软工实践寒假作业(2/2)
| 作业所属课程 | 2021春/S班 |
|---|---|
| 作业要求 | 软工实践寒假作业(2/2) |
| 作业目标 | 阅读《构建之法》并提问,完成词频统计个人作业 |
| 其他参考文献 | 《构建之法》 |
Part:ONE
- 再次阅读《构建之法》后提出问题
问题一
我看了第3章3.1里的“c.质量如何?”部分和“d.是否按时交付?”部分,产生了这个问题:一个软件产品质量的好坏,软件工程师们的技术水平和软件交付期限都是很重要的因素。但如何在软件交付期限内充分发挥软件工程师的水平和价值?首先是对项目的用时估计,但估计就会有偏差,那么就有可能出现一个情况:项目的前90%都是按照A级标准在开发,可是这时突然遇到一个难点,整个团队的人都没法解决,拖延了一段时间,这时考虑到交付期限,只能按照B级标准降级开发,满足基本需求的基础上尽量降低开发质量,最后呈现的结果可能就好比是科尼塞克车身即将完成后发现卡钳生产遇到困难,最后用了次级质量的卡钳去代替,结果顾客反映车子速度可以很快但是制动效果不好,安全性不足,影响了用户的体验,最终导致口碑下降,销量下滑。受按时交付的影响,团队必须在限定时间内做好产品,那么产品开发前的估计就尤为重要,完全按照B级做可能就没法发挥团队水平,无法吸引更多客户与其合作,按A级做又可能存在预估时无法估计到的困难,这实际上是一场冒险,是一个如何平衡开发水平和开发时间的问题。
查了资料,大部分说法是追求交付时间内保守开发。有的项目可以先B级,然后有时间慢慢继续改进;但有的项目做不到,因为从底层开始设计就大相径庭,回溯修改极其困难。
根据我的作业经历,我是按照交付时间内保守开发的路子在做,因为作业的难度和体量与实际开发项目差距颇大,很多地方量变引起质变,不好直接类推,所以我对实际开发项目的此方面问题有些许疑问。
问题二
我看了第4章4.5.3“同时,结对编程避免了‘我的代码’还是‘他的代码’的问题,使得代码的责任不属于某个人,而是属于两个人,进而属于整个团队,这样能够帮助团队成员建立集体拥有代码的意识,在一定程度上避免了个人英雄主义。”部分,产生了这个问题:文中提到,结对编程会起到互相督促,互给压力的效果。但我想可能存在一种情况:某个人与团队内编程能力最好的那个人结对编程,那么这个人会不会因为和高手搭档,就形成依赖而不是激起自己的好强心态。自己编程的时候想着反正有大佬在复审,就没有那么投入,也没有那么苛求细节,如此一来,出Bug的数量和概率肯定会上升。而且大佬的操作甚至让这个人复审不知从何下手。查了资料,有如下说法:和实力相近的人结对编程可以解决这个问题。按照我的实践经验,此举确实可以避免上述问题出现。但我又想,这好比一个班级里作业得分最高的双人组和最低的双人组,一个团队中的人实力水平差距是必然存在的,如果说按照水平两两结对编程,避免了上述情况,但此时最强的那组和最弱的那组之间的差距就会被数倍扩大,那么同一个产品的两个模块之间可能就会存在极大的质量差距,显然不是我们想要的结果,那又如何解决这个问题呢?
