第六次作业
作业①
爬取豆瓣电影
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
输出信息:

代码
import requests
from bs4 import BeautifulSoup
import re
import urllib.request
import threading
start_url = 'https://movie.douban.com/top250'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
def download(url, name): #图片下载
try:
f = urllib.request.urlopen(url)
with open("D:/new file/images/" + name + ".jpg", "wb") as wri:
wri.write(f.read())
except Exception as e:
print(e)
def spider(start_url):
try:
web_html = requests.get(url=start_url, headers=headers).text
soup = BeautifulSoup(web_html, "lxml")
lis = soup.select("ol > li")
for li in lis: #获取每部电影信息
rank = li.select('div[class="pic"] em')[0].text
name = li.select('span[class="title"]')[0].text
detail_url = li.select('div[class="hd"] a')[0]['href']
detail = BeautifulSoup(requests.get(url=detail_url, headers=headers).text, "lxml")
director = detail.select('div[id="info"] span')[0].select('span[class="attrs"] a')[0].text
star = detail.select('span[class="actor"] span')[1].select('span a')[0].text
show_time = re.findall('.*(\d{4}).*/.*/.*', li.select('div[class="bd"] p')[0].text)[0]
country = re.findall('.*/(.*?)/.*', li.select('div[class="bd"] p')[0].text)[0]
type = ''
for types in detail.select('div[id="info"] span[property="v:genre"]'):
type += '/' + types.text
grade = detail.select('strong[class="ll rating_num"]')[0].text
comment = detail.select('a[class="rating_people"] span')[0].text
quote = li.select('p[class="quote"] span')[0].text
file_path = detail.select('a[class="nbgnbg"] img')[0]['src']
T = threading.Thread(target=download, args=(file_path, name))
T.setDaemon(False) #设置为后台线程
T.start()
thread.append(T)
print(rank, name, director, star, show_time, country, type, grade, comment, quote, file_path)
except Exception as e:
print(e)
thread = []
spider(start_url)
for t in thread:
t.join()
print("the End")
运行结果部分展示:
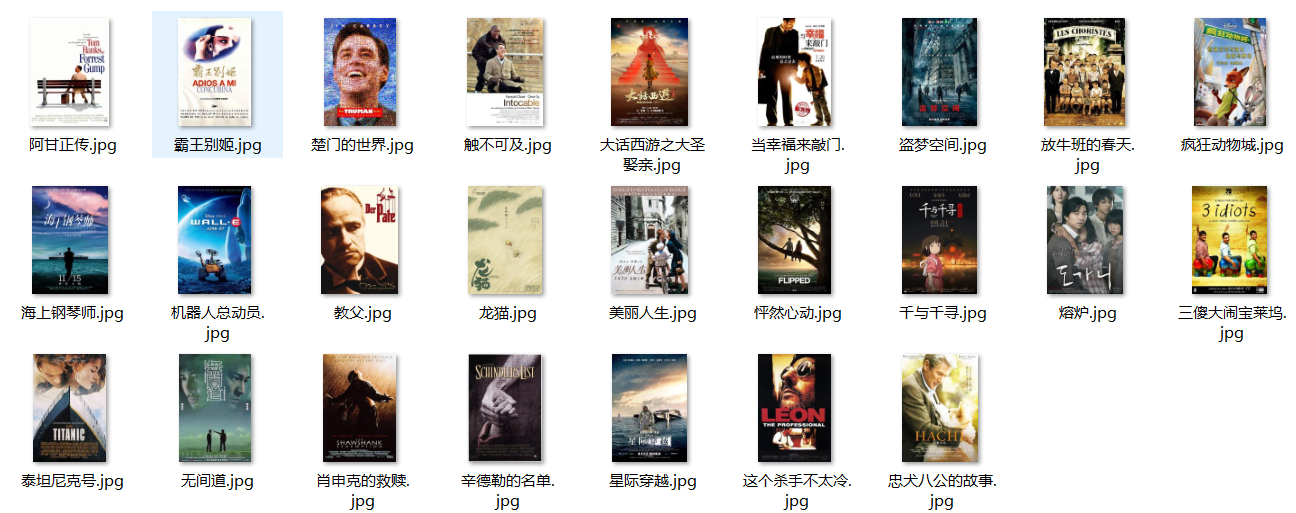

