMMENT '家庭地址',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`),
key `fk_gradeid` (`gradeid`),
constraint `fk_gradeid` foreign key (`gradeid`) references `grade`(`gradeid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
删除有外键关系的表的时候,必须要先删除引用别人的表(从表),在删除被引用的表(主表)
方法二:创建表成功后,添加外键约束
--创建表的时候没有外键关系
ALTER TABLE 'student'
ADD constraint `fk_gradeid` foreign key (`gradeid`) references `grade`(`gradeid`)
--alte table 表 add constraint 约束名 foreign key (作为外键的列) references 那个表(那个字段)
3.2DML语言(全部背下来)
数据库意义:数据存储,数据管理
DML语言:数据操作语言
-
insert
-
upadte
-
delete
3.3添加
insent
/*
插入语句(添加)
insert int 表名([字段名1 ,字段2,字段3])values('值1')('值2')('值3')
*/
insert into `grade`(`gradename`) values('大2')
/*
点击一下运行一下啊
由于主键自增 我们可以省略(如果不写表的字段 ,他就会一一匹配)
一般写插入的语句,我们一定要数据和字段一一对应 !
插入多个字段
*/
insert into `grade`(`gradename`) values ('大二')('大一')
insert into `student`(NAME`) values ('大一')
insert into `student`(`name`,`pwd`,`sex`) VALUES ('张三','aaaa','男')
insert into `student`(`name`,`pwd`,`sex`) values ('李四','AAAAA','男')
语法 : insert into 表名 ([字段名1, 字段2, 字段3]) values ('值1'),('值2'),('值3',.......)
注意事项
-
字段和字段之间使用英文逗号隔离
-
字段是可以省略的, 但是后面的值必须要一一对应,不能少
-
可以同时插入 多条数据,values后面的值,需要使用 , 隔开即可 values (),(),..............
3.4修改
update 修改谁 (条件) set 原来的值=新值
/*
修改学员的 名字 ,
*/
update `student` set `name`='小儿子' where id= 1;
/*
不指定的情况下,会改变所有的表
*/
update `student` set `name`='小儿子'
/*
修改多个属性,逗号隔开
*/
update `student` set `name`='小儿子',`email`='257105791@qq.com',`birthday`='2000-02-01' where id= 1;
/*
语法
update 表名 set colnum_name =value ,[colnum_name=value.....] where [条件]
*/
条件 :where 子句 运算符 id 等于 某个值,大于某个值,在某个区间内修改......
操作符会返回 布尔值
| 操作符 | 含义 | 范围 | 结果 |
|---|---|---|---|
| = | 等于 | false | |
| <>或!= | 不等于 | true | |
| > | |||
| < | |||
| >= | |||
| <= | |||
| between | 在某个范围内 | ||
| and | 我和你 && | ||
| o'r | 我或你 || |
/*
通过多个条件锁定
*/
update `student` set `name` ='小儿子' where `name`='大儿子' and sex='男'
注意 :
-
colnm_name 是数据库的列 ,尽量带上``
-
条件,筛选的条件 ,如果没有指定,则会修改所有的列
-
value ,是一个具体的值 ,也可以是一个变量
-
多个设置的属性之间,使用英文 逗号隔开
3.5删除
delete 命令
语法: delete from 表名 [where 条件]
/*
删除数据(避免这样写,会全部删除)
*/
delete from `student`
-- 删除 指定 数据
delete from `student` where id=1;
truncate 命令
作用:完全清空一个数据库,表的结构和索引约束不会变,
-- 清空 student 表
truncate `student`
delete 和 truncate 的区别
-
相同点:都能删除数据, 都不会删除表结构
-
不同
-
trunctae 重新设置自增列 计数器会归零
-
turncate 不会影响事物
-
了解即可
delete 删除问题,重启数据库,现象
innodb 自增列会重1开始 (存在内存当中,断电丢失)
MyISAM 继续从上一个自增量开始 (存在文件中的,不会丢失)
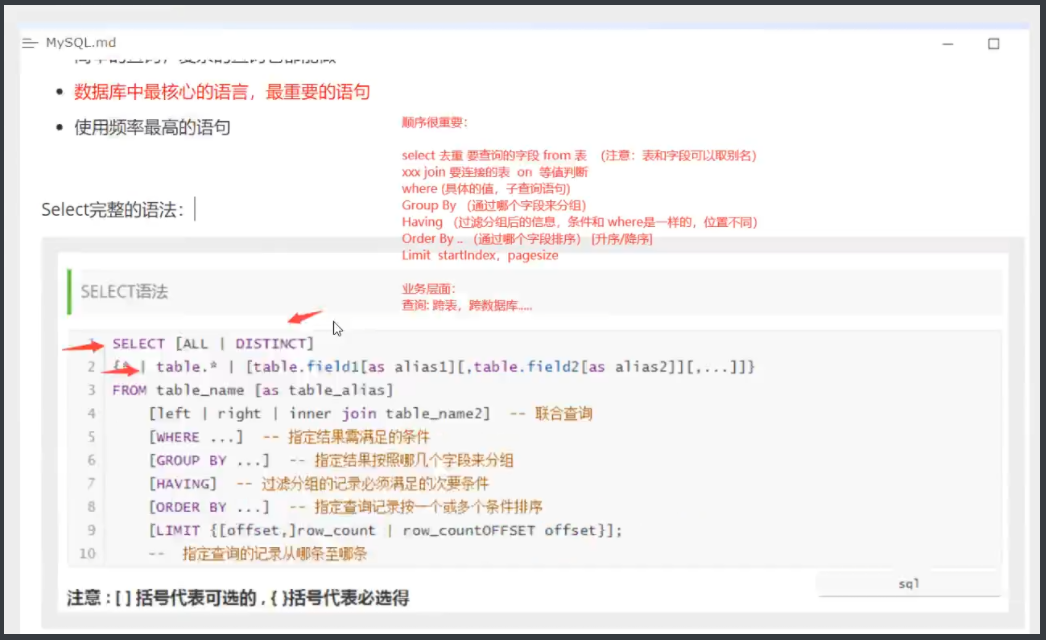
4.DQL查询 数据(重点)
4.1DQL
(Data Query LANGUAGE:数据库查询语言)
-
所有的查询操作都用他 Select
-
简单的查询,复杂的查询它都能作到~
-
数据库中核心的语言,最重要的语句
-
使用频率最高的语句
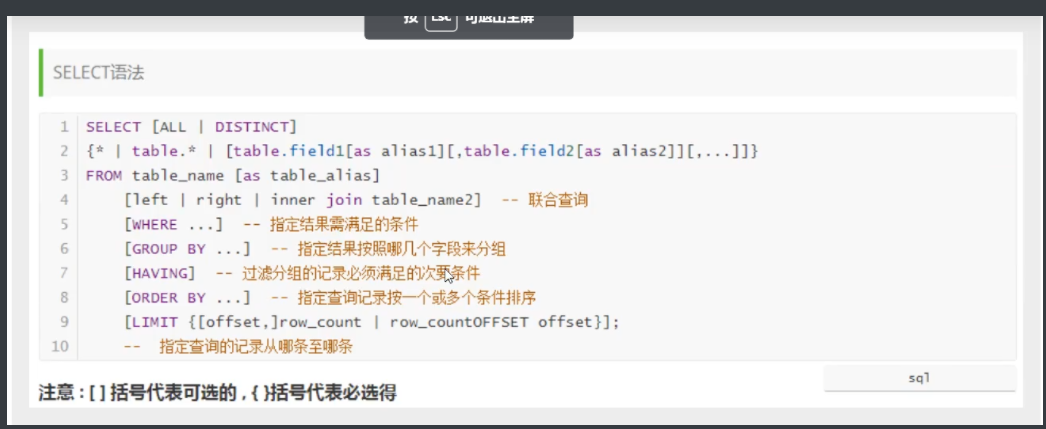
4.2指定查询字段
--查询全部的学生 select 字段 from 表
select * from student
--查询 指定的 字段
select `Student`,`Student` from student
--别名, 给结果起一个名字 AS 可以给字段起别名 ,也可以给表起别名
Select `stedent` AS 学号, `StudentName` AS 学生姓名 from Student
--函数 concat (a,b) 起到拼接的作用
Select concat('姓名',StudentName) AS 新名字 From Student
语法:select 字段 .... from 表
有的时候,列名字不是那么的见名之意,我们起别名 AS 字段名 AS 别名 表名 AS 别名
去重 distinct
作用 :去除select 查询出来的结果中重复的数据,重复的数据只显示一条
--查询 一下有哪些同学参加了考试,成级
select *from result --查询全部的考试成绩
select `Studentno` from result --查询有哪些同学参加了考试
select distinct `studentno`from result --发现重复数据,去重
数据库的列(表达式)
select version() --查询版本
select 100*31-1 AS 计算结果 --用来技术(表达式)
select @@auto_increment_increment --查询自增的布长(变量)
