
爬虫之requests模块
一、爬虫
我所理解的爬虫就是编写程序,模拟浏览器发送请求,然后服务端把数据响应给我,然后我再对响应的数据做解析,拿到我想要的那一小部分,这就是整个爬虫过程。说起来很简单哈,其实不然,门户网站是很不希望他们的数据被爬虫程序拿到,有可能说有些不怀好意的人拿数据干见不得人的勾当,或者说现在大数据时代,有数据才能说明一切,所以门户网站也很珍惜他们的数据,不想那么轻易被别人拿走,于是乎门户网站的程序员就是开始设定很多规则来判断发送请求的是不是一个爬虫程序了,如果是,就直接不给他数据,这就是反爬机制。俗话说“上有政策,下有对策”,难道就你门户网站的人聪明吗?你错了,天外有天,人外有人,你以为你那点小伎俩就能难倒我(确实有很多反爬策略很恶心),就算是大海捞针,我也要通过你的反爬机制,拿到数据,我在找出它的反爬机制和制定相应的对策的过程就叫反反爬。
爬虫总共分为四部分,发送请求,获取响应,解析数据,保存数据,如下图:

今天要说的就是利用requests模块发送请求的过程,也是这整个过程中最重要的一步,也应该是最困难的一步(纯属一家之言),因为上面所说的反爬和反反爬都在这其中。
二、requests模块的基础知识
1,requests支持的请求方式
requests.get("http://httpbin.org/get") requests.post("http://httpbin.org/post") requests.put("http://httpbin.org/put") requests.delete("http://httpbin.org/delete") requests.head("http://httpbin.org/get") requests.options("http://httpbin.org/get")
我们最常用的就是get和post请求,两者的区别就是get请求没有请求体,而post请求有请求体
2,get请求
import requests
#这是请求的路径,必须有 url='https://dig.chouti.com/'
#这是本次访问携带的参数,发送请求时,它会以?name=hh的形式加在路径后面,不是必须要有 params={'name':'hh'}
#这是请求的请求体,它是以键值对的形式存在的,也不是必须要有 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'} #这是访问携带的cookie数据
cookies='dshdjdsadhsaghgdasjjdasjdhasdashdjkhskad'
res = requests.get(url=url, headers=headers,params=params,cookies=cookies)
3,post请求
post请求和get请求是一样的,只是多了一个请求体数据
#data和json都是请求体数据,data是字典类型的,json发送的是json字符串 data={'name':'hh','pwd':'12345'} json={"name":"hh","pwd":"12345"}
#请求体是以data形式发的,默认的contentType类型是urlencoded,如果请求体数据是以json形式发的,默认的contentType类型为json res1=requests.post(url='http://httpbin.org/post', data={'name':'yuan'}) res2=requests.post(url='http://httpbin.org/post',json={'age':"22",})
