pandas数据分析第二天
一:汇总和计算描述统计
pandas对象拥有一组常用的数据和统计方法,用于从Series中提取单个值(sum,mean)或者从DataFrame的行或者列中提取一个Series对应的Numpy数组方法相比
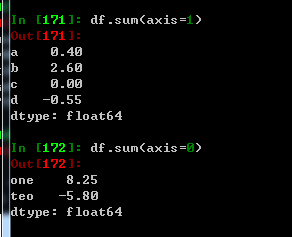
调用sum可以返回一个小计,传入axis=1会按照行进行计算, axis=0,按照列进行计算
sum或者mean里面可与约简方法的选项
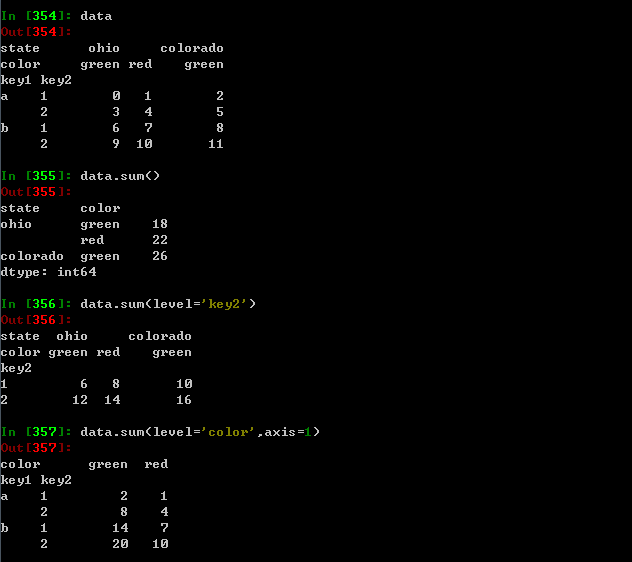
axis 约简的轴,DateFrame的行为0,列为1
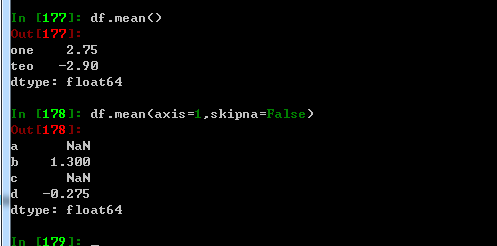
skipna 排除缺失值,默认为TRUE
level 如果轴层次化索引的,则根据level分组约简
还有些方法是间接统计,idxmin达到最小值索引,idxmax达到最大值索引
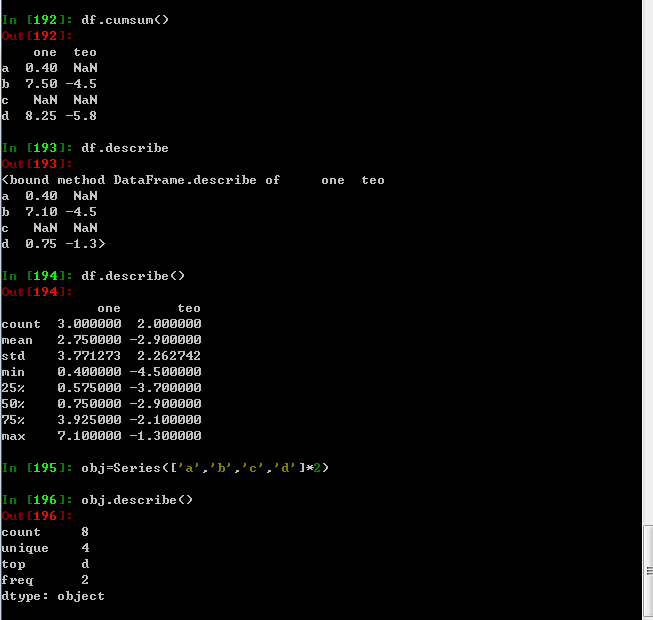
cumsum 累计型统计,
describe 既不是累计型,也不是约简行,它用于一次性产出多个汇总统计,对于非数值型数据,describe 会产生另一种汇总,查看最下图
描述汇总统计的方法汇总
count 非NA值的数量
describe 针对Series 或者DataFrame列计算汇总统计