--学员考试成绩 -1
select `studentno`,`studentresult`-1 AS '提分后'from sesult
数据库中的表达式:文本值,列 ,null,函数,计算表达式, 系统变量....
select 表达式 from 表
4.3where条件子句
作用:检索数据中的符合条件的值
搜索的条件由一个或者多个表达试组成!结果布尔值
逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | 和 | |
| or || | 或 | |
| not != | 取反 |
select studentno, `Student` from result
--查询考试成绩在 95--100之间
select studentno, `StudentResult` from result
where studentresult>=95 and studentresult<=100
--and &&
select studentno,'studentresult' from result
where studentresult>=95 && studentresult<=100
--模糊查询(区间)
select student , 'studentresult' from result
where studentresult between 95 and 100
--除了1000号学生之外的同学的成绩
select studentno, `studentresult` from reslut
where studentnNO !=1000;
-- != not
select studentno, ·`studentresult` from result
where not studentno =1000
模糊查询 :比较运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为null,结果为真 |
| IS NOT NULL | a is not null | 如果操作符不为null,结果为真 |
| BETWEEN | a between b and c | 若a在b 和c之间 ,结果为真 |
| Like | a like b | SQL匹配,如果a匹配b,则结果为真 |
| in | a in (a1,a2,a3.....) | 假设a在a1,或者a2...其中的某一个值中,结果为真 |
=============模糊查询=========
--查询姓刘的同学
--like结合 %(代表0到任意个字符) _(一个字符)
select `studentNO`,`studentname` from `student`
where studentname like '刘%'
--查询姓刘的同学,名字后面只有一个字的
select `studemtno`,`student` from `student`
where studentname like '刘_'
--查询姓刘的同学,名字后面只有两个字的
select `studemtno`,`student` from `student`
where studentname like '刘__'
--查询名字中间有嘉字的同学 %嘉%
select `studemtno`,`student` from `student`
where studentname like '%嘉%'
--in (具体的一个或多个值)=======
--查询 1001,1002,1003, 号学员
select `studemtno`,`student` from `student`
where studentname in (1001,1002,1003);
--查询在北京的同学
select `studemtno`,`student` from `student`
where `adderss` in('安徽',)--里面要填具体地址
--null not null ==
--查询地址为空的学生 null ''
select `studemtno`,`student` from `student`
wshere address='' or address is null
--查询有出生日期的同学 不为空
select `studemtno`,`student` from `student`
where `BornDate` IS not null
--查询没有出生日期的同学 为空
select `studemtno`,`student` from `student`
where `dorndate` is null
4.4 联表查询
JION
-- ============== 联表查询 jion ===========
-- 查询参加了考试 的同学(学号,姓名 ,科目编号 ,分数)
select * from result
select * from student
/*
思路
1.分析需求,分析查询的字段来自哪些表,(链接查询)
2.确定使用那种链接查询? 一共7种
确定交叉点(这两个表中那个数据是相同的)
判断的条件:学生表中的 studentNO = 成绩表 student No
*/
select s.studentNO,studentName,SubjectNo,StudentResult -- 选择合并的项目
FROM student AS S
INNER JOIN result AS r -- AS 给表重新命名
ON s.studentNO = r.studentNO
-- Right Jion
select s.studentNO,studentName,SubjectNo,StudentResult
FROM student S
Right JOIN result r -- 空格 也可以 给表重新命名
ON s.studentNO = r.studentNO
-- Left Jion
select s.studentNO,studentName,SubjectNo,StudentResult
FROM student S
Right JOIN result r
ON s.studentNO = r.studentNO
| 操作 | 描述 |
|---|---|
| inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right jion | 会从右表中返回所有的值,即使左表中没有匹配 |
-- jion (连接的表) on (判断的条件) 链接查询
-- where 等值查询
-- 查询缺考的同学
select s.studentNO,studentName,SubjectNo,StudentResult
FROM student S
left JOIN result r
ON s.studentNO = r.studentNO
where StudentResult is null
-- 查询参加了考试 的同学(学号,姓名 ,科目编号 ,分数)
select s.studentNO,studentName,SubjectNo,StudentResult
FROM student S
right JOIN result r
ON r.studentNO = s.studentNO
inner join 'student' A
ON r.studentNO = A.studentNO
/*
我们要查询那些数据 select ..