问题三
我看了第5章5.3.6 MVP和MBP,产生了如下问题:条件允许的情况下,MBP显然看起来比MVP更加具有吸引力,也更能一举征服用户。从我个人观点来说:MVP模式大部分是受委托进行合作的商业开发模式,而MBP则更多是创业者追求的模式。他们最大的区别在于MBP往往需要更多的时间和更好的技术团队,以及对用户需求的更精确定位。那我是否可以理解为MBP模式是MVP模式的进化和升级?MVP模式是MBP模式的跳板还是说这只是两种不同的开发模式,之间并无太多的进化关系?假设是跳板,那么就是多次MVP累计经验进行MBP,但此时或许早就过了最佳的市场抢占时期,往往都是创造性的挑战MBP产品才能形成创新,在市场中鹤立鸡群。那么它们之间的到底是否存在进化与升级关系?查了资料,并未得到一些能对我的疑问有所帮助的回答。根据我的学习实践,我的经验是:同等时间内MBP模式或者MVP模式的选择取决于个人的编程开发水平,有的同学只能完成仅满足最低需求的编程作业,但编程能力强的学生可以将编程作业做到十分完整的地步。但这情况与实际商业开发有所不同,也就是目前的实践学习经验并不能解决我的疑惑。
问题四
我看了第9章9.3中“在一个项目中,PM的具体任务是:”这一部分内容。产生了这个问题:对于PM的选择,是用更偏向市场的PM还是用更偏向技术的PM会比较好?按照书中描述,PM的任务大概是作为开发人员和用户之间的桥梁,并带领开发团队完成任务。如若是偏向市场的PM,可能在获取客户需求方面会做得更好;若是偏向技术的PM,他会更好的将客户需求转换为开发团队的具体任务。当然可以说,找两者平衡的PM,但也许事实上,既有强大的市场敏锐度又有精锐的开发技术的PM毕竟还是少数。查阅资料:大部分说看具体的项目类型以及面向的用户群体而定。我感觉这种说法过于空泛,具体如何通过判断项目类型以及用户类型来选择PM我还有疑问。
问题五
我看了第16章16.1.5“为什么领域专家有时候没有领域外的创新者那么有创意?”这个问题,我想谈谈自己的看法:在不同的领域,需要不同的思维方式,这也是理科生要学习理化生三个科目而不是其中一个科目的原因,他培养的是各种思维的基础,先埋下种子,等自己将来需要哪一方面的东西再去继续浇水施肥。既然思维不同,那么不同领域对同一个问题的观察角度也会相差甚远。某一方面的专家,往往会深入内部研究而无法从外部看,因为他们太专业了,钻的太深了,有时就会缺乏广度,反而限制了自己的发散性思维。一个技术高超但不懂物理赛车手,他只知道如何打方向盘,如何完美的油离配合让赛车更快,但他不会知道车身后加尾翼增加下压力降低风阻也能提速,他只是在车里,车外的东西他看不到,或者说看到了也想不到,因为思维不同,关注点不同。对于赛车竞技而言,物理学家和赛车手都让车队的竞技水平提高了,到底谁才是让车子跑的更快的专家?我认为,永远不要认为谁是外行,往往是你所谓的“外行”给的你豁然开朗的思路和想法,同时也不要抵触主动学习其他行业的思维角度,毕竟任何行业领域都是多维度的立体,而不是一个平面。
附加题
- 会心一笑的典故:Lenna 图

对数字图像处理(绝大多数“神奇的”PS神技背后的技术)领域稍有了解的人,应该都对这幅大名鼎鼎的Lenna图有所见闻。Lenna图常被用作数字图像处理各种实验的例图,看过相关专业论文的同学可能对她又爱又恨。对于选择这张图作为例图的原因,(事后诸葛亮的)原因是:
1.该图适度的混合了细节、平滑区域、阴影和纹理,从而能很好的测试各种图像处理算法。
2.Lenna是个美女,对于图象处理界的研究者(大部分都是男性)来说,美女图可以有效的吸引他们来做研究。
而真实的故事是:
1973年6月,美国南加州大学的信号图像处理研究所的一个助理教授和他的一个研究生打算为了一个学术会议找一张数字照片,而他们对于手头现有成堆“无聊”照片感到厌烦。事实上他们需要的是一个人脸照片,同时又能让人眼前一亮。这时正好有人走进实验室,手上带着一本当时的《花花公子》杂志,结果故事发生了……而限于当时实验室设备和测试图片的需要,Lenna的图片只抠到了原图的肩膀部分
- 对此故事的认识:
当时图像技术发展还处于稚嫩的阶段,对图像的处理手段和水平还很局限。Lenna只有局部,这总是驱使人们做更多的猜测,然而猜测往往只是猜测,事实告诉我们,不能以偏概全,更不能肆意主观推测,想知道事实,必须自己去探究考证,而不是人云亦云,去相信一些没有依据的说法。
Part:TWO
- WordCount编程
1.Github地址
| Github地址 | Wuhan0623 |
|---|
 ;
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 865 | 970 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 45 |
| • Design Spec | • 生成设计文档 | 80 | 90 |
| • Design Review | • 设计复审 | 30 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| • Design | • 具体设计 | 45 | 50 |
| • Coding | • 具体编码 | 2000 | 2200 |
| • Code Review | • 代码复审 | 60 | 45 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 200 | 180 |
| Reporting | 报告 | 120 | 155 |
| • Test Repor | • 测试报告 | 30 | 45 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 80 |
| 合计 | 1015 | 1155 |
3.解题思路描述
Step1: 学习git、github
利用git和github进行版本管理以及修改,
规范代码开发过程。
Step2: 回顾Java,根据作业要求,确定主功能大致实现流程和所需的函数
初步确定四大功能需要的四个函数
以及文件读写的一个函数
其余所需函数后续根据具体情况再添加
Step3: 进一步学习HashMap和TreeSet以及与文件读写相关的知识
最后一个功能需要统计频率
我首先想到的是HashMap
其次并输出最高频的十个单词
我想到TreeSet的键值对自动排序
因为本次作业涉及对文件的输出和读取
自然要回顾文件读写相关知识
Step4: 按照需求分别实现每个功能
最后的结果有四种类型输出
又有作业要求功能独立实现
那么就逐个击破,从易到难
