第一个微信小项目
一、微信好友分析
(1)、统计自己多少个微信好友
代码如下:
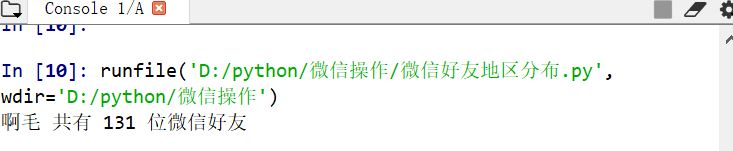
# -*- coding: utf-8 -*- """ Created on Mon Jun 3 10:21:25 2019 @author: user """ #导入模块 from wxpy import * #初始化机器人,选择缓存模式(扫码)登录 bot = Bot(cache_path=True) #获取我的所有微信好友信息 friend_all = bot.friends() len(friend_all)
结果如下:
(2)、微信好友省市分布
代码如下:
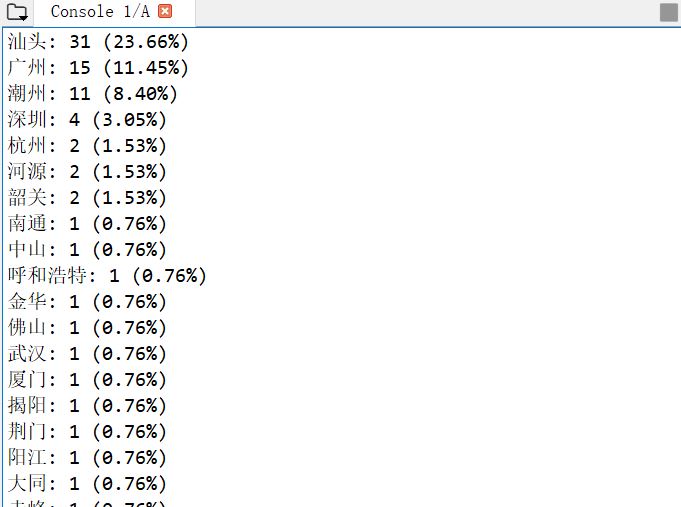
# -*- coding: utf-8 -*- """ Created on Mon Jun 3 10:21:25 2019 @author: user """ #导入模块 from wxpy import * #初始化机器人,选择缓存模式(扫码)登录 bot = Bot(cache_path=True) #获取我的所有微信好友信息 friend_all = bot.friends() Friends = bot.friends() data = Friends.stats_text(total=True, sex=True,top_provinces=30, top_cities=500) print(data)
结果如下:
(3)将微信好友数据存为excel文件
代码如下:
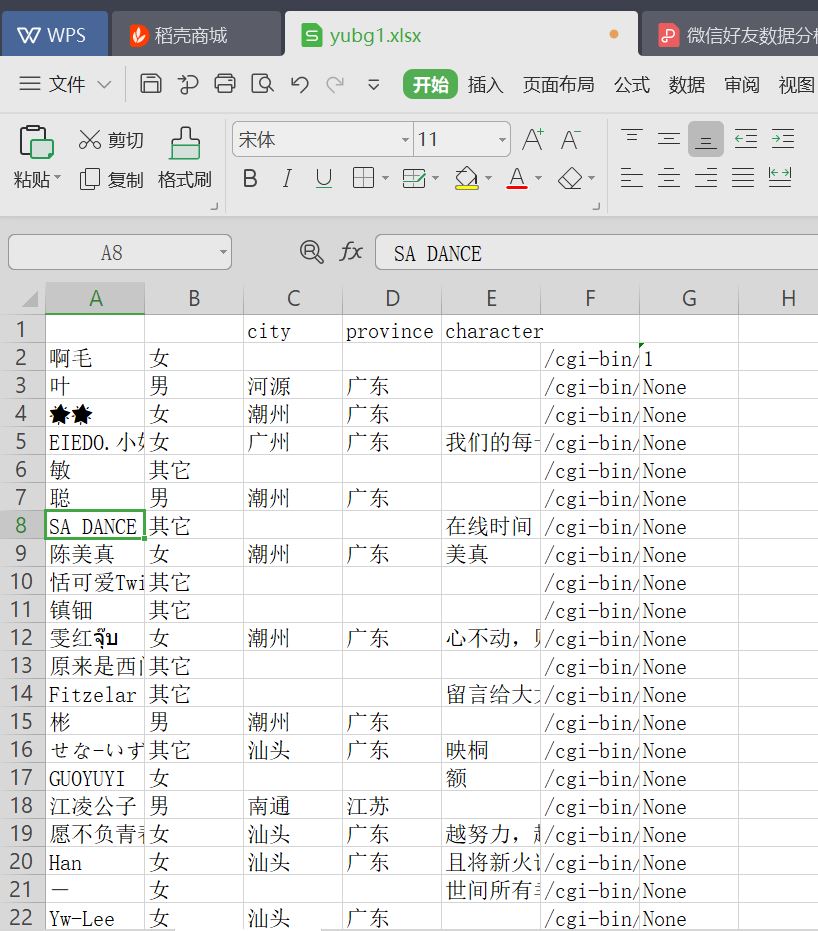
# -*- coding: utf-8 -*- """ Created on Mon Jun 3 10:48:22 2019 @author: user """ lis=[] for a_friend in friend_all: NickName = a_friend.raw.get('NickName',None) #Sex = a_friend.raw.get('Sex',None) Sex ={1:"男",2:"女",0:"其它"}.get(a_friend.raw.get('Sex',None),None) City = a_friend.raw.get('City',None) Province = a_friend.raw.get('Province',None) Signature = a_friend.raw.get('Signature',None) HeadImgUrl = a_friend.raw.get('HeadImgUrl',None) HeadImgFlag = a_friend.raw.get('HeadImgFlag',None) list_0=[NickName,Sex,City,Province,Signature,HeadImgUrl,HeadImgFlag] lis.append(list_0) def lis2e07(filename,lis): ''' 将列表写入 07 版 excel 中,其中列表中的元素是列表. filename:保存的文件名(含路径) lis:元素为列表的列表,如下: lis = [["名称", "价格", "出版社", "语言"], ["暗时间", "32.4", "人民邮电出版社", "中文"], ["拆掉思维里的墙", "26.7", "机械工业出版社", "中文"]] ''' import openpyxl wb = openpyxl.Workbook() sheet = wb.active sheet.title = 'list2excel07' file_name = filename +'.xlsx' for i in range(0, len(lis)): for j in range(0, len(lis[i])): sheet.cell(row=i+1, column=j+1, value=str(lis[i][j])) wb.save(file_name) print("写入数据成功!") lis2e07('yubg1',lis)
结果如下:
(4)、统计好友城市分布并存为html
代码如下:
