机器学习--有监督学习--线性回归(预测数据)
整体概念
有监督学习,就是会有一些 已有的标签等已经做好分类的信息,你基于一些算法,把新拿到的数据,贴上对的标签;无监督学习,就是没有标签,你就自己算吧,自己把这一堆数据做不同的聚类。
线性回归
- 整理原因:为了更好地理解学习算法为什么有用、可靠,还是决定认真看看推导公式和过程。以下是有监督学习线性回归的推导过程。
- 算法目标:根据一组x和y的对应关系,找到他们的线性关系,得到拟合线性方程:y=ax+b,从而对于任意的自变量x,都可以预测到对应的因变量y的值。并且,要保证这个a,b足够可靠,也就是使得我们的预测值和实际值误差足够小。
- 推导思路:使用最小二乘法,求得预测值和实际值的误差最小值时,a,b的值,从而获得线性方程。
- 推导过程:
1、对于拟合的线性方程,我们不妨假设为如下形式:

2、使用最小二乘法,找到误差最小值,也就是如下公式的最小值

1)先通过对SSE,对模型参数β0和β1求偏导(回忆点:求导和求偏导的区别,求导是对只有一个变量的微分,偏导是函数存在多个变量时,假设其余变量不变,只对某一个变量求导的过程。意义都是求这个变量的变化对函数的影响)
【对β0求偏导】
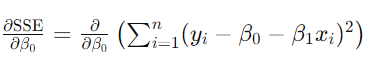
根据链式法则,首先对整体平方项求导:
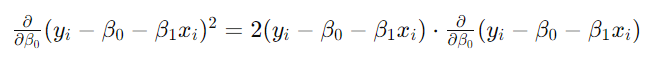
然后再对内部项求导,如下
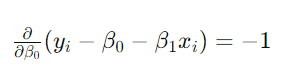
所以完整求导后,结果如下:
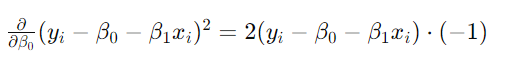
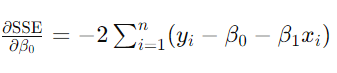
【对β1求偏导】
思路如上,结果如下:
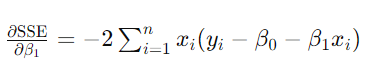
2)设偏导数为零,对这个正则方程组求解,求得β0 和 β1 的最优值(回忆点:偏导数为零的点,意味着在这些点上,函数的变化率为零,即函数在这些点处达到极值(最小值或最大值))
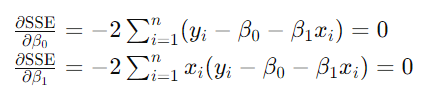
【第一个方程】
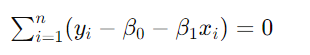
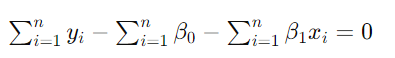
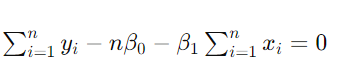
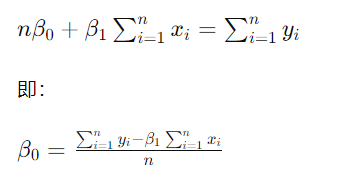
【第二个方程】
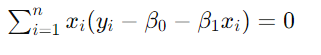
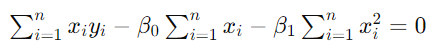
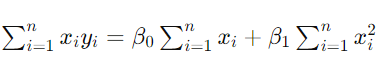
【联立两个方程】
将β0代入方程2,得到
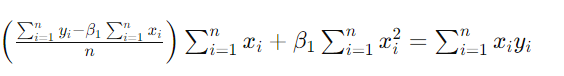
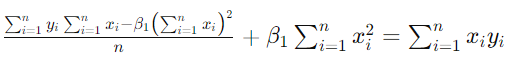
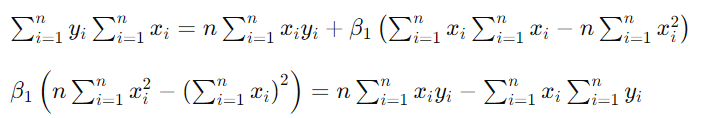
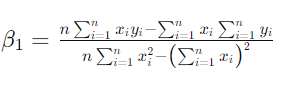
【简化β1的值】
通过样本均值进行简化:
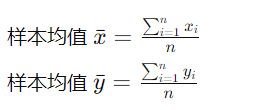
所以
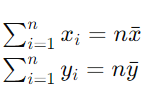
代入到β1:

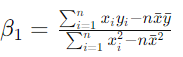
【分子部分的简化】
针对nxˉyˉ,继续简化,这里拎出来写:
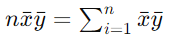
所以,分子变换为:

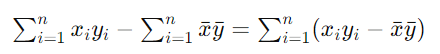
进一步对每一项进行化简:
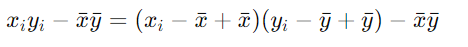 =
=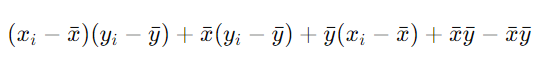
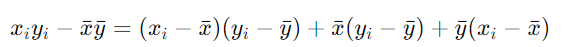
所以运算和为:
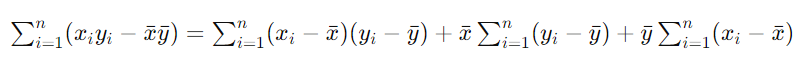
又因为:
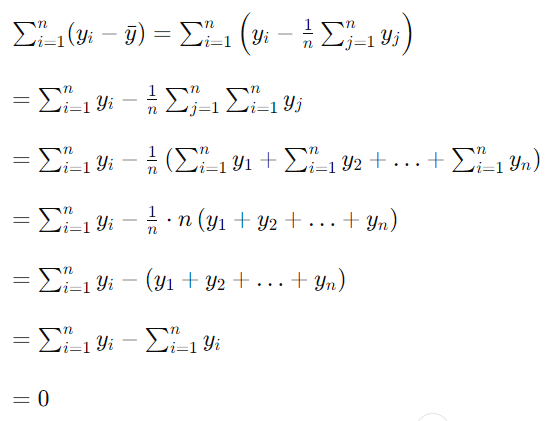
所以最终,分子被简化为:
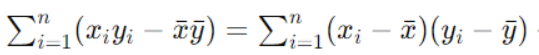
【分母部分的简化】
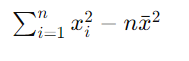
=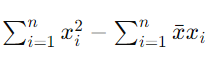
=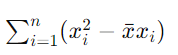
=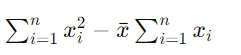
=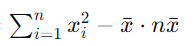
=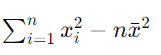
=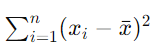
至此,β1被简化为如下式子,β0代入一下,就是第二个式子。
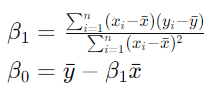
【得到确定的线性方程式】至此,得到了使得SSE最小值时的β0和β1,代入f(x)=β0+β1x,得到拟合线性方程。
- 示例,代入上面β0和β1的公式,直接得到拟合方程,预估不同x下的y值

本文来自博客园,作者:1234roro 当你迷惘的时候,开始学习吧!当你目标清晰的时候,开始学习吧!转载请注明原文链接:https://www.cnblogs.com/1234roro/p/18237703

 浙公网安备 33010602011771号
浙公网安备 33010602011771号