心得体会
温习一下beautifulsoup,很久没用都忘了。
作业②
爬取大学排名信息
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
关键词:学生自由选择
输出信息:MYSQL的输出信息如下

spider:
import urllib
import scrapy
from rank.items import RankItem
import requests
from scrapy.selector import Selector
class SpiderSpider(scrapy.Spider):
name = 'spider'
start_urls = ['https://www.shanghairanking.cn/rankings/bcur/2020']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
def parse(self, response):
trs = response.xpath('//*[@id="content-box"]/div[2]/table/tbody/tr')
for tr in trs:
Sno = tr.xpath('./td[1]/text()').extract_first().strip()
sschoolName = tr.xpath('./td[2]/a/text()').extract_first().strip()
city = tr.xpath('./td[3]/text()').extract_first().strip()
item = RankItem()
item['Sno'] = Sno
item['sschoolName'] = sschoolName
item['city'] = city
new_detail_url = "https://www.shanghairanking.cn"+tr.xpath('./td[2]/a/@href').extract_first()
data=requests.get(new_detail_url,headers=self.headers)
data.encoding=data.apparent_encoding #从网页内容分析编码格式
dt=Selector(text=data.text)
officalUrl = dt.xpath('//div[@class="univ-website"]/a/text()').extract_first()
info = dt.xpath('//div[@class="univ-introduce"]/p/text()').extract_first()
item['officalUrl']=officalUrl
item['info']=info
url = dt.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
print(item['Sno'],item['sschoolName'],item['city'],item['officalUrl'],item['info'])
try:
f = urllib.request.urlopen(url) # 图片写入文件夹
with open("D:/new file/images/" + sschoolName + ".jpg", "wb") as wri:
wri.write(f.read())
except Exception as e:
print(e)
yield item
def download(url, name):
try:
f = urllib.request.urlopen(url) # 图片写入文件夹
with open("D:/new file/images/" + name + ".jpg", "wb") as wri:
wri.write(f.read())
except Exception as e:
print(e)
items:
import scrapy
class RankItem(scrapy.Item):
Sno=scrapy.Field()
sschoolName=scrapy.Field()
city=scrapy.Field()
officalUrl=scrapy.Field()
info=scrapy.Field()
pipelines:
import pymysql
from itemadapter import ItemAdapter
class RankPipeline:
conn = None
cursor = None
def open_spider(self, spider):
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='spider', # 连接数据库
charset='utf8')
def process_item(self, item, spider):
self.cursor = self.conn.cursor()
try: # 插入数据
self.cursor.execute('insert into t_rank values(%s,%s,%s,%s,%s)',
(item["Sno"], item["sschoolName"], item['city'], item['officalUrl'], item['info']
))
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close() # 关闭连接
self.conn.close()
setting:
BOT_NAME = 'rank'
SPIDER_MODULES = ['rank.spiders']
NEWSPIDER_MODULE = 'rank.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'rank (+http://www.yourdomain.com)'
LOG_LEVEL = 'ERROR' # 日志级别设为ERROR
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
ITEM_PIPELINES = {
'rank.pipelines.RankPipeline': 300,
}
运行结果部分展示:
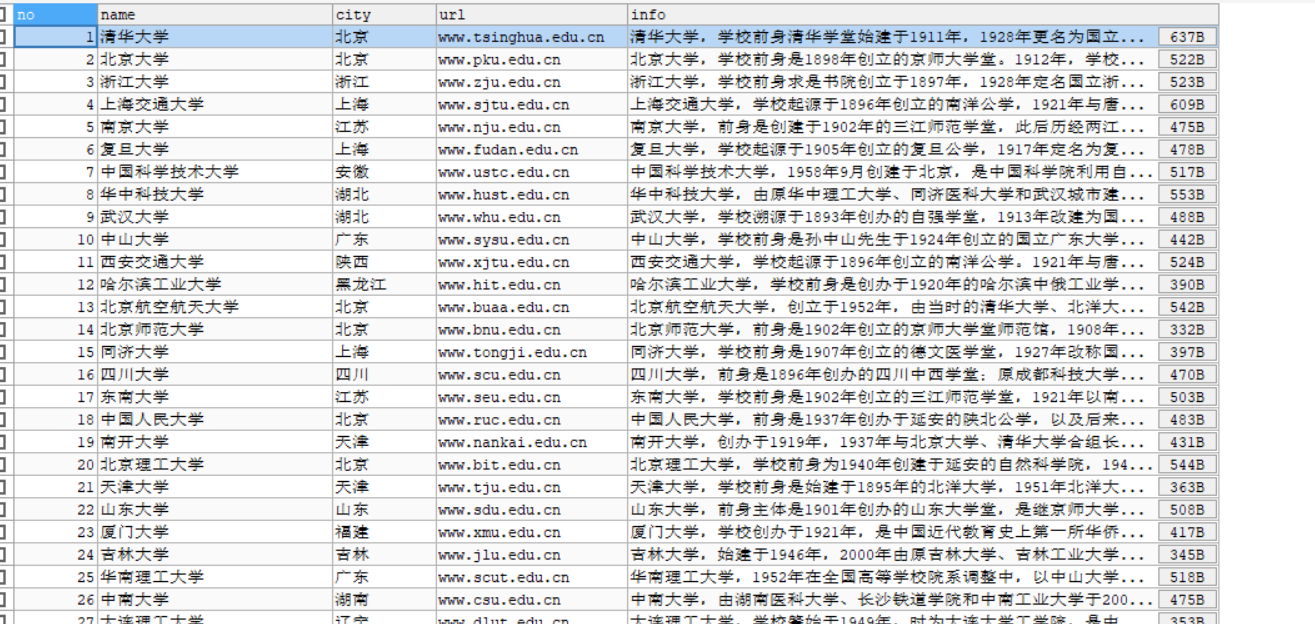