解决输出行数->字符数->单词数->词频统计
Step5: Debug、单元测试
完成功能后用测试用例
测试程序的正确性
并做性能改进
4.代码规范制定链接
| 代码规范链接 | codestyle.md |
|---|
5.设计与实现过程
- 类和函数

- 函数相关图
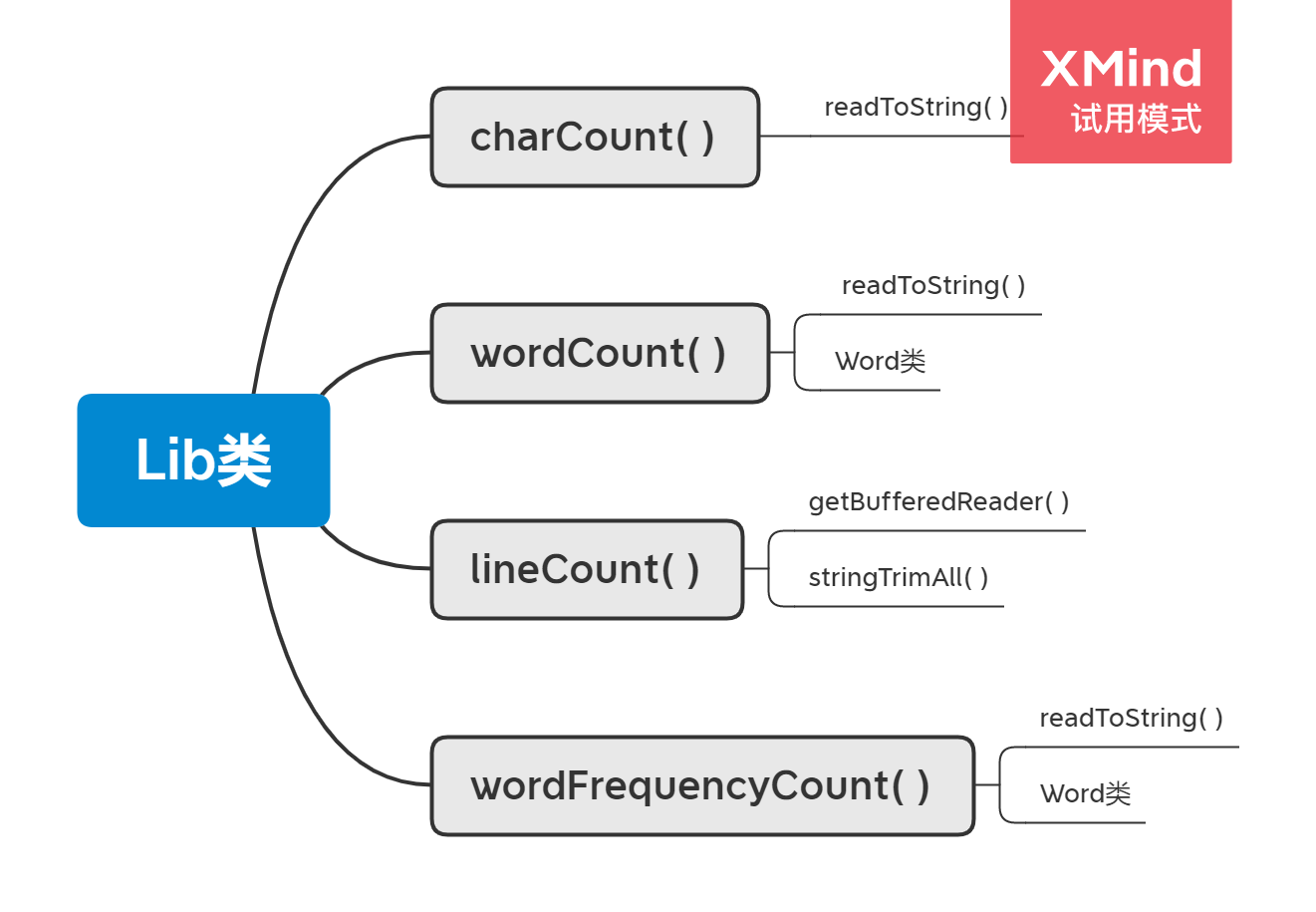
- 算法的关键(代码截取均被删改,只保留可读性)
字符统计功能
思路:在于将文本内容拼接以一个字符串的形式读入,即readToString()函数
public String readToString(String path)
{
String encoding = "UTF-8";
File file = new File(path);
long filelength = file.length();
byte[] filecontent = new byte[(int) filelength];
FileInputStream in = new FileInputStream(file);
in.read(filecontent);
in.close();
return new String(filecontent, encoding);
}
单词统计功能
思路:将读入的文本字符串中的控制符、空白符统一换成空格,再转字符串为小写,并以空格为分隔符分割单词,最后检验单词是否以四个字母开头
public void wordCount(String path)
{
this.resultStr = readToString(path);
this.resultStr = this.resultStr.replaceAll("[^A-Za-z0-9]", " ");
this.resultStr = this.resultStr.toLowerCase();
String[] words = this.resultStr.split(" "); // divide with spaces
this.sumWords = 0;
for (String word : words)
{
if (word.length() > 3)
{
int j;
for (j = 0; j < 4; j++)
{
char x = word.charAt(j);
if (x < 'a' || x > 'z') break;
}
if (j == 4) this.sumWords++;
}
}
}
行数统计功能
思路:获得BufferedReader,每行读取,将读取的字符串去除空白字符,若剩下长度大于0则符合要求,该被统计,关键的去除字符函数如下
public String stringTrimAll(String input)
{
if (null == input)
return "";
final String regx = "\\s*|\t|\r|\n"; //选择要去除的字符
Pattern patt = Pattern.compile(regx);
Matcher m = patt.matcher(input);
return m.replaceAll("");
}
词频统计功能
思路:前面部分逻辑同单词统计功能,即筛选出全部满足条件的单词后,利用HashMap和TreeSet对其进行按要求排序
