
MySQL之库、表操作
一、库操作
创建库 create database 库名(charset utf8 对库的编码进行设置,不写就用默认值) 库名可以由字母、数字、下划线、特殊字符,要区分大小写,唯一性,不能使用关键字,不能用数字开头,最长128位 查看数据库
注意:在cmd中输入指令是不区分大小写的 show databases; #这查看的是所有的库 show create database db1; #这是查看指定的库 select database(); #这是查看当前的库 选择数据库 USE 数据库名 #相当于在电脑上双击文件夹,进入文件夹 删除数据库 DROP DATABASE 数据库名; 修改数据库 alter database db1 charset utf8; #只能修改库的编码格式
二、表操作
1,存储引擎
存储引擎就是表的类型,MySQL中根据不同的存储引擎会有不同的处理机制,存储引擎的概念是MySQL里面才有的。
1.1,MySQL的一个整个工作流程
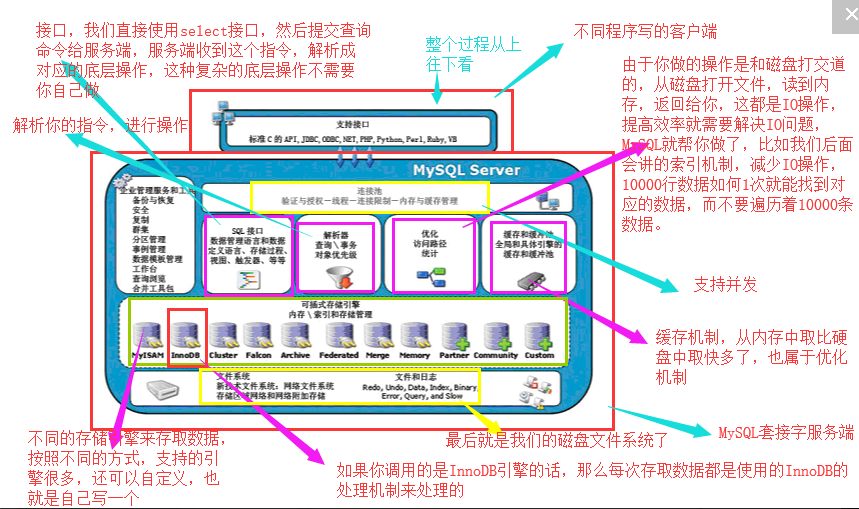
1.2,存储引擎的分类
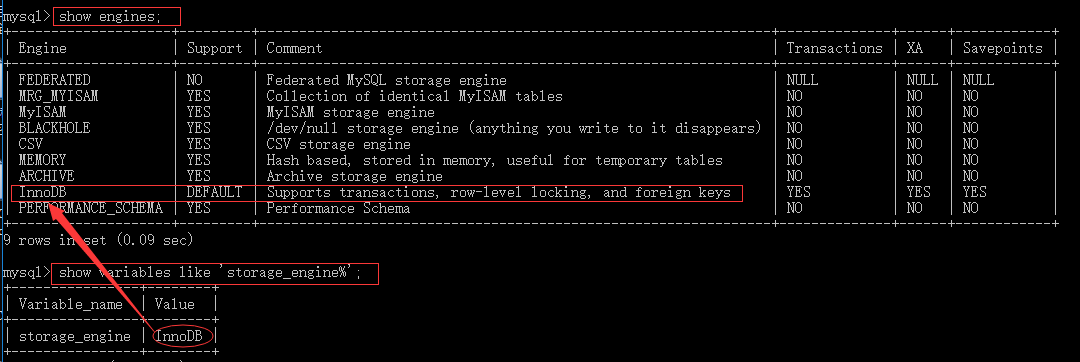
在cmd中输入show engines可以查看所有的引擎,输入show variables like 'storage_engine%'可以查看当前使用的引擎。
MyISAM引擎:
MyISAM引擎特点: 1.不支持事务 事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功要么全失败。 2.表级锁定 数据更新时锁定整个表:其锁定机制是表级锁定,也就是对表中的一个数据进行操作都会将这个表锁定,其他人不能操作这个表,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。 3.读写互相阻塞 不仅会在写入的时候阻塞读取,MyISAM还会再读取的时候阻塞写入,但读本身并不会阻塞另外的读。 4.只会缓存索引 MyISAM可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。 5.读取速度较快 占用资源相对较少 6.不支持外键约束,但只是全文索引 7.MyISAM引擎是MySQL5.5版本之前的默认引擎,是对最初的ISAM引擎优化的产物。
单一对数据库的操作可以使用MyISAM,就是尽量纯度、纯写
InnoDB引擎:
InnoDB引擎 介绍:InnoDB引擎是MySQL数据库的另一个重要的存储引擎,正称为目前MySQL AB所发行新版的标准,被包含在所有二进制安装包里。和其他的存储引擎相比,InnoDB引擎的优点是支持兼容ACID的事务(类似于PostGreSQL),以及参数完整性(即对外键的支持)。Oracle公司与2005年10月收购了Innobase。Innobase采用双认证授权。它使用GNU发行,也允许其他想将InnoDB结合到商业软件的团体获得授权。 InnoDB引擎特点: 1.支持事务:支持4个事务隔离界别,支持多版本读。 2.行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。 3.读写阻塞与事务隔离级别相关(有多个级别,这就不介绍啦~)。 4.具体非常高效的缓存特性:能缓存索引,也能缓存数据。 5.整个表和主键与Cluster方式存储,组成一颗平衡树。(了解) 6.所有SecondaryIndex都会保存主键信息。(了解) 7.支持分区,表空间,类似oracle数据库。 8.支持外键约束,不支持全文索引(5.5之前),以后的都支持了。 9.和MyISAM引擎比较,InnoDB对硬件资源要求还是比较高的。 小结:三个重要功能:Supports transactions,row-level locking,and foreign keys
Memory引擎:把数据放在内存中
BLACKHOLE引擎:黑洞引擎,数据放进去就消失
1.3,存储引擎的使用
create table 表名(id int)engine=InnoDB 在创建表的时候可以指定引擎
2,创建表
#语法: create table 表名(字段名1 类型[(宽度) 约束条件],字段名2 类型[(宽度) 约束条件],字段名3 类型[(宽度) 约束条件]); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选、非必须,宽度指的就是字段长度约束,例如:char(10)里面的10 3. 字段名和类型是必须的
show tables; #这是查看当前库下的所有表
describe 表名; #也可以写成desc 表名,这是查看表的结构
insert into 表名 values(填对应的数据); #这是向表里面插入数据
select 表名(字段)from 表名; #这是查看表中某字段的所有数据
select * from 表名; #这是查看表中所有字段的所有数据
3,MySQL的基础数据类型
3.1,整数类型:tinyint,smallint,mediumint,int,bigint
tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围:2**8 有符号:-128 ~ 127 无符号:0~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围:2**32 有符号:-2147483648 ~ 2147483647 无符号:0~ 4294967295 bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 2**64 有符号: -9223372036854775808 ~ 9223372036854775807 无符号:0 ~ 18446744073709551615
注意:对于整型来说,数据类型后面的宽度并不是存储长度限度,而是显示长度限制
3.2,浮点型:
1.FLOAT[(M,D)] [UNSIGNED] [ZEROFILL] 定义:单精度浮点数(非准确小数值),m是整数部分总个数,d是小数点后个数。m最大值为255,d最大值为30,例如:float(255,30] 有符号: -3.402823466E+38 to -1.175494351E-38, 1.175494351E-38 to 3.402823466E+38 无符号: 1.175494351E-38 to 3.402823466E+38 精确度: **** 随着小数的增多,精度变得不准确 **** 2.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL] 定义:双精度浮点数(非准确小数值),m是整数部分总个数,d是小数点后个数。m最大值也为255,d最大值也为30 有符号: -1.7976931348623157E+308 to -2.2250738585072014E-308 2.2250738585072014E-308 to 1.7976931348623157E+308 无符号: 2.2250738585072014E-308 to 1.7976931348623157E+308 精确度:****随着小数的增多,精度比float要高,但也会变得不准确 *** 3.decimal[(m[,d])] [unsigned] [zerofill] 定义:准确的小数值,m是整数部分总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。比float和double的整数个数少,但是小数位数都是30位 精确度:**** 随着小数的增多,精度始终准确 **** 对于精确数值计算时需要用此类型,decimal能够存储精确值的原因在于其内部按照字符串存储。 精度从高到低:decimal、double、float decimal精度高,但是整数位数少,float和double精度低,但是整数位数多,float已经满足绝大多数的场景了,但是什么导弹、航线等要求精度非常高,所以还是需要按照业务场景自行选择,如果又要精度高又要整数位数多,那么你可以直接用字符串来存。
在使用时,m必须大于d,不然会报错
3.3,日期类型:date,time,datetime,timestamp,year
year:YYYY(范围:1901/2155)2018 date:YYYY-MM-DD(范围:1000-01-01/9999-12-31)例:2018-01-01 time:HH:MM:SS(范围:'-838:59:59'/'838:59:59')例:12:09:32 datetime:YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00/9999-12-31 23:59:59 Y)例: 2018-01-01 12:09:32 timestamp:YYYYMMDD HHMMSS(范围:1970-01-01 00:00:00/2037 年某时)
常用写法:
create table t1(x datetime not null default now()); # 需要指定传入,空值时默认取当前时间
create table t2(x timestamp); # 无需任何设置,在传空值的情况下自动传入当前时间
3.4,字符串类型
CHAR 和 VARCHAR 是最常使用的两种字符串类型。 CHAR(N)用来保存固定长度的字符串,对于 CHAR 类型,N 的范围 为 0 ~ 255 VARCHAR(N)用来保存变长字符类型,对于 VARCHAR 类型,N 的范围为 0 ~ 65 535 CHAR(N)和 VARCHAR(N) 中的 N 都代表字符长度,而非字节长度。#CHAR类型 对于 CHAR 类型的字符串,MySQL 数据库会自动对存储列的右边进行填充(Right Padded)操作,直到字符串达到指定的长度 N。而在读取该列时,MySQL 数据库会自动将填充的字符删除。我们可以把sql——mode设置为 PAD_CHAR_TO_ FULL_LENGTH,就会显示填充的字符。#VARCHAR类型 VARCHAR 类型存储变长字段的字符类型,与 CHAR 类型不同的是,其存储时需要在前缀长度列表加上实际存储的字符,该字符占用 1 ~ 2 字节的空间。当存储的字符串长度小 于 255 字节时,其需要 1 字节的空间,当大于 255 字节时,需要 2 字节的空间。