min,max 计算最小值和最大值
argmin argmax 计算能够获取得到最小值和最大值的索引位置(整数)
idxmin idxman 计算能够获取最小值和最大值的索引值
quantile 计算样本的分位数(0到1)
sum 值的总和
mean 值的平均数
median 值的算术中位数(50%分位数)
mad 根据平均值计算平均绝对离差
var 样本值的方差
std 样本值的标准差
skew 样本值的偏度
kurt 样本值的累计
cumsum 样本值的累计和
cummin cummax 样本值的累计最大值和累计最小值
cumprod 样本值的累计积
diff 计算一阶差分(对时间序列很有用)
pct_change 计算百分数变化

由于NA值会自动去吃,如果禁止该功能可以采用skipna=false
二:相关系数与协方差
pass
三:唯一值,值计数,以及成员资格
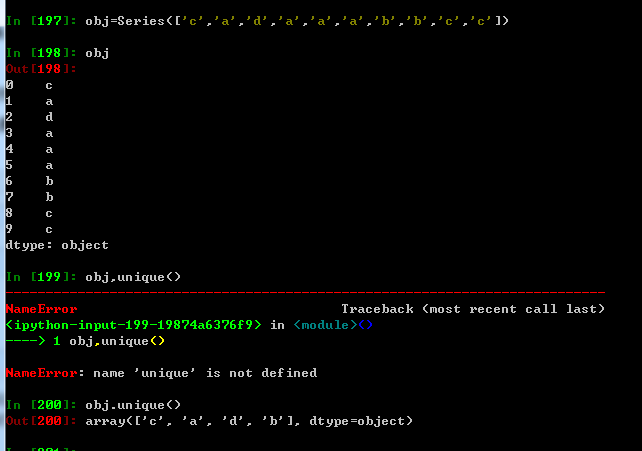
unique 可以得到唯一值
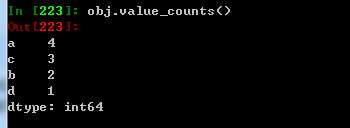
value_counts 返回一个Series 其索引为唯一值,其值为频率,按计数值降序排序
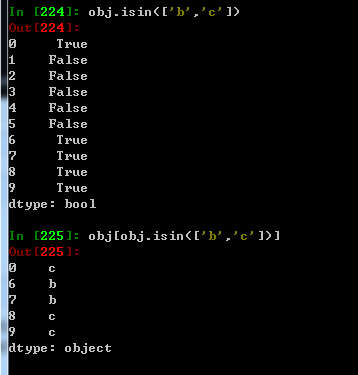
isin 计算一个表示Series各值是否包含传入值序列中的布尔数据类型

