序列化(pickle,shelve,json,configparser)
一,序列化
在我们存储数据或者网络传输数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和传输的数据结构,这个过程叫序列化,不同的序列化,结果也不同,但是目的是一样的,都是为了存储和传输。
在python中存在三种序列化的方案。
1,pickle,可以将我们python中的任意数据类型转化成bytes并写入到文件中,同样也可以把文件中写好的bytes转换回我们python的数据,这个过程称为反序列化。
2,shelve,简单另类的一种序列化的方案,有点类似Redis,可以作为一种小型数据库来使用
3,json,将python中常见的字典,列表转化成字符串,是目前前后端数据交互使用频率最高的一种数据格式。
二,pickle(重点)
pickle就是把我们的python对象写入到文件中的一种解决方案。首先要引用pickle模块,主要是使用pickle.dumps()把对象转换成bytes;pickle.loads()把bytes转换成对象;

pickle.dump()把对象转换成bytes,然后写入文件中;pickle.load()从文件中读出,然后把bytes转换成对象。

多个对象写入和读


三,shelve
shelve提供python的持久化操作,就是把数据写到硬盘上,在操作shelve的时候非常像操作一个字典。

但是有个坑,在对内层的数据进行修改时,或者删除字典中的元素时,要用到writeback参数,不然操作后结果不会改变。

得到后的字典,可以完成字典所有操作,比如遍历,setdefault()


四,json(重点)
json就是前后端交互的枢纽,导入json模块,所使用的方法和pickle一样的。json.dumps()把字典转化成json字符串,json.loads()是把json字符串转化成字典。


json.dump()把字典转化成json字符串,然后写入文件中;json.load()把json字符串从文件中读出来,然后转换成字典。


对于多个字典的写入或者读,要采用以下办法。

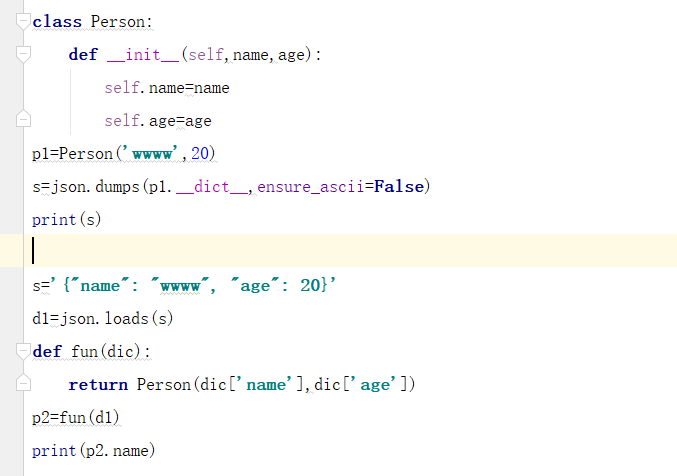
用json来处理对象
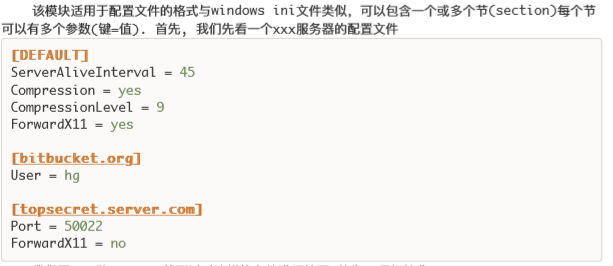
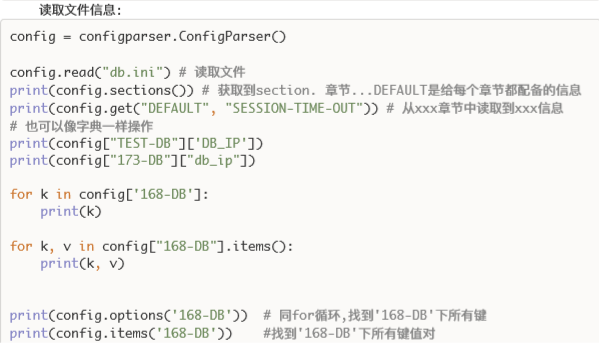
五,configparser模块