心得体会
复习scrapy框架。
作业③
爬取mooc课程
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式如下

代码:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from time import sleep
import pymysql
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(options=option)
driver.get("https://www.icourse163.org/")
driver.maximize_window()
sleep(2)
driver.find_element_by_xpath('//div[@class="unlogin"]//a[@class="f-f0 navLoginBtn"]').click() #登录或注册
sleep(2)
driver.find_element_by_class_name('ux-login-set-scan-code_ft_back').click() #其他登录方式
sleep(2)
driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']//li[@class='']").click()
sleep(2)
driver.switch_to.frame(driver.find_element_by_xpath("//div[@class='ux-login-set-container']//iframe"))
driver.find_element_by_xpath('//input[@id="phoneipt"]').send_keys("******") #输入账号
sleep(2)
driver.find_element_by_xpath('//input[@placeholder="请输入密码"]').send_keys("******") #输入密码
sleep(2)
driver.find_element_by_xpath('//div[@class="f-cb loginbox"]//a[@id="submitBtn"]').click() #点击登录
sleep(3)
driver.find_element_by_class_name('_3uWA6').click()
sleep(2)
id=0
conn = None
cursor = None
conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='root', db='spider', charset='utf8')
cursor = conn.cursor()
divs=driver.find_elements_by_xpath('//div[@class="course-panel-body-wrapper"]/div')
driver.execute_script("window.scrollTo(0,50)")
for i in range(len(divs)): #点击添加的课程
div=driver.find_elements_by_xpath('//div[@class="course-panel-body-wrapper"]/div')[i]
div.click()
sleep(4)
driver.switch_to.window(driver.window_handles[-1])
sleep(4)
driver.find_element_by_xpath('//h4[@class="f-fc3 courseTxt"]').click() #进入详细页
sleep(4)
driver.switch_to.window(driver.window_handles[-1])
sleep(4)
id += 1
course = driver.find_element_by_xpath('//span[@class="course-title f-ib f-vam"]').text
process = driver.find_element_by_xpath(
'//div[@class="course-enroll-info_course-info_term-info_term-time"]/span[2]').text
college = driver.find_element_by_xpath('//*[@id="j-teacher"]/div/a/img').get_attribute("alt")
count = driver.find_element_by_xpath(
'//span[@class="course-enroll-info_course-enroll_price-enroll_enroll-count"]').text
brief = driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
teacher = driver.find_element_by_xpath('//div[@class="cnt f-fl"][1]/h3').text
team = ""
teas = driver.find_elements_by_xpath('//div[@class="um-list-slider_con"]/div')
if len(teas) > 1:
for tea in teas:
team = team + tea.find_element_by_xpath('.//div[@class="cnt f-fl"]/h3').text # 教师拼接
else:
team = teacher
print(id,course, college, teacher, team, process, brief)
try:
cursor.execute('insert into mooc values("%s","%s","%s","%s","%s","%s","%s","%s")' %
(id, course, college, teacher, team, count, process, brief)) # 插入数据
conn.commit()
except:
conn.rollback()
sleep(4)
driver.close()
driver.switch_to.window(driver.window_handles[-1])
sleep(4)
driver.close()
sleep(3)
driver.switch_to.window(driver.window_handles[0])
driver.quit()
cursor.close()
conn.close()
运行结果部分展示:

心得体会
页面切换真的烦人呐!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号