从那几个表中查 from 表 xxx join 链接的表 on 交叉条件
假设存在 一种多张表查询 ,先查询两张表然后在增加
*/
自链接
自己的表和自己的表链接,核心: 一张表拆为两张一样的表即可
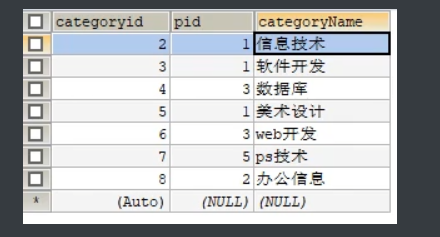
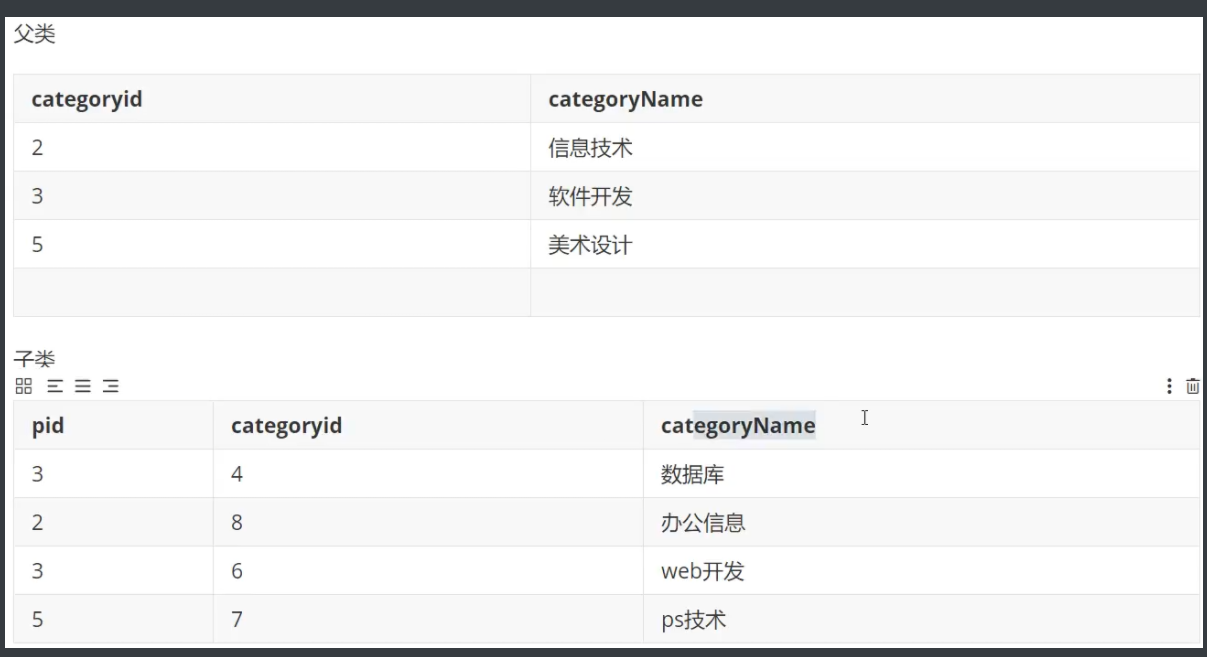
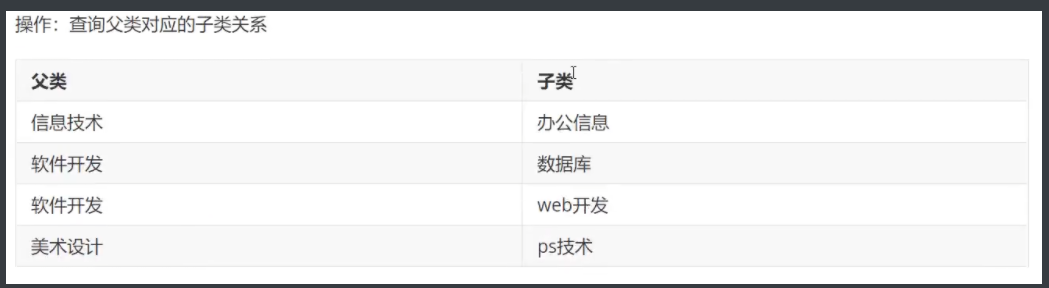

4.5 分页和排序
排序
-- 排序 : 升序 ASC , 降序 DESC
-- order by 通过哪个字段排序,怎么排
-- 查询的结果根据 成绩降序 排序
select s.'Studetno','StudentName','SubjectName','StudentRecult'
from student s
inner join 'result' r
ON s.StudentNo = r.StudentNO
inner Join 'subject' sub
ON r.'SubjectNo' = sub .'SubjectNO'
where subjectName ='数据库-1'
ORDER BY studentresult ASC
分页
-- 好处 缓解数据库压力,给人的体验更好,
-- 还有 一种是 瀑布流
-- 分页,每页只显示五条数据
-- 语法:limit 起始值,页面大小
-- 页面应用:当前,总的页数,页面的大小
-- limit 0,5 1~5
-- limit 1,5 2~6
-- limit 6,5
select s.'Studetno','StudentName','SubjectName','StudentRecult'
from student s
inner join 'result' r
ON s.StudentNo = r.StudentNO
inner Join 'subject' sub
ON r.'SubjectNo' = sub .'SubjectNO'
where subjectName ='数据库-1'
ORDER BY studentresult ASC
limit 5,5
-- 第一页 limit 0,5 (1-1)*5
-- 第二页 limit 5,5 (2-1)*5
-- 第三页 limit 10-5 (3-1)*5
-- 第N页 limit 0,5 (n-1)*pageSize,pageSize
-- [Pagesize : 页面大小]
-- [(n-1)*pagesize:起始值]
-- [n : 当前页]
-- [数据总数/页面大小 =总页数]
4.6子查询
/*============== 子查询 ================
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
*/
-- 查询 数据库结构-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列
-- 方法一:使用连接查询
SELECT studentno,r.subjectno,StudentResult
FROM result r
INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE subjectname = '数据库结构-1'
ORDER BY studentresult DESC;
-- 方法二:使用子查询(执行顺序:由里及外)
SELECT studentno,subjectno,StudentResult
FROM result
WHERE subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = '数据库结构-1'
)
ORDER BY studentresult DESC;
-- 查询课程为 高等数学-2 且分数不小于80分的学生的学号和姓名
-- 方法一:使用连接查询
SELECT s.studentno,studentname
FROM student s
INNER JOIN result r
ON s.`StudentNo` = r.`StudentNo`
INNER JOIN `subject` sub
ON sub.`SubjectNo` = r.`SubjectNo`
WHERE subjectname = '高等数学-2' AND StudentResult>=80
-- 方法二:使用连接查询+子查询
-- 分数不小于80分的学生的学号和姓名
SELECT r.studentno,studentname FROM student s
INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
WHERE StudentResult>=80
-- 在上面SQL基础上,添加需求:课程为 高等数学-2
SELECT r.studentno,studentname FROM student s
INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
WHERE StudentResult>=80 AND subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = '高等数学-2'
)
-- 方法三:使用子查询
-- 分步写简单sql语句,然后将其嵌套起来
SELECT studentno,studentname FROM student WHERE studentno IN(
SELECT studentno FROM result WHERE StudentResult>=80 AND subjectno=(
SELECT subjectno FROM `subject` WHERE subjectname = '高等数学-2'
)
)
/*
练习题目:
查 C语言-1 的前5名学生的成绩信息(学号,姓名,分数)
使用子查询,查询郭靖同学所在的年级名称
*/
4.7、分组和过滤
题目:
-- 查询不同课程的平均分,最高分,最低分 ,平均分大于80
-- 前提:根据不同的课程进行分组
SELECT subjectname,AVG(studentresult) AS 平均分,MAX(StudentResult) AS 最高分,MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOIN `subject` AS s
ON r.subjectno = s.subjectno
GROUP BY r.subjectno
HAVING 平均分>80;
/*
where写在group by前面.
