
RabbitMQ消息队列
一、简介
RabbitMQ是一个在AMQP基础上完整的、可复用的企业消息系统,遵循Mozilla Public License开源协议。MQ全称Message Queue(消息队列),它是一种应用程序对应用程序的通信方式。应用程序通过读写入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接他们。消息传递指的是程序之间通过在消息中发送数据通信,而不是直接调用彼此来通信,直接调用通常用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
应用场景:
1,系统集成,分布式系统的设计。各种子系统通过消息来对接,这种解决方案也逐步发展成一种架构风格,即‘通过消息传递的架构’
2,当系统中的同步处理方式严重影响了吞吐量,比如日志记录。假如需要记录系统中所有的用户行为日志,如果通过同步的方式记录日志势必会影响系统的响应速度,当我们将日志消息发送到消息队列,记录日志的子系统就会通过异步的方式拿到日志消息。
3,系统的高可用性,比如电商的秒杀场景,当某一时刻应用服务器或数据库服务器收到大量请求,将会出现系统宕机。如果能够将请求转发到消息队列,再由服务器去拿到这些消息,将会使得请求平稳,提高系统的可用性。
二、下载及安装
1,安装erlang,在官网下载,然后一直点下一步进行安装
2,安装RabbitMQ,也是官网下载,直接安装
3,配置
用cmd进入到RabbitMQ Server\rabbitmg_server-3.6.5\sbin目录下,输入:rabbitmg-plugins enable rabbitmg-management,这样就配置好了。此时我们就可以以管理员身份打开cmd,输入:net start rabbitmq 启动服务;输入:net stop rabbitmq 关闭服务
三、RabbitMQ简单模式
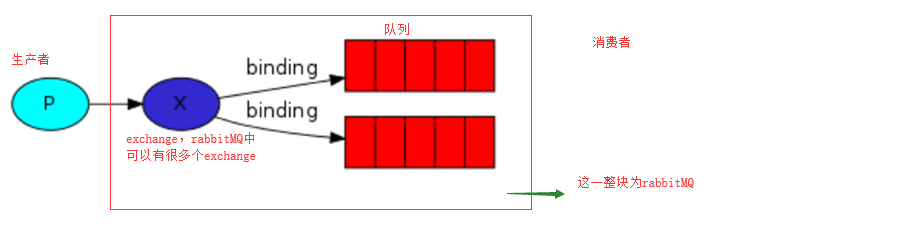
在使用过程中,始终贯穿着三个部分,一是生产者,二是消费者,三是RabbitMQ Server(是运行在某个服务器上的),生产者是往消息队列中放数据的,而消费者是从消息队列中取数据的。我们是在python中实现的,所以得安装一个pika的模块,帮我们连接队列。
1,基本代码
生产者,producer.py
import pika #连接rabbitMQ connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #创建队列,队列名为‘hello’,这个名字随意 channel.queue_declare(queue='hello') #往队列里添加值,routing_key是表示我们要往‘hello’队列放数据,body表示我们这次放入的数据为‘hello world’ channel.basic_publish(exchange='', routing_key='hello', body='Hello World!')
#这是关闭连接 connection.close()
消费者,consumer.py
import pika #连接rabbitMQ connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #创建队列,这里也是创建队列的意思,消费者和生产者说不定哪一个先启动,所以谁先启动就谁创建,当另一个进来后。如果队列存在了,就不创建了 channel.queue_declare(queue='hello') #回调函数 def callback(ch, method, properties, body): print(body) #确定监听队列事件,当队列里有值,就会取值,然后返回给回调函数 channel.basic_consume( callback, queue='hello', no_ack=True) #这才是真正的开始监听 channel.start_consuming()
2,no_ack参数
2.1 no_ack=True时,为无应答模式,这里的应答指的是消费者不给队列回应。这种情况下,消费者从队列中拿走一条数据,队列会立即把这条数据删掉,当消费者在处理这条数据时出现错误导致消费者断开而没有完成任务时,消费者是不可能再次从队列里拿到刚才的那条数据,也就意味着这条数据没有处理但是消失了,从而这条数据永远也得不到处理了。
2.2 no-ack=false,为应答模式,消费者每取一条数据,当处理成功后会给队列一个应答,此时,队列收到应答才会把数据删除;当消费者处理数据失败而没有给队列应答,队列是不会删除这条数据,等着下一个消费者再次来取这个数据,当收到应答后才会删除这条数据
2.3 代码,这过程只是消费者与队列的关系变化,所以只用改变消费者的代码既可
消费者,consumer_ack.py
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='10.211.55.4')) channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print(body)
#在这加上一句应答 ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello', no_ack=False) #把no-ack设置为False channel.start_consuming()
消费者在处理过程中由于某种原因(比如bug等)断开连接后,消息是不会丢失的,这个数据会给下一个来拿去数据的消费者
3,durable参数,也就是数据持久化存储
生产者把数据放在队列中,当消费者还没拿取数据,队列所在的服务器崩了,此时,队列里面的数据就会消失了。我们要想吹这种情况,那只有让队列里的数据持久化存储了,这需要我们在定义队列是就应该声明。
生产者,producer_durable.py
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4')) channel = connection.channel()
#给durable赋为True既可,也就是让其持久化存储 channel.queue_declare(queue='hello', durable=True) channel.basic_publish(exchange='', routing_key='hello', body='Hello World!',
#这里要把模式设置为2 properties=pika.BasicProperties( delivery_mode=2, )) connection.close()
消费者,consumer_durable.py