public void wordFrequencyCount(String path)
{
/*同wordCount()函数,筛选出所有满足条件的单词,接着如下排序*/
Set<Word> set = new TreeSet<Word>();
for(String key : this.map.keySet())
{
set.add(new Word(key, this.map.get(key)));
}
int sum = 0;
Iterator<Word> t = set.iterator();
while (t.hasNext())
{
Word word = t.next();
this.sortResultStr += word.key + ": " + word.value + "\n";
sum++;
if(sum == 10) break;
}
}
6.性能改进
由于除了词频统计的其余部分我都是将数据得到后,存在类的属性值中,最终再生成输出的字符串,原本将最高词频的十个检索出来后也同样要储存再最终和其他数据一同输出,后续发现这样更占内存速度也不如直接生成字符串快,所以这部分我直接生成并返回字符串,前面那样做更快我认为大概是由于储存int需要的内存和速度优于储存同等数量的String字符串。
7.单元测试
- 自动测试函数
public static String getRandomString()
{
int[] num = new int[96];
char ch;
StringBuffer sb = new StringBuffer();
/*空白符*/
num[0] = 9;
num[1] = 10;
num[2] = 13;
num[3] = 32;
/*数字*/
for(int i = 0; i < 10 ; i++)
{
num[i+4] = i + '0';
}
/*小写字母*/
for(int i = 0; i < 26 ; i++)
{
num[i+14] = i + 'a';
}
/*大写字母*/
for(int i = 0; i < 26 ; i++)
{
num[i+40] = i + 'A';
}
/*额外增加空格的数量,控制单词长度*/
for(int i = 0; i < 30 ; i++)
{
num[i+66] = ' ';
}
int x;
for (int i = 0; i < 1000000; i++)
{
x = ThreadLocalRandom.current().nextInt(96);
sb.append((char) num[x]);
}
return sb.toString();
}
自动测试函数设计思路:将作业要求中所述的可能出现的字符的ASCII码依次装入一个一维数组,然后控制随机数范围为数组的下表取值范围内随机生成字符,最终将生成的字符串用于统计。其中最后加了30个空格是因为原本分隔符出现概率偏低,导致单词过长,增加分隔符出现的几率,单词长度更短。测试字符来到100万个,照概率而言,词频前十的基本应该是4或5个字母的单词,而且词频不会太高,几次测试都验证了我按照概率的大致推测。其中一次测试结果如下:
characters: 1000000
words: 30558