要是放在分组后面的筛选
要使用HAVING..
因为having是从前面筛选的字段再筛选,而where是从数据表中的>字段直接进行的筛选的
*/
4.8select总结
5.Mysql函数
5.1常见 函数
1.数据函数
SELECT ABS(-8); /*绝对值*/
SELECT CEILING(9.4); /*向上取整*/
SELECT FLOOR(9.4); /*向下取整*/
SELECT RAND(); /*随机数,返回一个0-1之间的随机数*/
SELECT SIGN(0); /*符号函数: 负数返回-1,正数返回1,0返回0*/
2.字符串函数
SELECT CHAR_LENGTH('狂神说坚持就能成功'); /*返回字符串包含的字符数*/
SELECT CONCAT('我','爱','程序'); /*合并字符串,参数可以有多个*/
SELECT INSERT('我爱编程helloworld',1,2,'超级热爱'); /*替换字符串,从某个位置开始替换某个长度*/
SELECT LOWER('KuangShen'); /*小写*/
SELECT UPPER('KuangShen'); /*大写*/
SELECT LEFT('hello,world',5); /*从左边截取*/
SELECT RIGHT('hello,world',5); /*从右边截取*/
SELECT REPLACE('狂神说坚持就能成功','坚持','努力'); /*替换字符串*/
SELECT SUBSTR('狂神说坚持就能成功',4,6); /*截取字符串,开始和长度*/
SELECT REVERSE('狂神说坚持就能成功'); /*反转
-- 查询姓周的同学,改成邹
SELECT REPLACE(studentname,'周','邹') AS 新名字
FROM student WHERE studentname LIKE '周%';
日期和时间函数
SELECT CURRENT_DATE(); /*获取当前日期*/
SELECT CURDATE(); /*获取当前日期*/
SELECT NOW(); /*获取当前日期和时间*/
SELECT LOCALTIME(); /*获取当前日期和时间*/
SELECT SYSDATE(); /*获取当前日期和时间*/
-- 获取年月日,时分秒
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT HOUR(NOW());
SELECT MINUTE(NOW());
SELECT SECOND(NOW());
3.系统信息函数
SELECT VERSION(); /*版本*/
SELECT USER(); /*用户*/
5.2聚合函数
| 函数名称 | 描述 |
|---|---|
| COUNT () | 计数 |
| SUM | 求和 |
| AVG | 平均值 |
| MAX | 最大值 |
| MIN | 最小值 |
函数名称描述COUNT()返回满足Select条件的记录总和数,如 select count(*) 【不建议使用 *,效率低】SUM()返回数字字段或表达式列作统计,返回一列的总和。AVG()通常为数值字段或表达列作统计,返回一列的平均值MAX()可以为数值字段,字符字段或表达式列作统计,返回最大的值。MIN()可以为数值字段,字符字段或表达式列作统计,返回最小的值。 -- 聚合函数
/*COUNT:非空的*/
SELECT COUNT(studentname) FROM student;
SELECT COUNT(*) FROM student;
SELECT COUNT(1) FROM student; /*推荐*/
-- 从含义上讲,count(1) 与 count(*) 都表示对全部数据行的查询。
-- count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
-- count(*) 包括了所有的列,相当于行数,在统计结果的时候,包含字段为null 的记录;
-- count(1) 用1代表代码行,在统计结果的时候,包含字段为null 的记录 。
/*
很多人认为count(1)执行的效率会比count(*)高,原因是count(*)会存在全表扫描,而count(1)可以针对一个字段进行查询。其实不然,count(1)和count(*)都会对全表进行扫描,统计所有记录的条数,包括那些为null的记录,因此,它们的效率可以说是相差无几。而count(字段)则与前两者不同,它会统计该字段不为null的记录条数。
下面它们之间的一些对比:
1)在表没有主键时,count(1)比count(*)快
2)有主键时,主键作为计算条件,count(主键)效率最高;
3)若表格只有一个字段,则count(*)效率较高。
*/
SELECT SUM(StudentResult) AS 总和 FROM result;
SELECT AVG(StudentResult) AS 平均分 FROM result;
SELECT MAX(StudentResult) AS 最高分 FROM result;
SELECT MIN(StudentResult) AS 最低分 FROM result;
5.3数据库级别的MD5加密(扩展)
一、MD5简介
1.什么是MD5?
