
机器学习--无监督学习--聚类
适用场景
没有给定一些分类的标签,让你对现有数据基于算法,自己分堆儿(聚类)。
常用算法
K-Means:核心思想就是,自己先假定,一共要分几个类,然后每个类里,你要定一个c位。然后对每个点,都算一下到每个类c位的距离,哪个最小,就划入哪个类。每个点都划分好以后,对每个类的c位进行一次更新。然后继续再对每个点都算一下,距离每个分类c位的距离,再重新划分一次类。划分完,再次更新每个类的c位。如此循环,直到每个类的c位不再变化或者变化幅度达到了某个约定的阈值,或者达到了最大循环次数。结束。
K-means算法原理
1、确定聚类个数,聚类中心。常用方法有,观察法、枚举法、交叉验证法等。交叉验证法在有监督学习的KNN中已经详细描述过,这里不再详细展开;
2、确定距离计算公式,常用欧氏距离。欧氏距离在有监督学习的KNN中已经描述过,这里不再详细展开;
3、计算每个点,和每个类的c位的距离,离谁近,就划入哪个分类。如下,为红点和绿色、黑色、深红色的3个c位的距离;

4、加入新的点,需要更新c位;

5、由于c位变化,于是,重新循环一次3,4步;
6、直到每个类的c位不再变化或者变化幅度达到了某个约定的阈值,或者达到了最大循环次数。结束。
K-Means优缺点
优点:理解简单,实现简单,聚类结果好解释;
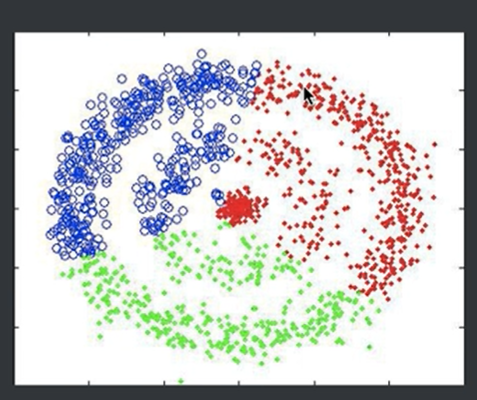
缺点:k值是否合理,不同k值对结果影响还是很大的;c位选择的不同对结果影响也较大;样本点多的时候,计算量大;对异常值敏感,离散值需要特殊处理;对于球状的类簇识别效果好,非球状效果差。如下图所示,看下图其实是3个圆圈,就是3个环,本意是想分成,中心环,及外面两个圈。但是K-Means一定还是按照球状去分成了3个扇形。这就是它算法的局限性。
本文来自博客园,作者:1234roro 当你迷惘的时候,开始学习吧!当你目标清晰的时候,开始学习吧!转载请注明原文链接:https://www.cnblogs.com/1234roro/p/18295750

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步