lines: 20125
rxdr: 3
uqcb: 3
yjss: 3
aarl: 2
adlx: 2
ajms: 2
awvu: 2
axmf: 2
ayto: 2
bdyi: 2
-
自动单元测试覆盖率
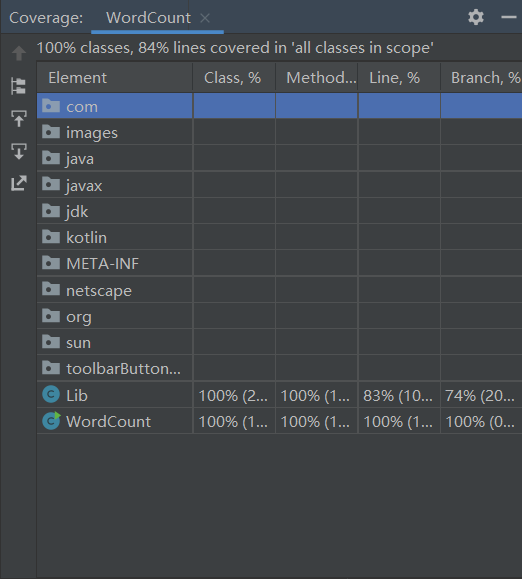
-
覆盖率优化
增大测试用例的数量,
并使测试用例尽量覆盖各种分支和可能,
以此来增加代码覆盖率。 -
白盒测试
input.txt
output.txt
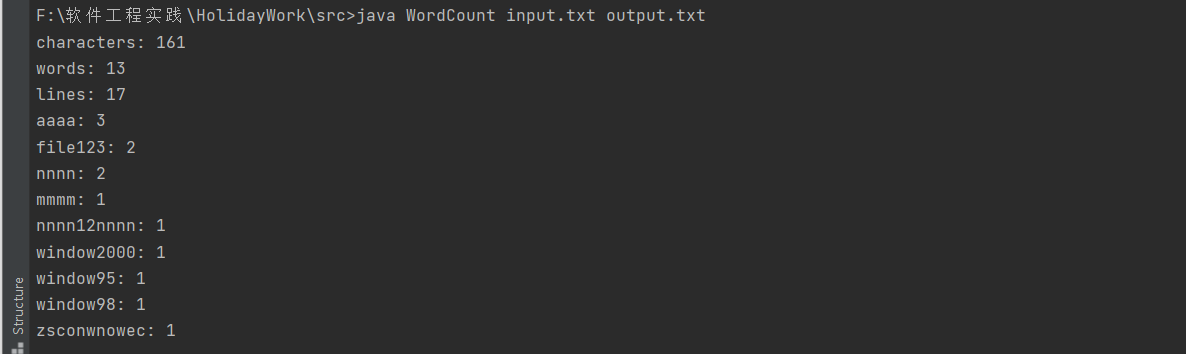
罗列了各种情况的输出,统计结果与手算一致。
下列是一篇英语作文。
input.txt
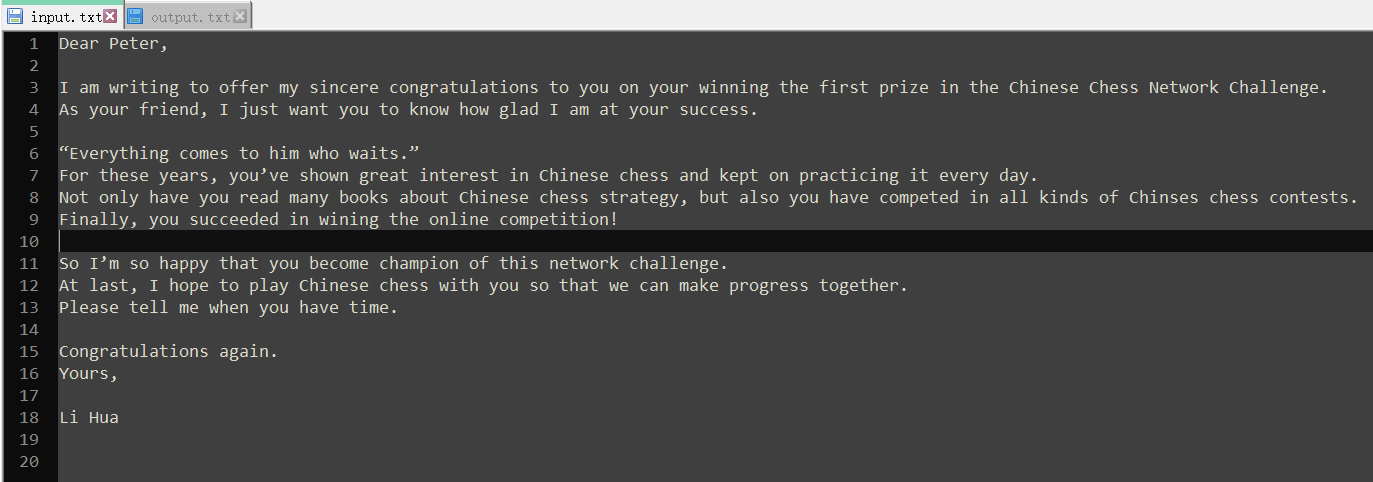
output.txt

8.异常处理说明
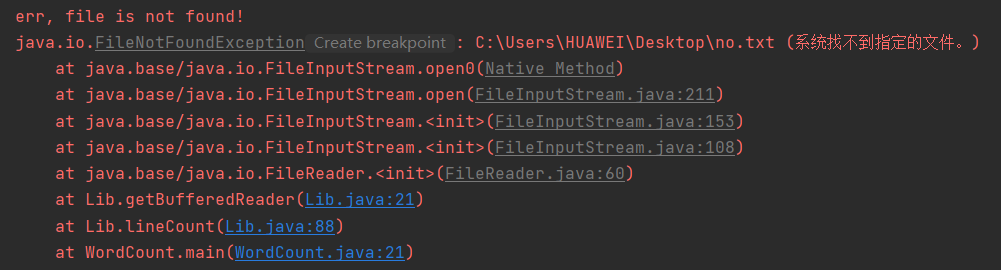
- FileNotFoundException异常,不存在该或找不到文件。
任意给一个不存在或者错误的路径
如测试样例:"C:\Users\HUAWEI\Desktop\no.txt";
得到如下结果:
- ArrayIndexOutOfBoundsException异常,数组越界
命令行输入时不输入或只输入一个文件名
如测试样例:java WordCount input.txt
得到如下结果:

9.心路历程与收获
-
观察阶段
刚开始看到作业要求的时候,头昏眼花,作业要求一大堆,找不到切入点,心情很是烦闷,但我深知这些都是必经之路,积极想办法调节才是正道,于是听了几遍大悲咒,调整心态,开始看作业要求。看了任务一跟上次差不多,增加了一些要求。接着我想着直接去找编程部分的作业先看看如何.看了编程部分,我觉得需求看起来难度不算特别大,至少我能立刻有模糊的大致思路,心里算是有点底了。 -
开始入手
在认真阅读了作业各项要求后,觉得git和github方面很陌生,之前只是使用过github去查看或者下载内容,并未自己使用它来记录代码和编程过程,初步理解并学习用git和github管理花了好一段时间。期间按照老师作业要求里的建议,边学git边看《构建之法》。 -
着手编程
完成了任务一以及git和github的初学习,我开始着手编程,阅读了WordCount具体需求,我觉得统计行数和统计字符数肯定很容易,统计单词和词频可能比较麻烦一点。但事实证明还是不能大意,统计行数部分和字符统计部分都碰到了一点磕绊。行数部分是由于空白字符的问题,字符统计是由于我之前不知道window系统换行是“\r\n”,所以我看faq里的这一项看不懂。遇到磕绊提高警惕后,统计单词和词频统计方面倒是比较顺利,统计单词没遇到问题,词频统计方面遇到问题后查询了相关资料后综合分析也顺利解决了。 -
分析总结
做完了相关要求的事项后,回首想想,虽然整个任务的要求繁多,看起来眼花缭乱,但主要是得静下心来,一点一点阅读,找出自己会的部分先完成,然后遇到困难再一步步想办法查资料、询问别人相关知识等途径来解决问题。做软件本身就不可能在一开始就想到所有的细节,那样只会形成邹老师所说的“过度分析”,要想想做做,一部分一部分解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号