2.主要增强算法复杂和不可逆性
3.MD5不可逆,具体的值的 MD5是一样的
4.MD5 破解网站的原理 ,背后有一个字典,MD5加密后的值,加密前的值
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。将数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和MD4。
-- ========= 测试MD5 加密 =========
-- 新建一个表 testmd5
CREATE TABLE `testmd5` (
`id` INT(4) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`pwd` VARCHAR(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
插入一些数据
-- 明文密码
INSERT INTO testmd5 VALUES(1,'kuangshen','123456'),(2,'qinjiang','456789')
如果我们要对pwd这一列数据进行加密,语法是:
update testmd5 set pwd = md5(pwd); -- 也可以 Where id 选则一个或几个进行加密
如果单独对某个用户(如kuangshen)的密码加密:
INSERT INTO testmd5 VALUES(3,'kuangshen2','123456')
update testmd5 set pwd = md5(pwd) where name = 'kuangshen2';
插入新的数据自动加密
INSERT INTO testmd5 VALUES(4,'kuangshen3',md5('123456'));
查询登录用户信息(md5对比使用,查看用户输入加密后的密码进行比对)
SELECT * FROM testmd5 WHERE `name`='kuangshen' AND pwd=MD5('123456');
5.4小结
-- ================ 内置函数 ================
-- 数值函数
abs(x) -- 绝对值 abs(-10.9) = 10
format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46
ceil(x) -- 向上取整 ceil(10.1) = 11
floor(x) -- 向下取整 floor (10.1) = 10
round(x) -- 四舍五入去整
mod(m, n) -- m%n m mod n 求余 10%3=1
pi() -- 获得圆周率
pow(m, n) -- m^n
sqrt(x) -- 算术平方根
rand() -- 随机数
truncate(x, d) -- 截取d位小数
-- 时间日期函数
now(), current_timestamp(); -- 当前日期时间
current_date(); -- 当前日期
current_time(); -- 当前时间
date('yyyy-mm-dd hh:ii:ss'); -- 获取日期部分
time('yyyy-mm-dd hh:ii:ss'); -- 获取时间部分
date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- 格式化时间
unix_timestamp(); -- 获得unix时间戳
from_unixtime(); -- 从时间戳获得时间
-- 字符串函数
length(string) -- string长度,字节
char_length(string) -- string的字符个数
substring(str, position [,length]) -- 从str的position开始,取length个字符
replace(str ,search_str ,replace_str) -- 在str中用replace_str替换search_str
instr(string ,substring) -- 返回substring首次在string中出现的位置
concat(string [,...]) -- 连接字串
charset(str) -- 返回字串字符集
lcase(string) -- 转换成小写
left(string, length) -- 从string2中的左边起取length个字符
load_file(file_name) -- 从文件读取内容
locate(substring, string [,start_position]) -- 同instr,但可指定开始位置
lpad(string, length, pad) -- 重复用pad加在string开头,直到字串长度为length
ltrim(string) -- 去除前端空格
repeat(string, count) -- 重复count次
rpad(string, length, pad) --在str后用pad补充,直到长度为length
rtrim(string) -- 去除后端空格
strcmp(string1 ,string2) -- 逐字符比较两字串大小
-- 聚合函数
count()
sum();
max();
min();
avg();
group_concat()
-- 其他常用函数
md5();
default();
6.事务
6.1什么是 事务
要么都成功要么都失败
事务原则:ADIC 原则 原子性,一致性 ,隔离性,持久性 (脏读 ,幻读……)

1.原子性(Atomicity)
要么都成功 , 要么都失败
2.一致性(consistency)
事物前后的数据完整性要保证一致,1000
3.持久性(Durability)--事物提交
事物一旦提交则不可逆,被持久化到数据库中!
4.隔离性(lsolation)
事物的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事物的操作数据所干涉事务之间要相互隔离
隔离所导致的一些问题
脏读
指一个事务读取了另一个事务未提交的数据
不可重复读
在一个事务内读取表中的某一行数据,多次读取结果不同.(这个不一定是错误,只是某些场合不对)
虚读(幻读)
是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致.
执行事务
-- ====================== 事务 =======================
-- mysql 是默认开启事务自动提交的
set autocommit = 0 -- 关闭
set autocommit = 1 -- 开启 (默认的)
-- 手动处理事务
set autocommit = 0 -- 关闭自动提交 处理事务的第一布
-- 事务开启
start transation -- 标记一个事务的开始,从这个之后的sql 都在同一个事务内
insert xx
insert xx
-- 提交:持久化(成功!)
commit
-- 回滚:回到的原来的样子(失败!)
rollback
-- 事务结束
set autocommit = 1 -- 开启自动提交 结束时候开启
-- (常识)
savepoint 保存点名 -- 设置一个事务的保存点
rollback to saveepoint 保存点名 -- 回滚到保存点
release savepoint 保存点名 -- 撤销保存点
模拟转账情景
-- 转账
CREATE DATABASE `shop`CHARACTER SET utf8 COLLATE utf8_general_ciUSE `shop`
CREATE TABLE `account` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(32) NOT NULL,
`money` DECIMAL(9,2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO account (`name`,`money`)
VALUES('A',2000.00),('B',10000.00)
-- 转账实现
SET autocommit = 0; -- 关闭自动提交
START TRANSACTION; -- 开始一个事务,标记事务的起始点
UPDATE account SET money=money-500 WHERE `name`='A';
UPDATE account SET money=money+500 WHERE `name`='B';
COMMIT; -- 提交事务
rollback; -- 回滚
SET autocommit = 1; -- 恢复自动提交
7.索引
索引的作用: 1.提高查询速度 2.确保数据的唯一性 3.是帮助Mysql 高效获取数据的数据结构
提取句子主干,就可以得到索引的本质:索引是数据结构
7.1 索引的分类
在一个表中 ,主键索引只能 有一个,唯一索引可以有多个
-
主键索引 (Primary Key)
-
唯一的标识 ,主键不可重复,只能有一个列作为主键
-
-
唯一索引 (Unique Key)
-
避免重复的列出现, 唯一索引可以重复,多个列都可以标识 唯一索引
-
-
常规索引 ( Index/key )
-
默认的,index. key 关键字来设置
-
-
全文索引 (FullText)
-
在特定的数据库引擎下才有 , MyISAM
-
-
快速定位数据
基础语法
-- 索引的使用
-- 1.在创建表的时候给字段增加索引
-- 2.创建完毕后, 添加索引
-- 显示所有的索引消息
SHOW INDEX from student
-- 增加一个全文索引 (索引名) 列名
alter table school.student ADD fulltext index `studentName`(`studentName`);
-- Explain 分析sql 执行的状况
explain select * FROM student ;-- 非全文索引
explain select * from student WHERE match(studentName) AGAINST('李')
7.2 测试索引
索引在小数据量的时候,用户不大,但是在大数据的时候,区别十分明显~
7.3索引原则
-
索引不是越多越好
-
不要对进程 变动的数据 加索引
-
小数据量的表不需要加索引
-
索引一般加在常用来查询的字段上!