四:处理缺失数据
NA处理方法:
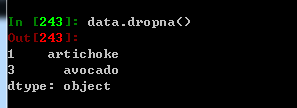
dropna 根据各标签的值中是否存在缺失数据对轴标签进行过滤,可通过阀值调节对缺失值的容忍度
fillna 用于指定值或者插入值方法 如fill和bfill 填充数据缺失值
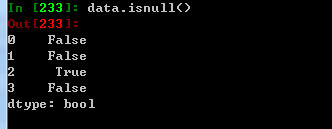
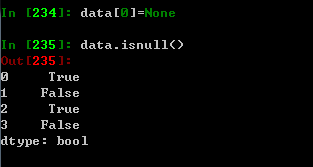
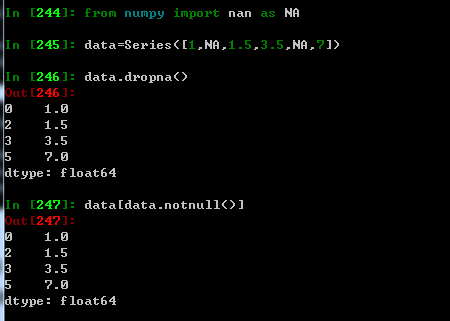
isnull 返回一个布尔值对象,这些布尔值表示哪些值是缺失值,其中None也会被当做缺失值处理
notnull isnull的否定式
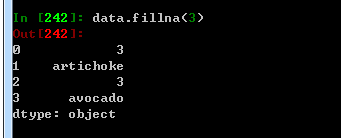
五:滤除缺失数据
比如上面提到的,,直接用dropna删除最直接,也可以通过notnull,下面总结一些常用的方法
Series中处理缺失值 dropna notnull
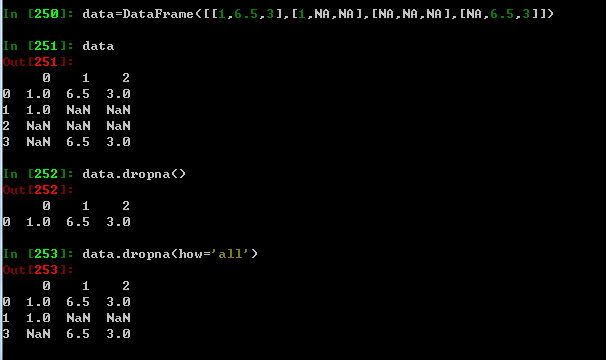
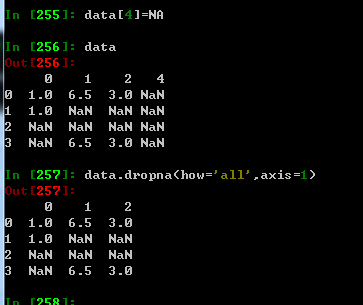
dataframe处理缺失值dropna会将带有NA全部丢弃,传入参数how=’all' 只会丢弃全部为NA的行,看下面例子