对于post请求来说,除了比get请求多一个请求体以外,其他用法一模一样,get请求拥有的参数,post都拥有,比如说params参数,
如果在post请求里面加一个params参数,他会和get请求一样,会以?a=1的形式加在请求路径后面
4,response响应对象
4.1 常见属性
import requests respone=requests.get('https://sh.lianjia.com/ershoufang/') respone.text #响应文本,本身是字节类型,但会以一种猜测的编码格式帮你解码成字符串 respone.content #响应文本,字节类型的文本 respone.status_code #响应的状态码 respone.headers #响应头数据 respone.cookies #响应的cookie respone.cookies.get_dict() #响应的字典形式的cookie respone.cookies.items() #响应的元祖形式的cookie respone.url respone.history #如果请求过程中发生了重定向,这会帮你记录过程 respone.encoding #指定text的是用哪种方式解码
4.2 编码问题
刚才上面讲了,res.text会以一种猜测的编码帮你解码,但有时是不正确的编码,所以导致拿到数据编码会有问题,其实我们可以给text指定用哪种编码解码
import requests
res=requests.get('http://www.baidu.com')
coding=res.apparent_encoding #这才是拿到别人的编码方式
res.encoding=coding #把别人的编码方式赋给text的解码方式
res.text #这样解码后的字符串就不会有问题了
4.3 对于图片、视频等字节类型文件
首先我们直接用res.content就行了,其次是由于文件太大,我们不应该一下就全写进文件里,而是应该一段一段的写进去,于是我们就可以for循环res.iter_content(),然后再一次一次的写入
import requests response=requests.get('http://bangimg1.dahe.cn/forum/201612/10/200447p36yk96im76vatyk.jpg') with open("res.png","wb") as f: # f.write(response.content) # 比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的 for line in response.iter_content(): f.write(line)
4.4针对接收json数据
import requests import json response=requests.get('http://httpbin.org/get')
#我们是可以用反序列化自己手动处理json数据,其实这样麻烦了 res1=json.loads(response.text)
#别人已经给我们封装好了一个方法res.json()这样就直接帮你完成了反序列化的过程 res2=response.json()
4.5关于重定向
在requests的一些列请求方式中,除了head方式,其他的都会自动处理重定向,上面的属性讲了,可以通过res.history可以查看发送了那些重定向 我们还可以通过allow_redirects参数设置不让他重定向 r = requests.get('http://github.com', allow_redirects=False)
三、反爬机制与反反爬
1,UA机制
User-Agent:请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器;使用爬虫程序发起的请求,请求载体为爬虫程序,所以可以通过判断UA值判断该请求是基于浏览器还是爬虫程序,门户网站对访问的UA进行判断时,如果是爬虫程序,就直接拒接提供数据
反反爬策略就是把我们的UA伪造成浏览器载体标识,我们只需要在请求头加上一个浏览器载体的UA就可以了
headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' }
这样就把请求体载体设置成了Google浏览器的UA标识
2,用户登录机制和cookie机制
也就是说,很多网站要求登录才能访问,它的反爬机制是:首先你得访问它的主页面,然后从主页面发送你得用户名密码到服务器,如果验证成功后,它会自动帮你重定向到你得页面,在这个过程,一般情况下,在你第一次访问它的主页面时会返回给你一个cookie,然后你发送用户名和密码的路径不是主页面的路径,而是另外的请求路径,而且他要求的数据结构还不一样。
反反爬策略:首先我们用浏览器去访问主页面,找到登录位置,输入一组错误的数据,然后点‘检查’,再点‘network’,把之前返回的包都清掉,然后点击‘登录’,这时候我们就得去分析下刚才接收的包,看看哪一个是含有我用户名和密码的数据,这个差不多就是我们要的包,再去看这个包请求的路径和数据结构,这是第一步做分析;第二步就是写爬虫程序,一般在发送登录数据的请求体里会包含第一次访问主页面返回的cookie,所以代码第一步是发送主页面请求,获取到返回的cookie,那这个cookie加上数据去访问登录的路径就差不多了。
2.1 页面分析
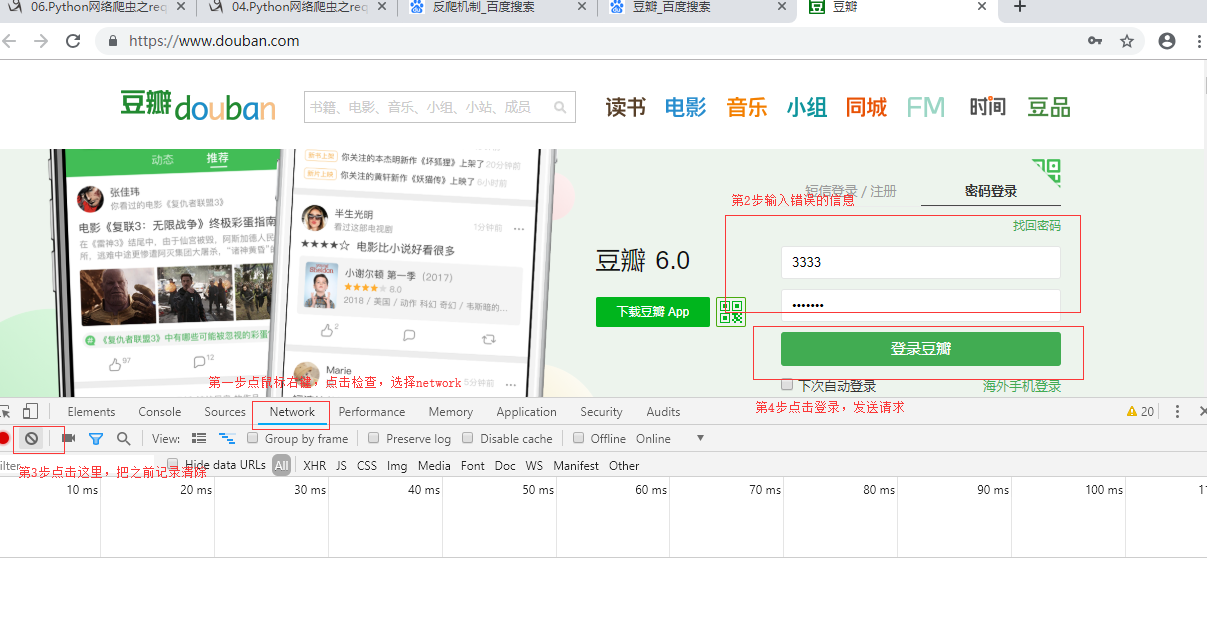
点击登录之后:
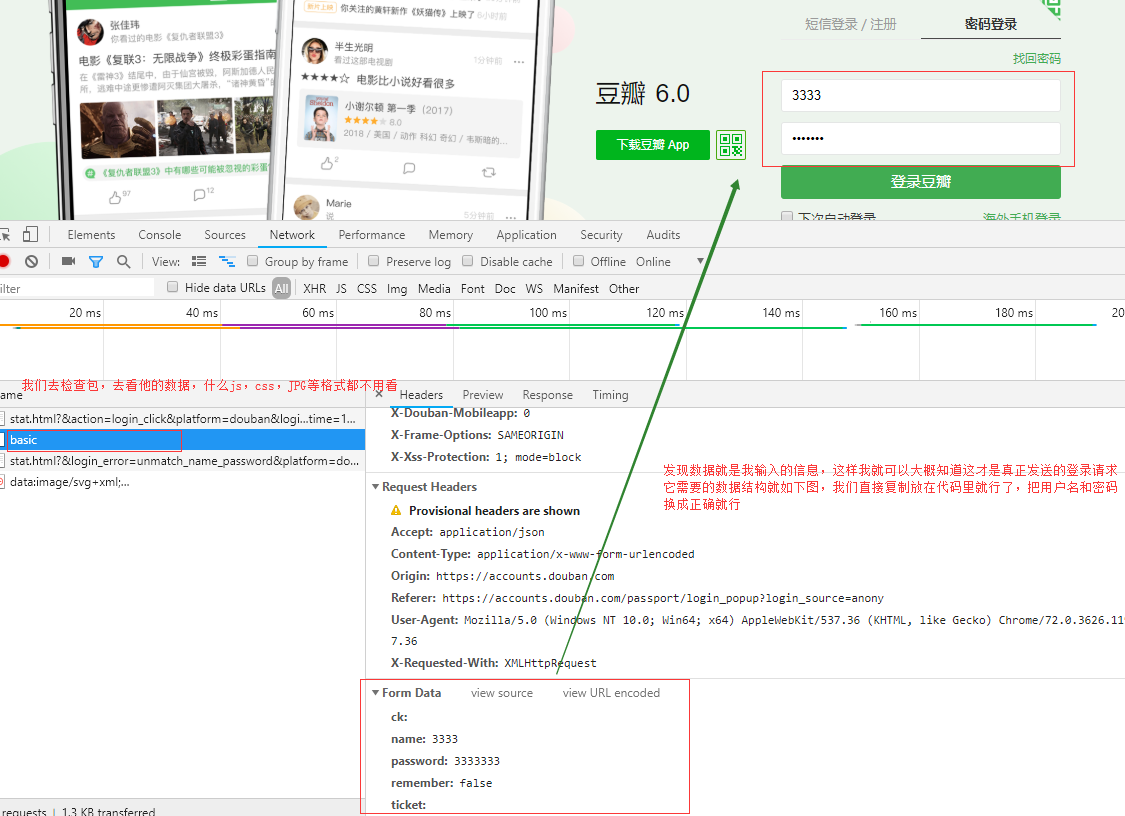
查看其他数据

2.2 书写爬虫代码
url1='https://www.douban.com/' #这是首页的路径 url2='https://accounts.douban.com/j/mobile/login/basic' #这是登录发送请求的路径 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } data={ #这是请求的数据 'ck': '', 'name': 'xxxxxx0', 'password':'hxxxxx', 'remember': 'false', 'ticket': ''} session=requests.session() session.get(url=url1,headers=headers) #这两步就会把我访问主页面的cookie放在session里面,从而我就不用把cookie取出来,下次直接用session发送请求就会自动带上返回的cookie res=session.post(url=url2,headers=headers,data=data) #这是带着返回的cookie向登录路径提交数据 print(res.text)
这整个过程就是一般登录程序的爬虫程序,在用session发送post请求时,如有重定向,会自动帮你重定向的,得到的res是最后重定向后的结果
但这个豆瓣网有点不同,我得到的res是一个json字符串,里面有很多信息,
{"status":"success","message":"success","description":"处理成功","payload":{"account_info":{"name":"黄麻口","weixin_binded":true,"phone":"18839124390",
