
编码
py2编码

py3编码
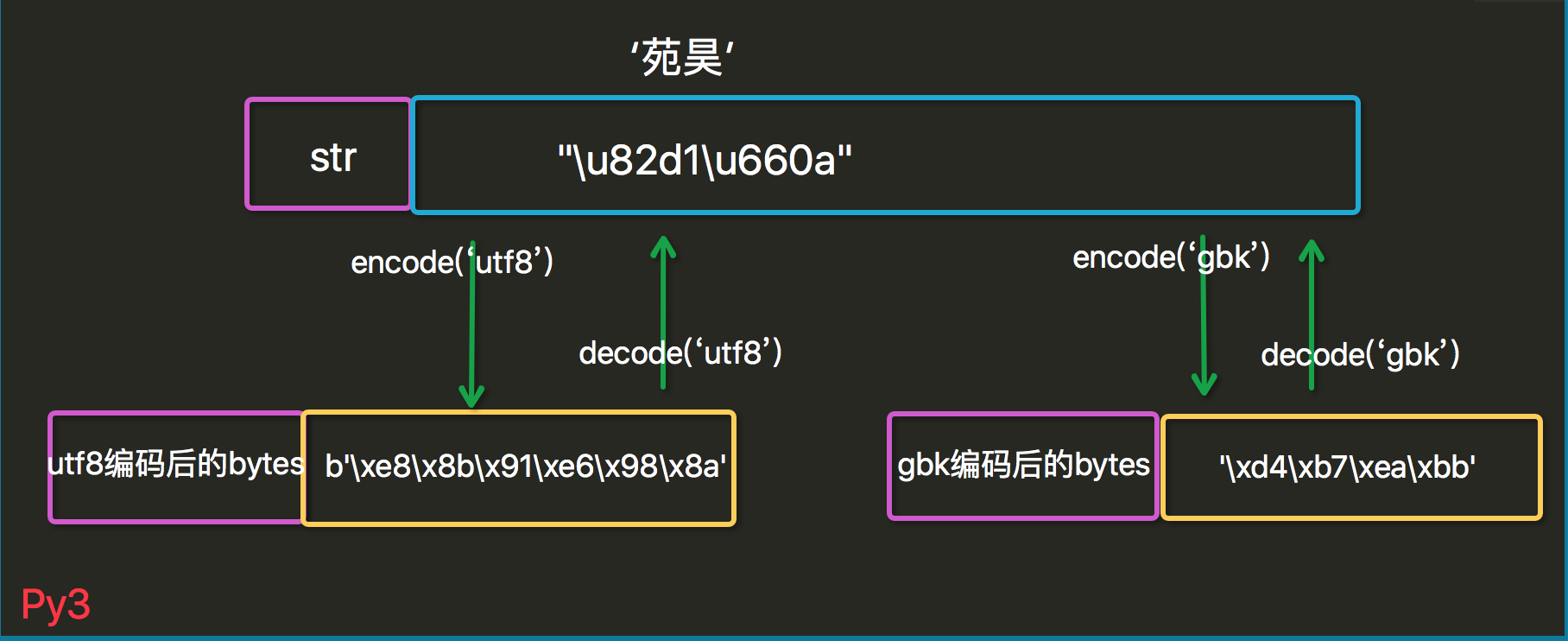
默认编码
什么是默认编码?其实就是你的解释器解释代码时默认的编码方式,在py2里默认的编码方式是ASCII,在py3里则是utf8(sys.getdefaultencoding()查看)。
#-*- coding: UTF-8 -*-
这个声明是做什么的? 因为py2默认的ASCII码,对于中文这些特殊字符无法编码;声明这句话就是告诉python2.7解释器 (默认ACSII编码方式)解释hello.py文件声明下面的内容按utf8编码
1 cmd下的乱码问题
hello.py
#coding:utf8 print ('苑昊')
文件保存时的编码也为utf8。
思考:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身就是一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print'苑昊'时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe显示,而在py2里这个内容就是utf8编码的字节数据,而这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,符合ISO统一标准的,所以没问题。
print (u'苑昊')
改成这样后,cmd下用2也不会有问题了。
2 print问题
在py2里
#coding:utf8 print ('苑昊') #苑昊 print (['苑昊','yuan']) #['\xe8\x8b\x91\xe6\x98\x8a', 'yuan']
在py3里
print ('苑昊') #苑昊 print (['苑昊','yuan']) #['苑昊', 'yuan']


 浙公网安备 33010602011771号
浙公网安备 33010602011771号