传入参数how=‘all' axis=1 只会丢去全部为NA列的
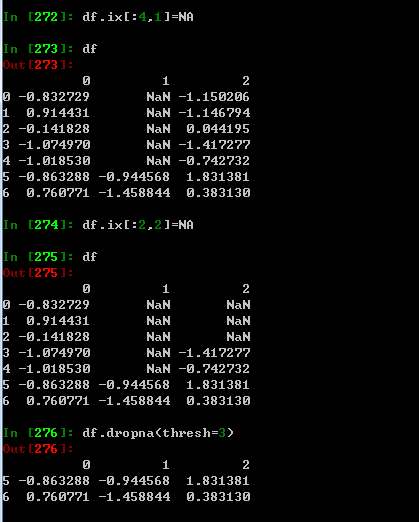
另一个滤除DataFrame行的问题涉及时间序列数据,假设你只是想留下一部分观测数据,可以用tjresh参数实现
另一个滤除DataFrame行的问题涉及时间序列数据,假设你只是想留下一部分观测数据,可以用tjresh参数实现

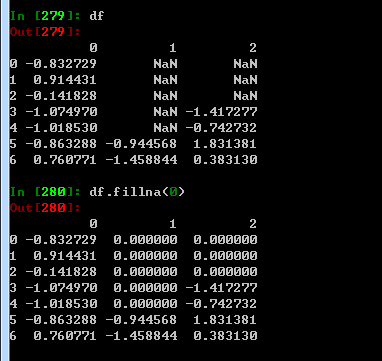
六:填充缺失值
可以选用参数fillna
fillna选择参数:
value 用于填充缺失值的标量值或者字典对象
method 插值方式 如果函数调用时未指定其他参数的话,默认为ffill
axis 待填充的轴,默认axis=0
inplace 修改调用者对象而不产生副本
limit (对于前向和后向填充)可以连续填充的最大数量
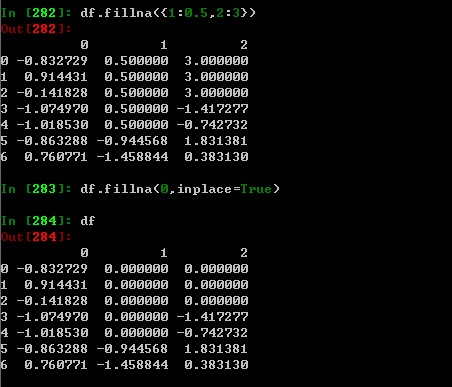
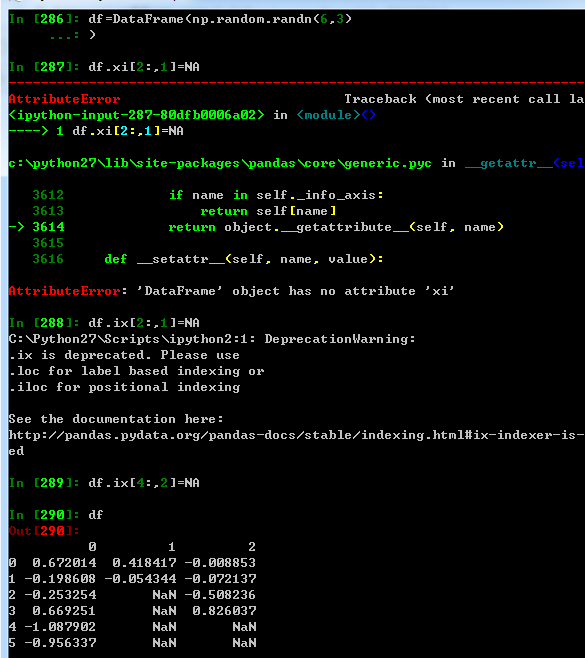
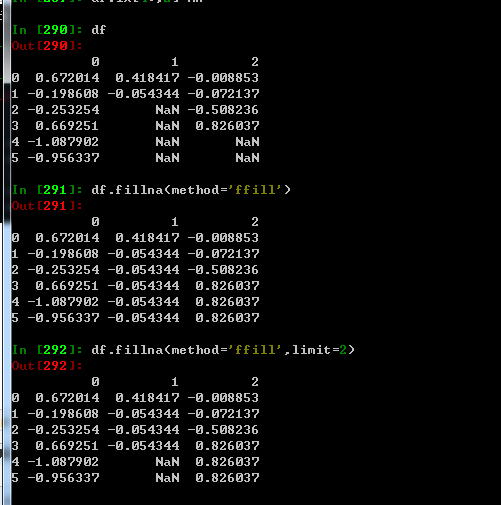
fillna 可以实现很多功能,比如里面可以传sum,mean等
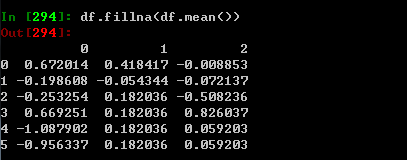
七:层次化索引
