RDD编程实践2-编写独立应用程序实现数据去重,实现求平均值问题
(1)编写独立应用程序实现数据去重
package my.scala import org.apache.spark.{SparkConf, SparkContext} object case2 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("reduce") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") //获取数据 val two = sc.textFile("file:///usr/local/spark/text_4/sec") two.filter(_.trim().length>0) //trim()函数返回空格个数 .map(line=>(line.trim,""))//全部值当key,(key value,"") .groupByKey()//groupByKey,过滤重复的key value ,发送到总机器上汇总 .sortByKey() //按key value的自然顺序排序 .keys.collect().foreach(println)//collect是将结果转换为数组的形式 } }
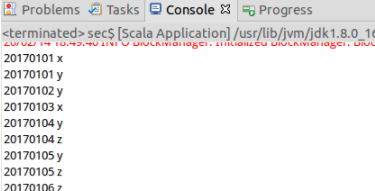
(2)编写独立应用程序实现求平均值问题
package my.scala import org.apache.spark.{SparkConf, SparkContext} object pingjunzhi { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("reduce") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") val fourth = sc.textFile("file:///usr/local/spark/text_4/thi") val res = fourth.filter(_.trim().length>0).map(line=>(line.split("\t")(0).trim(),line.split("\t")(1).trim().toInt)).groupByKey().map(x => { var num = 0.0 var sum = 0 for(i <- x._2){ sum = sum + i num = num +1 } val avg = sum/num val format = f"$avg%1.2f".toDouble (x._1,format) }).collect.foreach(x => println(x._1+"\t"+x._2)) } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号