索引的数据结构
Hash 类型的索引
btree:innoDB 的默认数据结构~

8.权限管理和备份
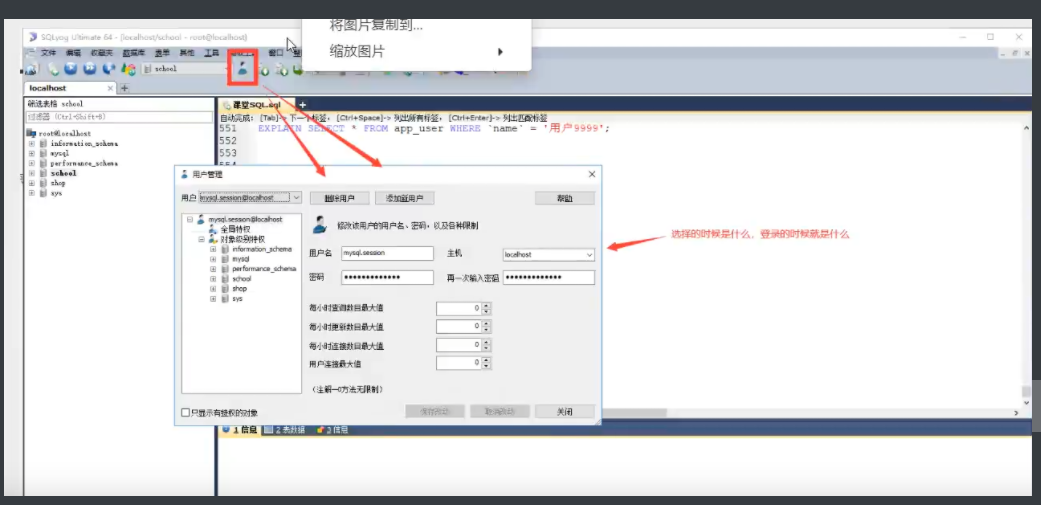
8.1 用户管理
SQL yog 可视化管理
SQL 命令操作
用户表:mysql .user
本质 :读这张彪进行增删改查
-- 创建用户 CREATE USER 用户名 IDENTIFIED BY '密码'
create user student IDENTIFIED '123456'
-- 修改密码 (修改当前用户密码)
SET PASSWORD = password('123456')
-- 重命名 rename user 原来名字 TO 新的名字
RENAME USER student to studentname
-- 用户授权 ALL privileges 全部的权限 ,库 , 表
-- ALL privileges 除了给别人授权,其他都能够干
grant all privileges on *.* to studentname
-- 查询权限
show grants for studentname -- 查看指定用户的权限
show grants for root@localhost
-- root 用户权限 : GRANT all PRIVILEGES ON *.* TO 'root'@ 'localhost' with grant option
-- 撤销权限 Revoke 哪些权限 ,在哪个库撤销 , 给谁撤销
PEVOKE ALL PRIVILEGES *.* FROM studentname
-- 删除用户
drop user stdent
8.2 MySQL 备份
为什么要备份:
-
保证重要的数据不丢失
-
数据转移
Mysql数据库备份的文件
-
直接 拷贝物理文件
-
在Sqlyog 这种可视化工具手动导出
-
在想要导出的表或者库中,右键,选择备份或导出
-
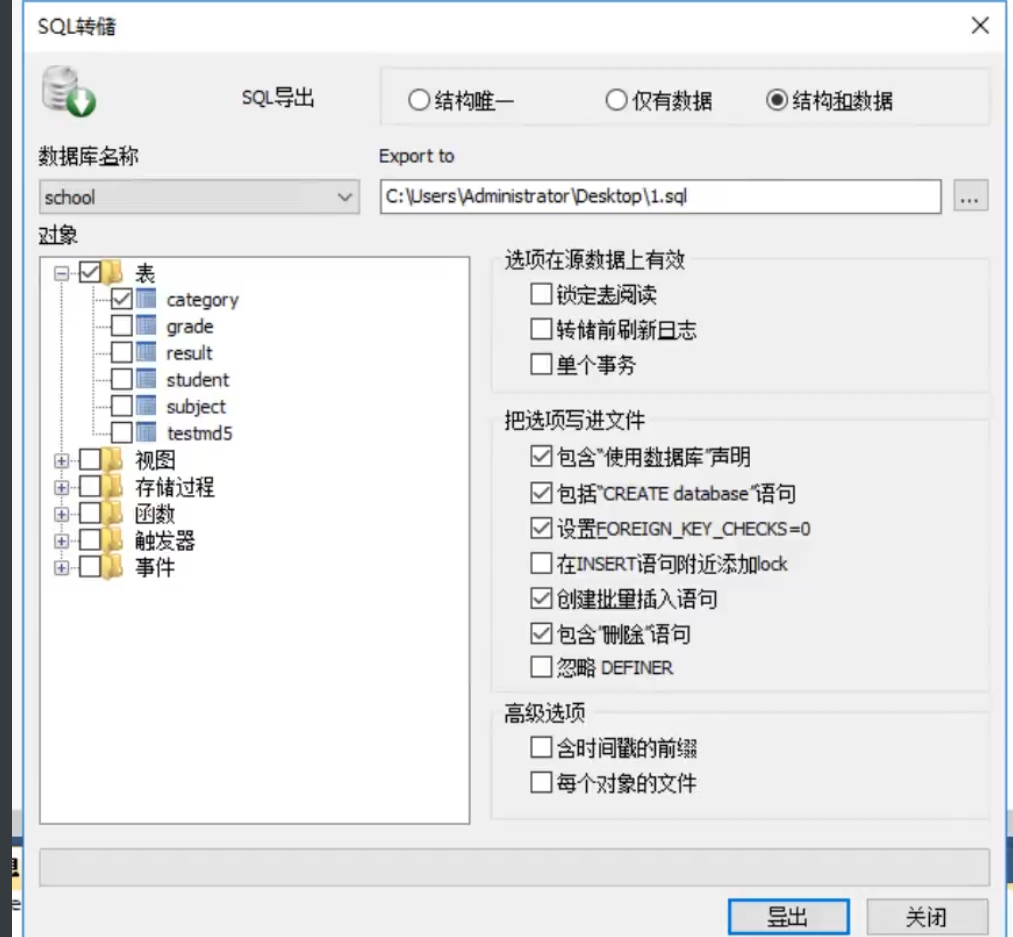
-
命令行备份
9.规范数据库设计
9.1为什么需要设计
当数据库比较复杂的时候,我们就需要设计了
糟糕的数据库设计:
-
数据多余,浪费空间
-
数据库插入和删除都会麻烦,异常 [屏蔽使用物理外键 ]
-
程序的性能差
良好的数据库设计
-
节省内存空间
-
保证数据库的完整性
-
方便我们开发系统
软件开发中,关于数据库的设计
-
分析需求:分析业务和需求处理的数据库的需求
-
概要设计:设计关系图 E-R图
-
设计数据库的步骤;(个人博客)
-
收集客户需求
-
用户表
-
分类表
-
文章表
-
评论表
-
………………
-
-
标识实体 (把需求落地到每个字段)
-
标识实体 之间的关系
-
user --> blog
-
user --> category
-
user -->user
-
links
-
网站 : cm ELement Ant Design Pro
9.2 三大范式
为什么需要数据规范化?