length(字段) #查看该字段数据的字节长度
char——length(字段) #查看该字段数据的字符长度
3.5,枚举类型enum和集合类型set
enum:单选,只能在给定的范围内选一个值 set:多选,可以在给定的范围内选择一个或多个值 示例:
枚举
CREATE TABLE shirts (name VARCHAR(40),size ENUM('xsmall', 'small', 'medium', 'large', 'x-large')); INSERT INTO shirts VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
集合 CREATE TABLE myset (col SET('a', 'b', 'c', 'd')); INSERT INTO myset VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
4,表的完整性约束
4.1分类
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空,不设置默认可以为空的
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值,不设置默认为null
UNSIGNED 无符号,不设置默认为有符号的
ZEROFILL 使用0填充
4.2not null,default,unique,primary key,unsigned
create table t1(id int unsigned not null default 1) #表示id字段为无符号,不可以为空,默认值为1
create table t1(id int unique) #表示id字段的值不能重复
create table t1(id int ,name char(10),constraint ak_name unique(name)) #这也表示name不能重复
联合唯一:
create table t1(id int,name char(10),unique(id,name)) #表示必须不能出现id和name都相同
主键:相当于not null + unique
create table t1(id int primary key)
create table t1(id int,name char(10),constriaint pk_name primary key(id) #这是两种方式都可以设置主键,
联合主键:
create table t1(id int,name char(10),primary key(id,name))
4.3自动增长
create table t1(id int primary key auto_increment,name char(10)
insert into t1(name) values('nnn'),('sss'); #此时没有输入id,但id会从1开始自动增长
insert into t1 values(4,'rrr'); #当我们指定id了,就以指定的为准
insert into t1(name) values('tt') #现在的id也是自动增长,但是接着上一条的id开始增长
上面插入数据的id分别是:1,2,4,5
对于自动增长的字段,可以用delete删除数据,但再插入值时是按照删除前最后一条数据的id值开始增长
delete from t1
select * from t1; #现在为空的
insert into t1(name)values('rtsa') #由于删除前最后一条id为5,所以接上,那这一条id为6
用truncate清空表,在插入数据又是从1开始自增
truncate t1;
insert into t1(name) values('fsdf') #此时的id为1
在创建表的时候可以设定自动增长的起始值
create table t1(id int auto_increment,name char(10),auto_increment=3); #这样设定后,表的自动增长就从3开始
创建表以后,也可以修改自增起始值
alter table t1 auto_increment=4;
设置步长
set session auto_increment_increment=2; #这是设置会话级别的步长
set global auto_increment_increment=2; #这是设置全局级别的步长
例子:
set global auto_increment_increment=5;
set global auto_increment_offset=3;
最后得到的自动增长值为:1,6,11,16.。。。。。
4.4外键foreign key:其实就是表明表与表之间的关系,表与表之间有三种关系,一对一,一对多,多对多,在任何情况下都得先把‘一’的表(就相当于被指向的表)创建。
一对多关系