# -*- coding: utf-8 -*- """ Created on Mon Jun 3 11:33:11 2019 @author: user """ from pandas import read_excel df = read_excel('yubg1.xlsx',sheet_name='list2excel07') import pandas as pd #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan city_list = df['city'].fillna('NAN').tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN” count_city = pd.value_counts(city_list)#对 list 进行全频率统计 from pyecharts import WordCloud name = count_city.index.tolist() value = count_city.tolist() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(r'D:\python\wc1.html')
结果如下:

(5)、统计微信好友省份分布并存为html
代码如下:
# -*- coding: utf-8 -*- """ Created on Mon Jun 3 10:45:48 2019 @author: user """ province_list = df['province'].fillna('NAN').tolist()#将 dataframe 的列转化为 list,其中的 nan 用 count_province = pd.value_counts(province_list)#对 list 进行全频率统计 from pyecharts import Map value =count_province.tolist() attr =count_province.index.tolist() map=Map("各省微信好友分布", width=1200, height=600) map.add("", attr, value, maptype='china', is_visualmap=True, visual_text_color='#000', is_label_show = True) #显示地图上的省份 map.show_config() map.render(r'D:\python\map1.html')
结果如下:
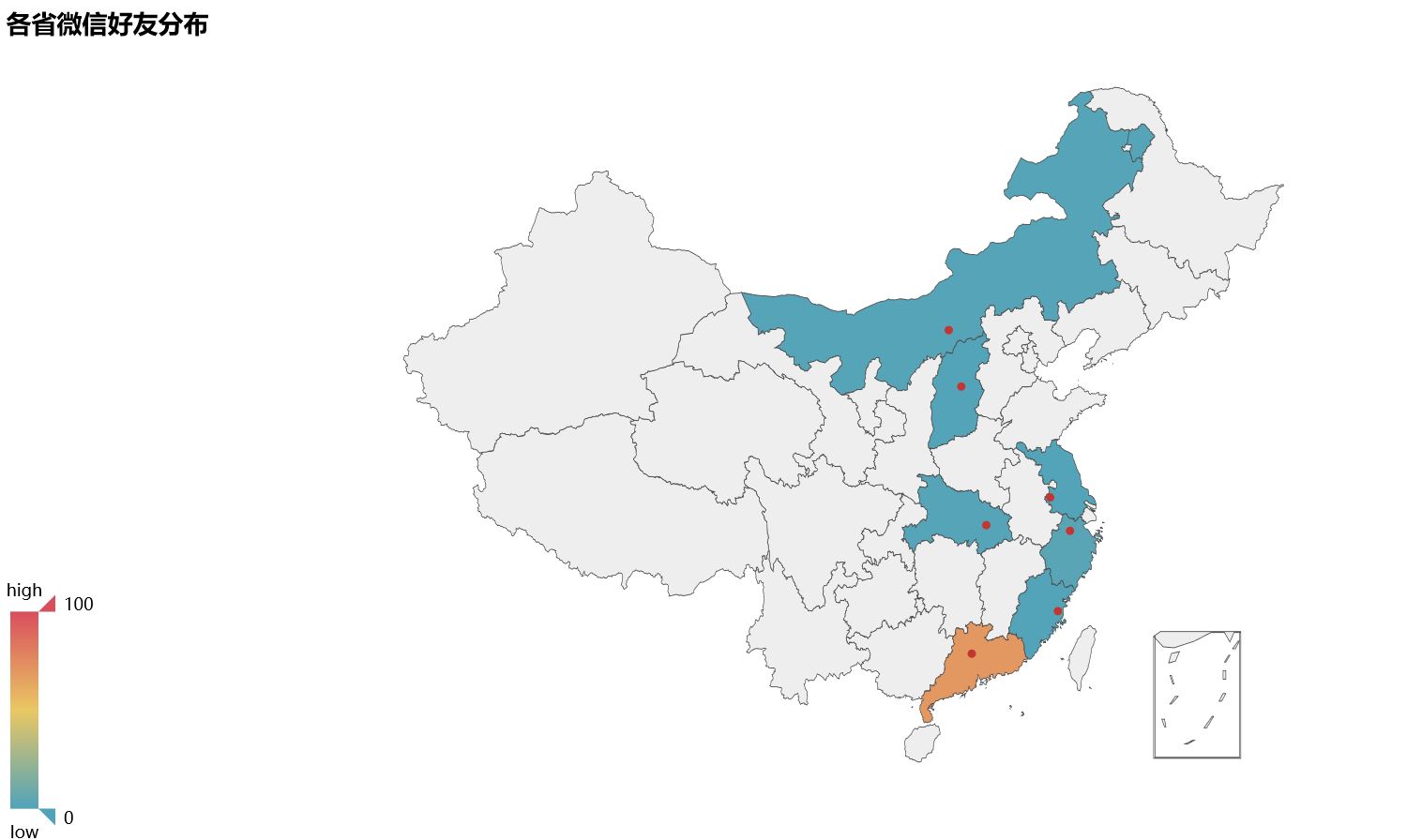
(6)、统计微信好友个性签名特点并存为html
代码如下:
# -*- coding: utf-8 -*- """ Created on Wed Jun 5 15:23:22 2019 @author: user """ from pandas import read_excel df = read_excel('yubg1.xlsx',sheet_name='list2excel07') import pandas as pd #count = df.city.value_counts() #对 dataframe 进行全频率统计,排除了 nan character_list = df['character'].fillna('NAN').tolist()#将 dataframe 的列转化为 list,其中的 nan 用“NAN” count_character = pd.value_counts(character_list)#对 list 进行全频率统计 from pyecharts import WordCloud name = count_character.index.tolist() value = count_character.tolist() wordcloud = WordCloud(width=1300, height=620) wordcloud.add("", name, value, word_size_range=[20, 100]) wordcloud.show_config() wordcloud.render(r'D:\python\wc2.html')
结果如下:

二、微信聊天机器人
代码如下:
# -*- coding: utf-8 -*- """ Created on Wed Jun 5 17:43:37 2019 @author: user """ from itchat.content import * import requests import json import itchat #最好添加这个 不然会报错 import sys defaultencoding = 'utf-8' if sys.getdefaultencoding() != defaultencoding: reload(sys) sys.setdefaultencoding(defaultencoding) itchat.auto_login(hotReload=True) # 调用图灵机器人的api,采用爬虫的原理,根据聊天消息返回回复内容 def tuling(info): #appkey 去图灵官网去申请 http://www.tuling123.com/ appkey = "d6fbdae9713243ba9b0ceb72f8fc9ad7" url = "http://www.tuling123.com/openapi/api?key=%s&info=%s" % (appkey, info) req = requests.get(url) content = req.text data = json.loads(content) answer = data['text'] return answer # 对于群聊信息,定义获取想要针对某个群进行机器人回复的群ID函数 def group_id(): groups = itchat.get_chatrooms(update=True) for i in range(len(groups)): group_name = groups[i]['NickName'] if '夸夸群' in group_name: return group_name # 注册文本消息,绑定到text_reply处理函数 # text_reply msg_files可以处理好友之间的聊天回复 @itchat.msg_register([TEXT, MAP, CARD, NOTE, SHARING]) def text_reply(msg): itchat.send('%s' % tuling(msg['Text']), msg['FromUserName']) @itchat.msg_register([PICTURE, RECORDING, ATTACHMENT, VIDEO]) def download_files(msg): msg['Text'](msg['FileName']) return '@%s@%s' % ({'Picture': 'img', 'Video': 'vid'}.get(msg['Type'], 'fil'), msg['FileName']) # 现在微信加了好多群,并不想对所有的群都进行设置微信机器人,只针对想要设置的群进行微信机器人,可进行如下设置 @itchat.msg_register(TEXT, isGroupChat=True) def group_text_reply(msg): group_name = group_id() if msg['isAt']: msg_text = msg['Text'] info = msg_text if '啊毛' in msg_text: # if里 写你微信名字 info = str(msg_text).replace('啊毛','') #replace里写你微信名字 msg.user.send(u'%s' % tuling(info),group_name) itchat.run() import sys defaultencoding = 'utf-8' if sys.getdefaultencoding() != defaultencoding: reload(sys) sys.setdefaultencoding(defaultencoding) itchat.auto_login(hotReload=True)
结果如下: