
201671010439温永琴 实验四 《英文文本统计分析》结对项目报告
任务一1:github地址:https://www.cnblogs.com/jsfrjgc/p/10562331.html
阅读结对方博客,博客内容结构清晰,代码写的非常不错,按照老师的要求进行。但需要在完善一下代码,充实博客内容。需要更加详细的数据证实代码运行的完整性和可行性。还有就是博文可以在写的规整和详细。代码有点错误再更正一下。
2.克隆对方项目,阅读并测试运行代码,结合运行结果评论程序代码 。链接地址:https://github.com/jinshengfang123/jiedui
2:结对方项目:
StringTokenizer st = new StringTokenizer(file," ,.!?\"'"); //用于切分字符串
TreeMap hm = new TreeMap<>();
while(st.hasMoreTokens()) {
String word = st.nextToken();
if(hm.get(word) != null) {
int value = ((Integer)hm.get(word)).intValue();
value++;
hm.put(word, new Integer(value));
}
else {hm.put(word, new Integer(1));
}
}
TreeMap tm = new TreeMap(hm);
ByValueComparator bvc = new ByValueComparator(tm);
List<String> ll = new ArrayList<String>(tm.keySet());
Collections.sort(ll, bvc);
for(String str:ll){
System.out.println(str+"——"+tm.get(str));
}
}
}
运行结果: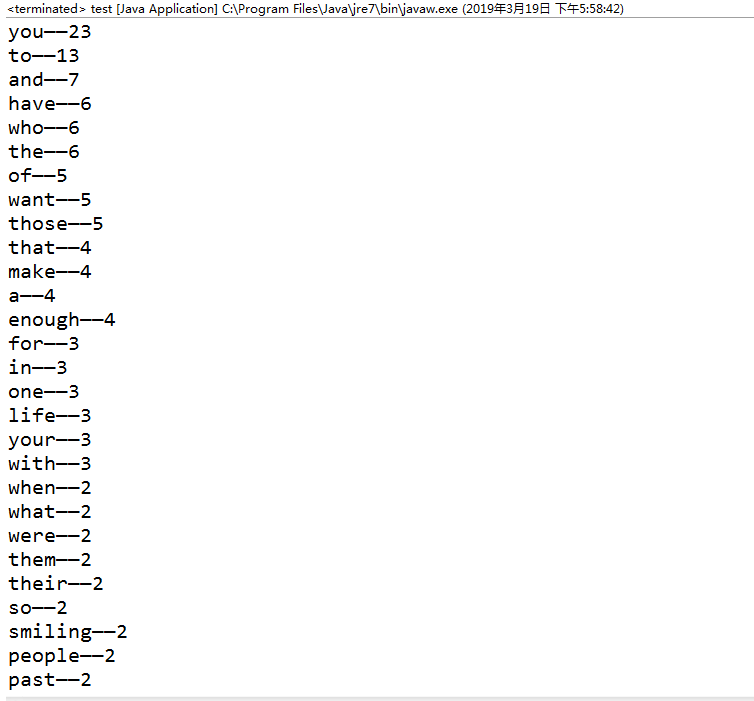
任务二:
主要代码:
ublic class tongjidancishumu{
private static Map<String, Integer> words = new HashMap<String,Integer>();
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String src = "E:/Word.txt";
String wenzhang=ReadSrc(src);
words = Count(wenzhang);
Iterator<String> it = words.keySet().iterator();
while(it.hasNext()){
Object key = it.next();
System.out.println(key);
System.out.println(words.get(key));
}
}
运行结果: 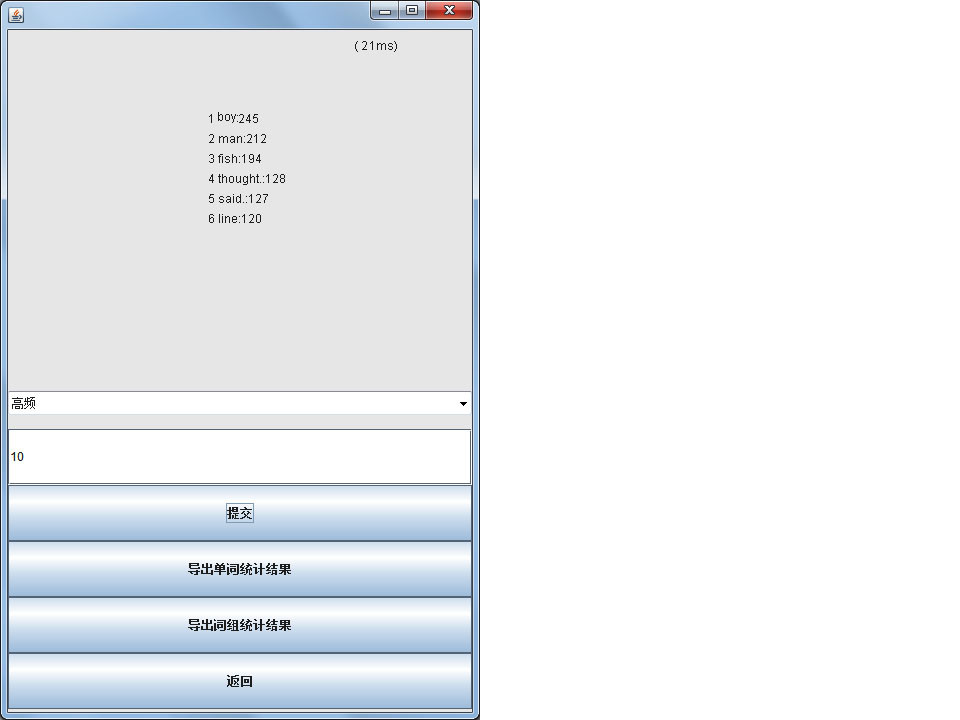
3.此次任务是由我和我的结对博友一起经过协作讨论共同完成。我们两人一起查阅资料,并且得到同学的帮助下完成。如下图是我和结对成员一起讨论、细化和 编程的图片:

任务三:
博文简要信息表
| PSP2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
| Planning | 计划 |
30 |
26 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 20 | 20 |
| Development | 开发 | 100 | 100 |
| Analysis | 需求分析 (包括学习新技术) | 23 | 30 |
| Design Spec | · 生成设计文档 | 20 | 10 |
| Design Review | · 设计复审 (和同事审核设计文档) | 50 | 60 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 45 |
| Design | 具体设计 | 35 | 40 |
| Coding | 具体编码 | 60 | 77 |
| Code Review | 代码复审 | 20 | 25 |
| Test | 测试(自我测试,修改代码,提交修改) | 10 | 10 |
| Reporting | 报告 | 10 | 10 |
| Test Report | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 200 | 250 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 20 | 20 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号