先创建‘一’的表,就是dep表
create table dep(id int primary key,name char(10),comment char(10)); #然后插入数据就行
在创建‘多’的表,就是emp表,在emp表中的dep_id,指向的是dep表中的id
create table emp(id int primary key,name char(10),gender enum('male','female'),dep_id int,foreign key(dep_id) references dep(id) on delete cascade on update cascade);
一对一关系:就只要把外键设为唯一的就行了
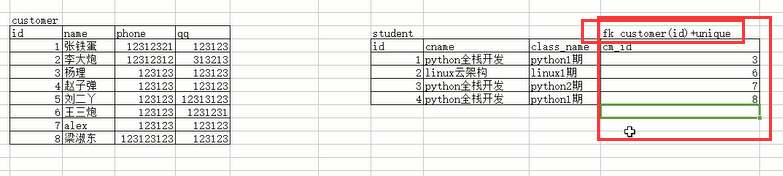
先创建被指向的表,即customer表
create table customer(id int primary key,name char(10),phone int,qq int);
在创建student表,表中的cm_id指向customer表中的id
create table student(id int primary key,cname char(10),class_name,cm_id int unique,foreign key(cm_id) references customer(id) on delete cascade on update cascade);
多对多关系:我们就应该建立第三个表(关联表)来连接连个表的关系

多对多关系表,就应该最后创建关联表就行,先创建另外两个表就行,即author表和book表
create table author(id int primary key,name char(10));
create table book(id int primary key,bname char(10),price int);
最后来创建关联表,即author表
create table author_book(id int primary key,author_id int,book_id int,foreign key(author_id) references author(id) on delete cascade on update cascade,
foreign key(book_id) references book(id) on delete cascade on update cascade);
注意:我们一般在创建表的时候最好把id设置为主键,其次是我们外键指向的字段必须是not null + unique的,最后是,在外键的后面加上on delete cascade on update cascade,作用在于外键的值会跟随指向的字段的值改变而改变
5,表的修改alter table
语法: 1. 修改表名 ALTER TABLE 表名 RENAME 新表名 2. 增加字段 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], #注意这里可以通过逗号来分割,一下添加多个约束条件 ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; #添加这个字段的时候,把它放到第一个字段位置去。 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;#after是放到后的这个字段的后面去了,我们通过一个first和一个after就可以将新添加的字段放到表的任意字段位置了。 3. 删除字段 ALTER TABLE 表名 DROP 字段名; 4. 修改字段 ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…];#modify给字段重新定义类型和约束条件,但已经有主键是不能修改,也不需要再写 ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; #change比modify还多了个改名字的功能,这一句是只改了一个字段名 ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];#这一句除了改了字段名,还改了数据类型、完整性约束等等的内容
5.增加复合主键
alter table 表名 add primary key(字段,字段)
6.删除主键
alter table 表名 drop primary key #主键只能通过这方式进行删除
6,复制表
方法一
alter table t2 select * from t1; #复制结构+数据
这种情况下可以指定复制表的某些字段,只需把*换成表名(字段)就行,但是不能复制主键、外键、自动增长约束条件
alter table t2 select * from t1 where 1=0; #因为1=0为假的,所以找不到对应数据,就只复制结构
方法二
create table t2 like t1;
这种方法只复制结构,没有数据,但所有的约束条件都复制了

