


爬虫大作业
作业来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
# coding=utf-8 __author__ = 'zzj' from urllib import request import json import time from datetime import datetime from datetime import timedelta # 获取数据,根据url获取 def get_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' } req = request.Request(url, headers=headers) response = request.urlopen(req) if response.getcode() == 200: return response.read() return None # 处理数据 def parse_data(html): data = json.loads(html)['cmts'] # 将str转换为json comments = [] for item in data: comment = { 'id': item['id'], 'nickName': item['nickName'], 'cityName': item['cityName'] if 'cityName' in item else '', # 处理cityName不存在的情况 'content': item['content'].replace('\n', ' ', 10), # 处理评论内容换行的情况 'score': item['score'], 'startTime': item['startTime'] } comments.append(comment) return comments # 存储数据,存储到文本文件 def save_to_txt(): start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 获取当前时间,从当前时间向前获取 end_time = '2018-08-10 00:00:00' while start_time > end_time: url = 'http://m.maoyan.com/mmdb/comments/movie/1207959.json?_v_=yes&offset=0&startTime=' + start_time.replace(' ', '%20') html = None ''' 问题:当请求过于频繁时,服务器会拒绝连接,实际上是服务器的反爬虫策略 解决:1.在每个请求间增加延时0.1秒,尽量减少请求被拒绝 2.如果被拒绝,则0.5秒后重试 ''' try: html = get_data(url) except Exception as e: time.sleep(1.0) html = get_data(url) else: time.sleep(0.5) comments = parse_data(html) print(comments) start_time = comments[14]['startTime'] # 获得末尾评论的时间 start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1) # 转换为datetime类型,减1秒,避免获取到重复数据 start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S') # 转换为str for item in comments: with open('D:\Zj.csv', 'a', encoding='utf-8') as f: f.write(str(item['id'])+','+item['nickName'] + ',' + item['cityName'] + ',' + item['content'] + ',' + str(item['score'])+ ',' + item['startTime'] + '\n') if __name__ == '__main__': # html = get_data('http://m.maoyan.com/mmdb/comments/movie/1207959.json?_v_=yes&offset=0&startTime=2018-07-28%2022%3A25%3A03') # comments = parse_data(html) # print(comments)


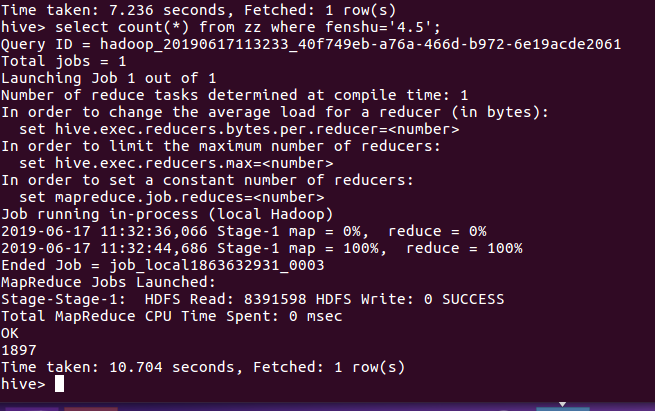
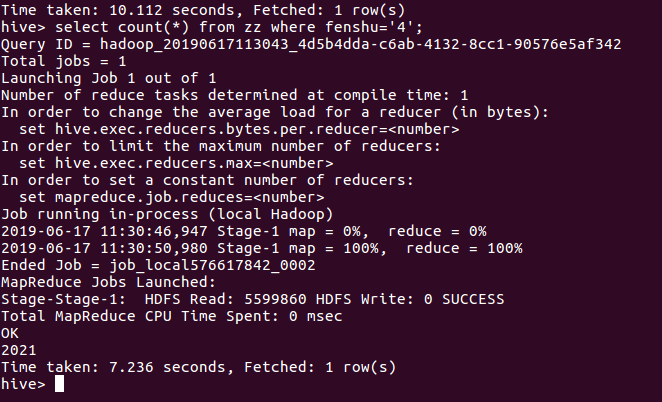
扇形统计图如下:
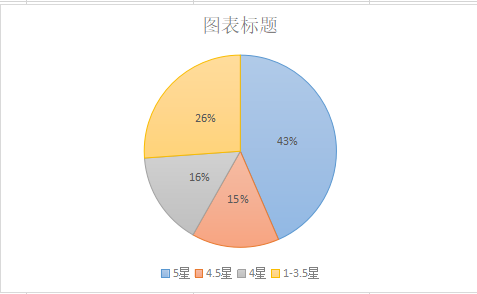
数据总共12900条,其中五星评分的有5612条,占43.5%;其中4.5星有1897条,占14.7%;其中4星有2021,占15.67%。
以4.0以上看做满意,可得出对该影片满意的有73.87%。
生成词云如下:
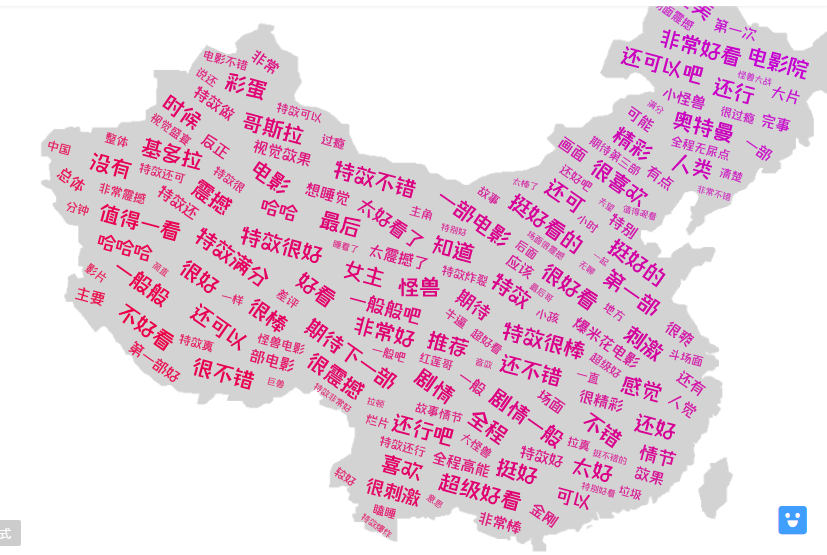
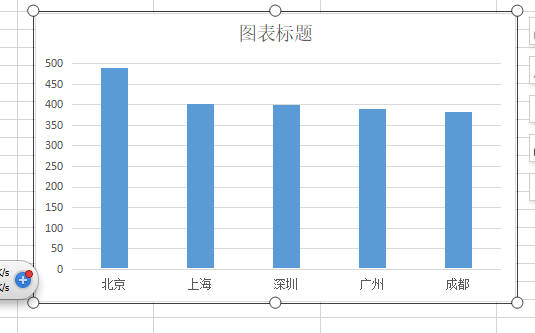
影评最多的人所在的五个城市为北京、上海、深圳、广州、成都,说明这部电影在这些城市较为受欢迎。

