第三次作业
作业①
单、多线程爬取照片
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
单线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import time
def imageSpider(start_url):
global thread
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
try:
if url[-4] == ".":
name = url.split("/")[-1]
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open('D:/new file/images1/' + name, "wb") #创建打开文件夹
fobj.write(data)
fobj.close()
print("downloaded " + name)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn/weather1d/101280501.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
thread = []
time_start = time.time() #开始计时
imageSpider(start_url)
print("the End")
time_end = time.time() #计时结束
print(time_end - time_start) #输出耗时
运行结果部分截图:


多线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import time
def imageSpider(start_url):
global thread
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
T = threading.Thread(target=download, args=(url,))
T.setDaemon(False)
T.start()
thread.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
try:
if url[-4] == ".":
name = url.split("/")[-1]
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open('D:/new file/images/' + name, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + name)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn/weather1d/101280501.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
thread = []
time_start = time.time()
imageSpider(start_url)
for t in thread:
t.join()
print("the End")
time_end = time.time()
print(time_end - time_start)
运行结果部分截图:

心得体会
实践了一下多线程的代码,也解决了遇到的问题。(对于thread.Thread()的参数args是一个数组变量参数,如果只传递一个值,就只需要url, 如果需要传递多个参数,那么还可以继续传递下去其他的参数,其中的逗号不能少,元组中只包含一个元素时,需要在元素后面添加逗号。)
作业②
scrapy爬取照片
要求:使用scrapy框架复现作业①。
输出信息:同作业①
weather.py
import scrapy
from ..items import WeatherJpgItem
from scrapy.selector import Selector
class WeatherSpider(scrapy.Spider):
name = 'weather'
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
selector=Selector(text=response.text)
srclist=selector.xpath("//img/@src").extract()
for src in srclist:
item=WeatherJpgItem()
item['src']=src
yield item
items.py
import scrapy
class WeatherJpgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
jpg = scrapy.Field()
pass
settings.py
BOT_NAME = 'weather_jpg'
SPIDER_MODULES = ['weather_jpg.spiders']
NEWSPIDER_MODULE = 'weather_jpg.spiders'
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
ITEM_PIPELINES = {
'weather_jpg.pipelines.imgpipelines':1,
}
IMAGES_STORE = 'D:/new file/images' #图片保存地址
pipilenes.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class imgpipelines(ImagesPipeline): #自定义一个管道类
def get_media_requests(self, item, info):
#根据图片地址进行图片数据的请求
yield scrapy.Request(item['src'])
#指定存储路径
def file_path(self, request, response=None, info=None):
imgname=request.url.split("/")[-1]
return imgname
def item_completed(self, results, item, info):
return item #返回给下一个即将被执行的管道类
运行结果部分截图:
心得体会
初步体验scrapy框架,对于图片爬取有点了解。
作业③
scrapy爬取股票
要求:使用scrapy框架爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:

stocks.py
import scrapy
import re
import json
from demo.items import StocksItem
import math
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = [
'http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409705185363781139_1602849464971&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602849464977']
def parse(self, response):
try:
data = response.body.decode()
datas = re.findall("{.*?}", data[re.search("\[", data).start():]) # 获取每支股票信息,一个{...}对应一支
for n in range(len(datas)):
stock = json.loads(datas[n]) # 文本解析成json格式
item = StocksItem() # 获取相应的变量
item['code'] = stock['f12']
item['name'] = stock['f14']
item['latest_price'] = str(stock['f2'])
item['range'] = str(stock['f3'])
item['amount'] = str(stock['f4'])
item['trading'] = str(stock['f5'])
yield item
all_page = math.ceil(eval(re.findall('"total":(\d+)', response.body.decode())[0]) / 20) # 获取页数
page = re.findall("pn=(\d+)", response.url)[0] # 当前页数
if int(page) < all_page: # 判断页数
url = response.url.replace("pn=" + page, "pn=" + str(int(page) + 1)) # 跳转下一页
yield scrapy.Request(url=url, callback=self.parse) # 函数回调
except Exception as err:
print(err)
itams.py
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code=scrapy.Field() #对象结构定义
name=scrapy.Field()
latest_price=scrapy.Field()
range=scrapy.Field()
amount=scrapy.Field()
trading=scrapy.Field()
pipielines.py
class StocksPipeline:
count = 0
fp = None
# 开启爬虫时执行,只执行一次
def open_spider(self, spider):
print("打开文件,开始写入数据")
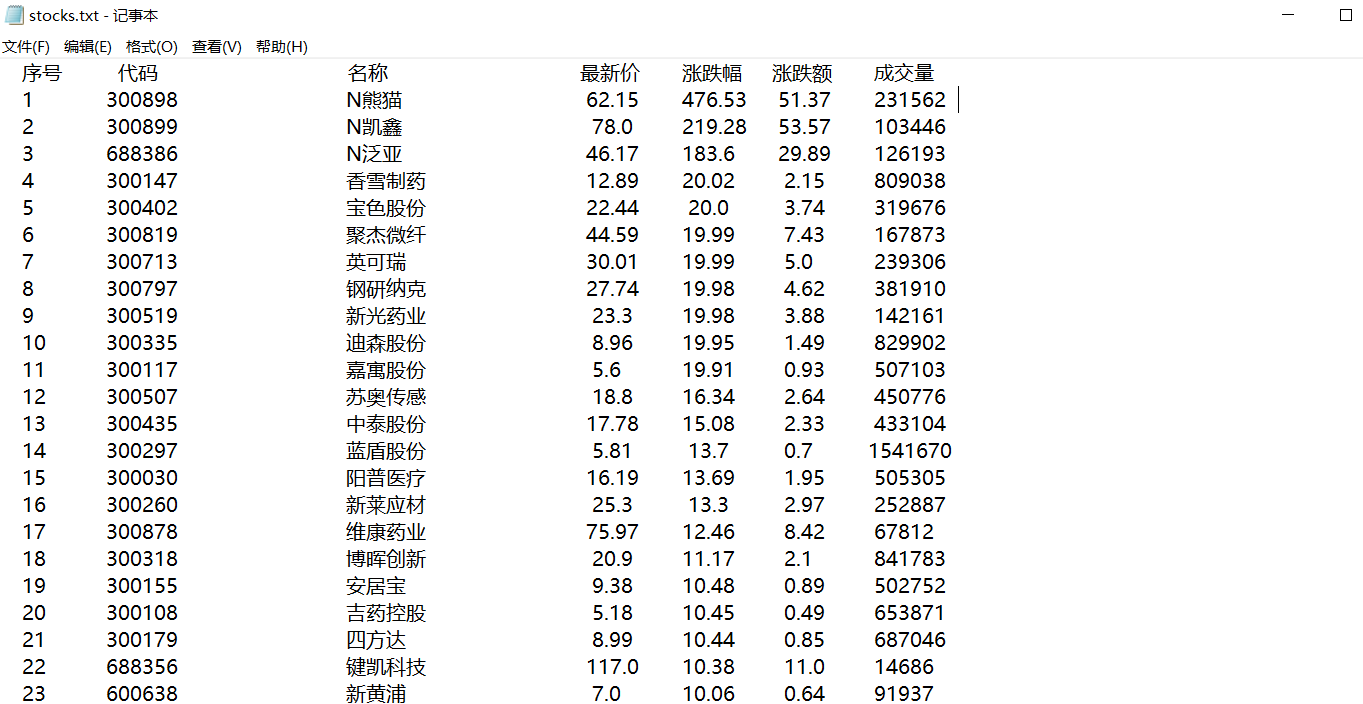
self.fp = open("D:/new file/stocks.txt", 'w')
self.fp.write(
" 序号 代码 名称 最新价 涨跌幅 涨跌额 成交量")
self.fp.write("\n")
# 保存数据
def process_item(self, item, spider):
StocksPipeline.count += 1
tplt = "{0:^10}\t{1:^10}\t{2:{7}^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^10}"
try:
self.fp.write(
tplt.format(StocksPipeline.count, item["code"], item["name"], item['latest_price'], item['range'],
item['amount'], item['trading'], chr(12288)))
self.fp.write("\n")
return item
except Exception as err:
print(err)
# 关闭爬虫时执行,只执行一次(如果爬虫中间发生异常导致崩溃,close_spider可能也不会执行)
def close_spider(self, spider):
print("写入结束,关闭文件")
self.fp.close()
return item
settings.py
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders']
NEWSPIDER_MODULE = 'demo.spiders'
ROBOTSTXT_OBEY =False
ITEM_PIPELINES = {
'demo.pipelines.StocksPipeline': 300,
}
运行结果部分截图:
心得体会
了解到到scrapy在爬取设定的url之前,它会先向服务器根目录请求一个txt文件,这个文件规定了爬取范围,scrapy会遵守这个范围协议,查看自己是否符合权限,如果爬取目标目录在目标网站的robots.txt文本中列为disallow,则scrapy会放弃爬取动作。通常被列为disallow的目录都是敏感目录,比如需要用户登录之后才能访问的目录等。这个有点君子协定的意思,但是有时候我们的好奇心驱使我们需要做小人,于是只能禁用这个配置,违反这个协定,更改方法:ROBOTSTXT_OBEY = False


 浙公网安备 33010602011771号
浙公网安备 33010602011771号