"avatar":{"medium":"https://img3.doubanio.com\/icon\/up192624730-1.jpg","median":"https://img3.doubanio.com\/icon\/us192624730-1.jpg","large":"https://img3.doubanio.com\/icon\/ul192624730-1.jpg",
"raw":"https://img3.doubanio.com\/icon\/ur192624730-1.jpg","small":"https://img3.doubanio.com\/icon\/u192624730-1.jpg","icon":"https://img3.doubanio.com\/icon\/ui192624730-1.jpg"},"id":"192624730",
"uid":"192624730"}}}
我猜测,这个登录请求是用ajax发的,服务端验证用户成功后,返回一个json字符串,包含很多信息,比如第一个键值对‘status’:'success',ajax根据收到数据,再执行其他操作,比如status等于success时,带着cookie去访问主页面就可以成功了,
但我的爬虫程序不能实现ajax的重定向,所以我们可以用刚才返回的cookie去访问主页面就可以了,代码改变如下:
session.post(url=url2,headers=headers,data=data) #把上面的post请求改成这样就行了
res=session.get(url=url1,headers=headers)
3,IP限制机制
有些门户网站会检测某一段时间某个IP的访问次数,如果访问频率太快,比如1分钟访问几百次,这种显然不是人为手动点击访问,肯定是爬虫程序搞得,此时门户网站就会禁止这个IP的访问。
反反爬策略:就是使用代理IP,我每次访问不用自己的IP,就算被封了,下次再换个IP就行了。总共分为两类:一是正向代理,代理客户端获取数据,为了保护客户端,防止被追究责任;而是反向代理,代理服务器提供数据,为了保护服务器。网上的免费代理IP网站:‘快代理’
import requests import random if __name__ == "__main__": #不同浏览器的UA header_list = [ # 遨游 {"user-agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)"}, # 火狐 {"user-agent": "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1"}, # 谷歌 { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"} ] #不同的代理IP proxy_list = [ {"http": "112.115.57.20:3128"}, {'http': '121.41.171.223:3128'} ] #随机获取UA和代理IP header = random.choice(header_list) proxy = random.choice(proxy_list) url = 'http://www.baidu.com/s?ie=UTF-8&wd=ip' #参数3:设置代理 response = requests.get(url=url,headers=header,proxies=proxy) 当没有proxies参数时,就是用的自己的IP