带有MultiIndex索引的Series的格式化输出形式。索引之间的’间隔‘表示’直接使用上面的标签‘
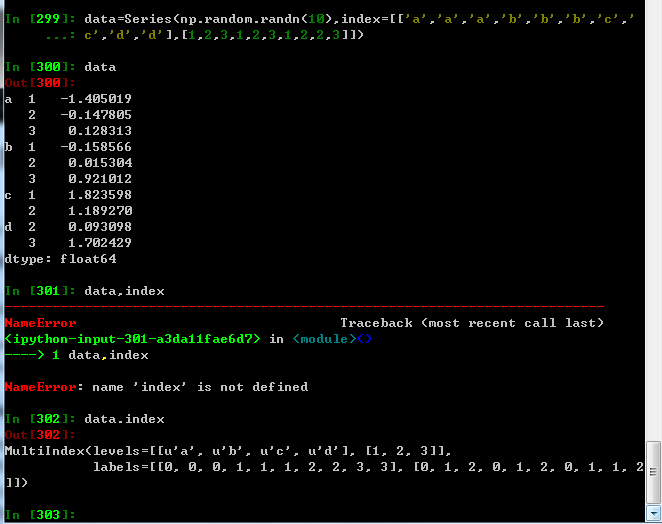
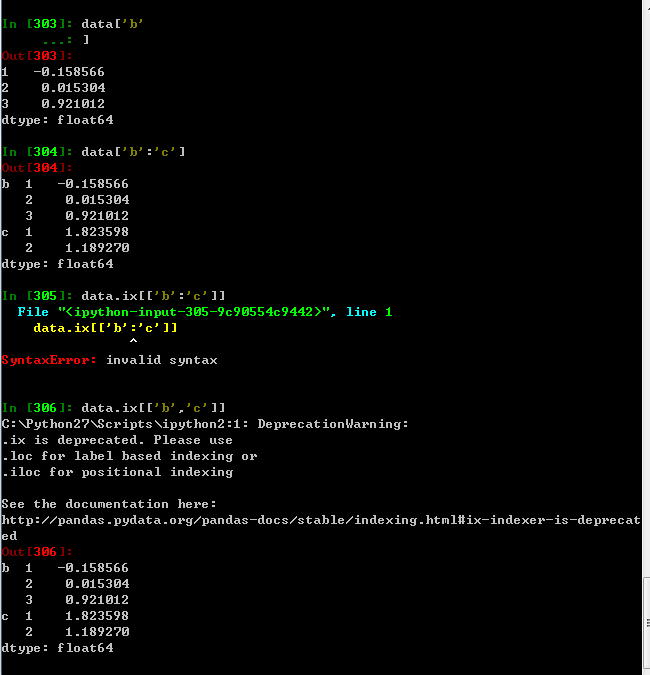
层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色,比如说,这段数据可以通过其unstack方法被重新安排带一个DataFrame中
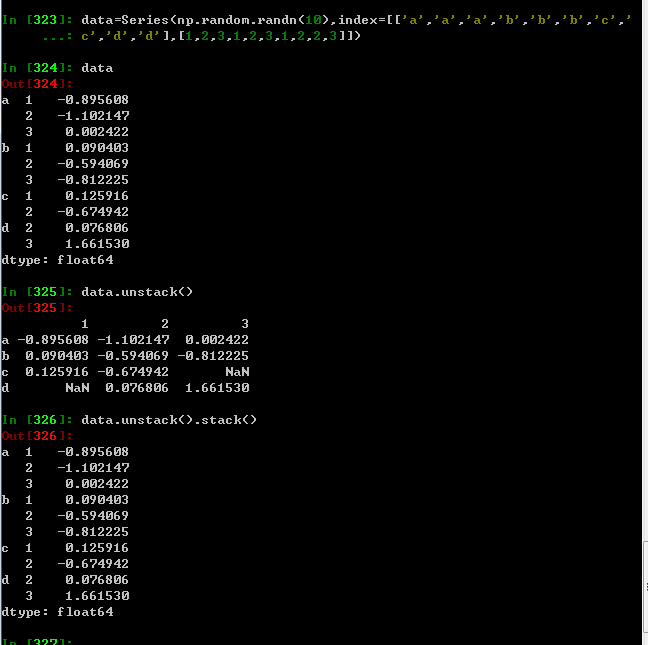
对于DataFrame
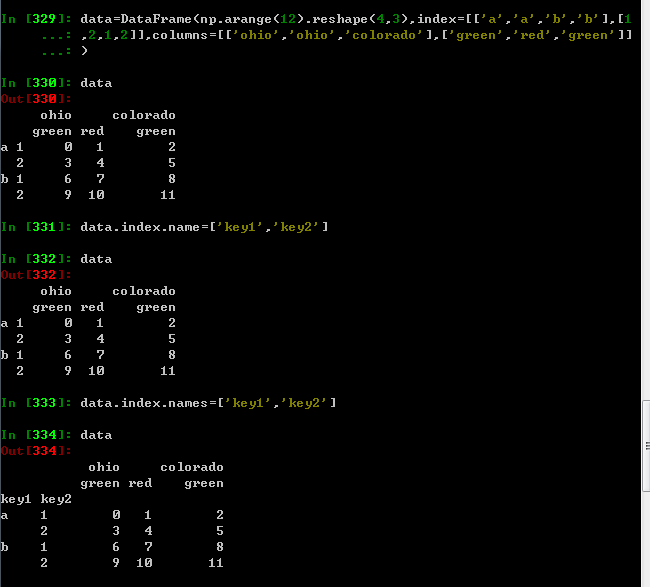
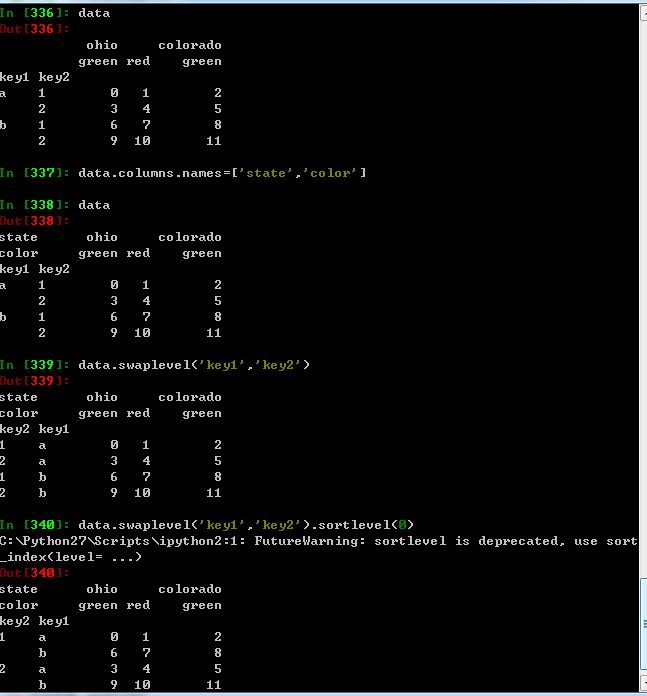
八:重排分级顺序
需要重新调整某条轴上各级别的顺序,或者指定级别上的值对数据进行排序,swaplevel接收两个级别编号或者名称,并返回一个交互啦级别的新对象,而sortlevel则根据单个级别中的值对数据进行排序,交换级别是,常常会用到sortlevel,这样的结果就是有序的
九:根据级别汇总统计
根据DataFrame和Series的描述和汇总统计都有一个level的选项,它用于指定在某条轴上求和的级别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号