-
信息重复
-
更新异常
-
插入异常
-
无法正常 显示
-
-
删除异常
-
丢失有效的信息
-
三大范式
第一范式(1NF)
原子性 :保证每一个列不可再分
第二范式(2NF)
前提:在满足第一范式的情况下
每张表只描述一件事情
第三范式(3NF)
前提:在满足第一范式和第二范式的情况下
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
(规范数据库的设计)
规范性 和 性能的问题
-
关联查询的表不得超过三张表
-
考虑商业化的需求和目标,(成本,用户体验 !)数据库的性能更加重要
-
在规范性能的问题的时候,需要适当的考虑一些规范性!
-
故意给某些表增加一些冗余的字段 (从多表查询中变为单表查询)
-
故意增加一些计算列(从大数据量降低为小数据量的查询:索引)
10,JDBC(重点)
10.1,数据库驱动
驱动:声卡 显卡 数据库
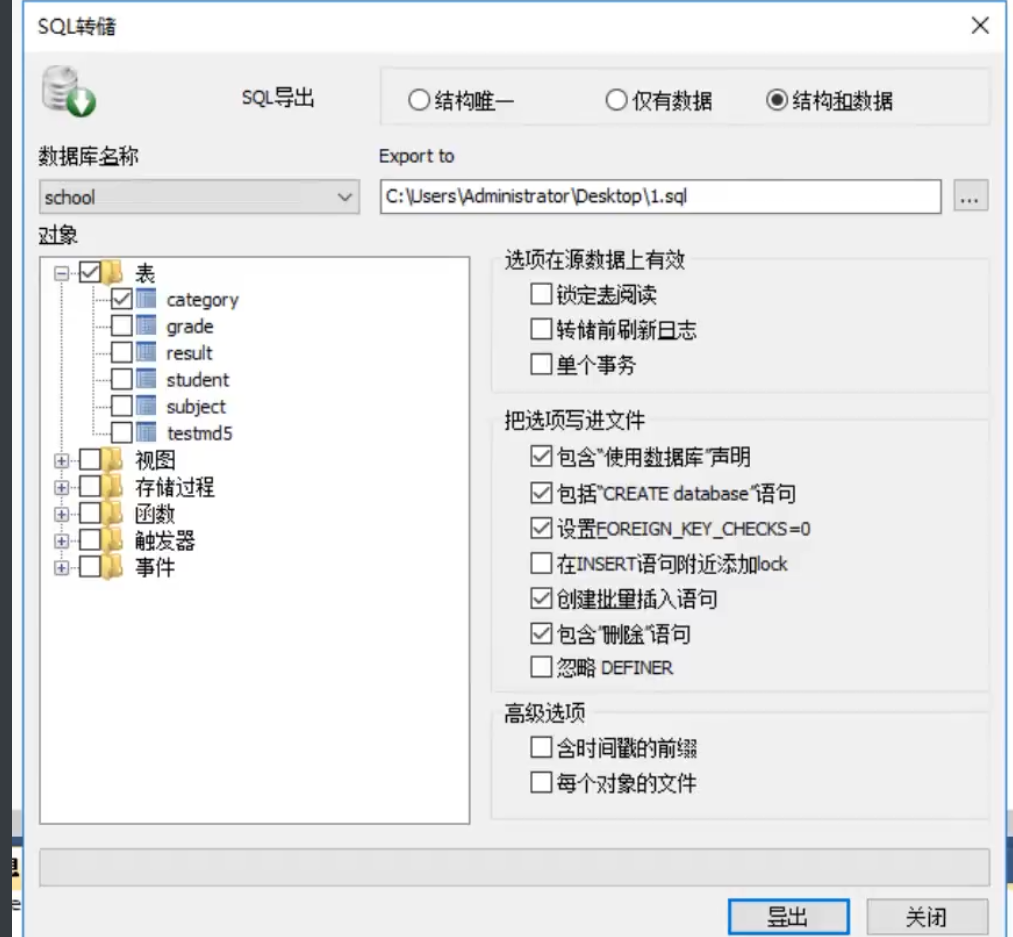
我们的程序会通过数据库 驱动 和 数据库打交道
10.2 JDBC
SUN 公司为了 简化开发人员的(对数据库的统一)操作,提供了一个(Java操作数据库的)规范,俗称 JDBC 这些规范的实现由具体的厂商去做
开发人员 主要掌握对接的问题即可
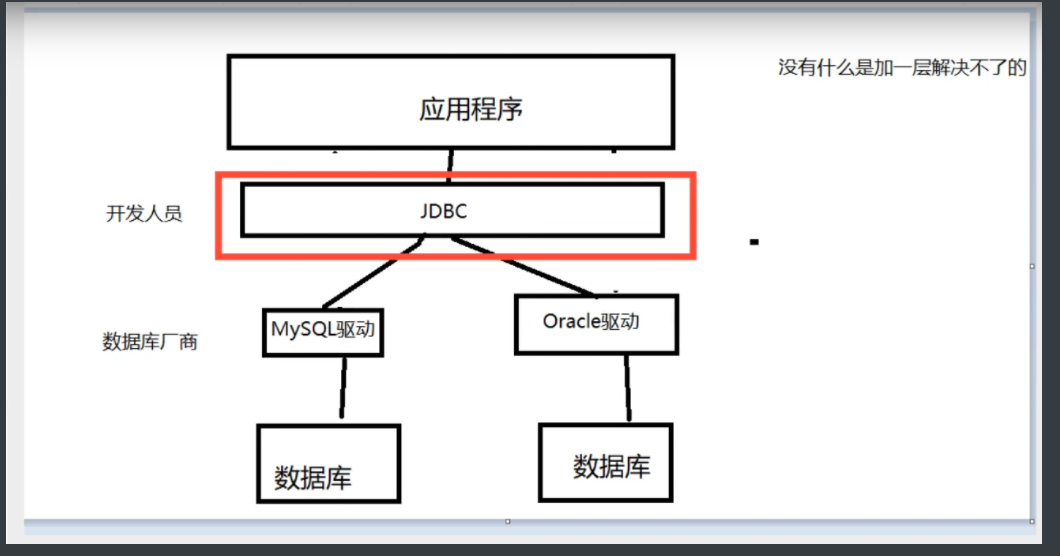
还需要 导入一个 数据库驱动包 mysql -connector-java-5.1.47.jar
10.3 第一个JDBC 程序
测试数据可
创建测试数据库
CREATE DATABASE jdbcStudy CHARACTER SET utf8 COLLATE utf8_general_ci;
USE jdbcStudy;
CREATE TABLE `users`(
id INT PRIMARY KEY,
NAME VARCHAR(40),
PASSWORD VARCHAR(40),
email VARCHAR(60),
birthday DATE
);
INSERT INTO `users`(id,NAME,PASSWORD,email,birthday)
VALUES(1,zhansan,123456,zs@sina.com,1980-12-04),
(2,lisi,123456,lisi@sina.com,1981-12-04),
(3,wangwu,123456,wangwu@sina.com,1979-12-04)
1.创建一个普通的项目
2.导入数据库驱动
ctrl+c ctrl+v
3.编写测试代码
import java.sql.*;
//我的第一个JDBC 程序
public class JdbcFirstDemo{
public static void main(String[]args) throws ClassNotFoundException,SQLException {
// 1.加载驱动
Class.forName("com.mysql.jdbc.Driver"); // 固定写法, 加载驱动
//2.用户信息和url
// useUnicode=true&charaterEncoding=utf8&useSSL=true
String url ="Jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&charaterEncoding=utf8&useSSL=true";
String username ="root";
String password = "123456"
//3.连接成功,数据库对象 Connection 代表数据库
Connection connection =DriverManager.getConnection(url, username , passworld);
//4.执行SQL 的对象 Statement 执行sql的对象
Statemet statement = connection.createStatement();
//5.执行SQL的对象 去 执行SQL, 可能存在结果, 查看返回结果
String sql ="SELECT * FROM users" //编写sql
ResultSet resultset = statement.executeQuery(sql); //返回的结果集,结果集中封装了我们全部的查询出来的结果
While (resultSet.next()){
System.out.println("id=" + resultSet.getObject("id"))
System.out.println("name=" + resultSet.getObject("NAME"))
System.out.println("pwd=" + resultSet.getObject("PASSWORD"))
System.out.println("email=" + resultSet.getObject("email"))
System.out.println("birth=" + resultSet.getObject("birthday"))
}
//6.释放链接
resultSet.close();
statement.close();
connection.close();
}
}
步骤总结
1.加载驱动
2.链接数据库DriverManger
3.获得执行sql的对象 Statement
4.获取返回的结果集
5.释放链接
Driver Manager
//DriverManager.registerDriver(new com.mysql.jdbc.Driver);
Class.forName("com.mysql.jdbc.Driver"); // 固定写法, 加载驱动
Connection connection=DriverManager.getConnection(url,username,password);
//connection 代表数据库
//数据库设置自动提交
//事务提交
//事务回滚
connection.rollback();
connection.commit();
connection.setAutocommit();
URL
String url ="Jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&charaterEncoding=utf8&useSSL=true";
//mysql --3306
//协议 ; //主机地址;端口号/数据库名?参数1&参数2&
//orlce --1521
//jdbc:orlce:thin:@localhost:1521:sid
Staement 执行SQL 的对象 PrepareStatement 执行SQL的对象
String sql ="SELECT * FROM users" //编写sql
statement.executeQuery();//查询操作返回 Resultset
statement.execute();//执行任何SQL
statement.executeUpdate();// 更新. 插入 . 删除 .都是用这个,返回一个受影响的行数
Result Set 查询的结果集; 封装了所用的查询结果
获得指定的数据类型
resultSet.getObject(); //在不知道列类型的情况下使用
// 如果知道列的类型就使用指定的类型
resultSet.getString();
resultSet.getint();
resultSet.getFloat();
resultSet.getDate();
遍历 ,指针
resultSet.beforeirst(); //移动到最前面
resultSet.afterLast(); //移动到最后面
resultSet.next(); //移动到下一个数据
resultSet.previous(); //移动到前一行
resultSet.absolute(row); //移动到指定行
释放资源
resultSet.close();
statement.close();
connection.close(); // 耗资源,用完关闭!
10.4 statement对象
jdbc中的statement对象用于向数据库发送SQL语句,想完成对数据库的增删改查,只需要通过这个对象向数据库发送增删该查语句即可.
Statement对象的executeUpdatefan方式,用于向数据库发送增.删.改的sql语句,executeUpdatefan执行完后,将会返回一个整数(即增删改语句导致了数据库几行数据发生了变化)
Statement.executeQuery方法用于向数据库发送查询语句,executeQuery方法返回代表查询结果的ResulSet对象
CRUD操作-create
使用executeUpdate(String sql)方法完成数据添加操作,:
Statemt st =coon.createStatement();
String sql ="insert into user (...) values(....)";
int num =st.executeUpdate(sql);
if(num>0){
System.out.println("插入成功!!");
}
CRUD操作 - delent
使用executeUpdate(String sql)方法完成数据添加操作,:
Statemt st =coon.createStatement();
String sql ="delete from user where id=1";
int num =st.executeUpdate(sql);
if(num>0){
System.out.println("删除成功!!");
}
CRUD 操作-update
使用executeUpdate(String sql)方法完成数据添加操作,:
Statemt st =coon.createStatement();
String sql ="update user set name='' where name=''";
int num =st.executeUpdate(sql);
if(num>0){
System.out.println("修改成功!!");
}
CRUD操作-read
使用executeUpdate(String sql)方法完成数据添加操作,:
Statemt st =coon.createStatement();
String sql ="select * from user where id=1";
ResultSet rs =st.executeUpdate(sql);
while(rs.next){
//根据获取的数据类型,分别调用rs的相应方法映射到java对象中
}