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4')) channel = connection.channel()
#durable设置为True channel.queue_declare(queue='hello', durable=True) def callback(ch, method, properties, body): print(body) ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello', no_ack=False) channel.start_consuming()
rabbitMQ服务器宕机,数据不丢失
4,消息获取顺序
队列的数据默认是按照先后顺序取值,也就是有三个消费者,假如第一波取值顺序为a-b-c,那以后的顺序都是a-b-c,不管a处理数据的快慢,比如说a还在处理数据,然而b已经处理完了,但b还是不能拿值,必须a先拿值,然后b才能拿值。这种形式效率太低。
channel.basic_qos(prefetch_count=1)设置这个参数后,就不是按顺序取值,而是谁先来谁取值。这只是消费者有关的设置。
消费者,consumer_prefetch.py
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4')) channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body): print(body) ch.basic_ack(delivery_tag = method.delivery_tag) #加上这句就行 channel.basic_qos(prefetch_count=1) channel.basic_consume(callback, queue='hello', no_ack=False) channel.start_consuming()
四、RabbitMQ的exchange模式
1,发布订阅模式
简单模式下,一条数据只会给一个消费者;发布订阅模式下,一条消息给所有订阅的消费者。
生产者把消息放在一个指定的exchange里面,然后每个消费者创建一个队列跟这个exchange绑定,从而消费者就可以拿到订阅的数据了。
发布者,
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.137.208')) channel = connection.channel() #模式要更改 channel.exchange_declare(exchange='logs', exchange_type='fanout') message = "Hello World!"
#这里发布者发送消息到exchange channel.basic_publish(exchange='logs', routing_key='', body=message) connection.close()
订阅者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.137.208')) channel = connection.channel() #模式也要改 channel.exchange_declare(exchange='logs', exchange_type='fanout') # 随机创建队列 result = channel.queue_declare(exclusive=True)
#拿到队列名字 queue_name = result.method.queue # 把队列绑定到exchange channel.queue_bind(exchange='logs', queue=queue_name) def callback(ch, method, properties, body): print( body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
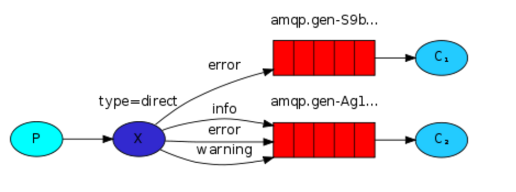
2,关键字模式
在发布者发布消息时,会含有关键字;而订阅者这次不单单只是把队列跟exchange绑定,还要绑定关键字,当发布者的关键字和绑定的关键字相同时,订阅者才能拿到消息,然而一个队列可以跟一个exchange绑定多个关键字。
发布者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明一个交换机 channel.exchange_declare(exchange='direct_logs',exchange_type="direct") message ="warning: Hello World!" channel.basic_publish(exchange='direct_logs', routing_key='warning', #这是发布者发送消息的带的关键字 body=message) connection.close()
订阅者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key="error")#这是队列跟exchange绑定的关键字def callback(ch, method, properties, body): print(body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3,模糊匹配
这是基于关键字的,但这次不是要相同了,而是用模糊匹配,‘#’代表匹配0或多个字符,‘*’表示匹配一个任意字符
发布者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 声明一个交换机 channel.exchange_declare(exchange='topic_logs',exchange_type="topic") message ="Hello World!" channel.basic_publish(exchange='topic_logs', routing_key='banana.apple.xigua.juzi', #这是发布时带着的关键字 body=message) connection.close()
订阅者
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key="*.apple.#") #这是队列跟exchange绑定的关键字,但这里是模糊匹配,能匹配上,就可以拿到值
def callback(ch, method, properties, body): print(body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()

