
需求背景:一名未知名的大神想要在上班时间看看小说摸摸鱼等,大神给我的消息就是下图:让我实现类似爬虫的功能,现在实现后总结一下。
——
原文链接打开后有大量的广告以及不需要的信息:https://www.xxbiqudu.com/79_79638/152239434.html。
分析链接:https://m.xxbiqudu.com就是应该网站的域名,79_79638应该就是书籍的编号 152232829 应该就是当前书籍的页码,大神应该是读到这一页了。
首先在psotman上进行测试:
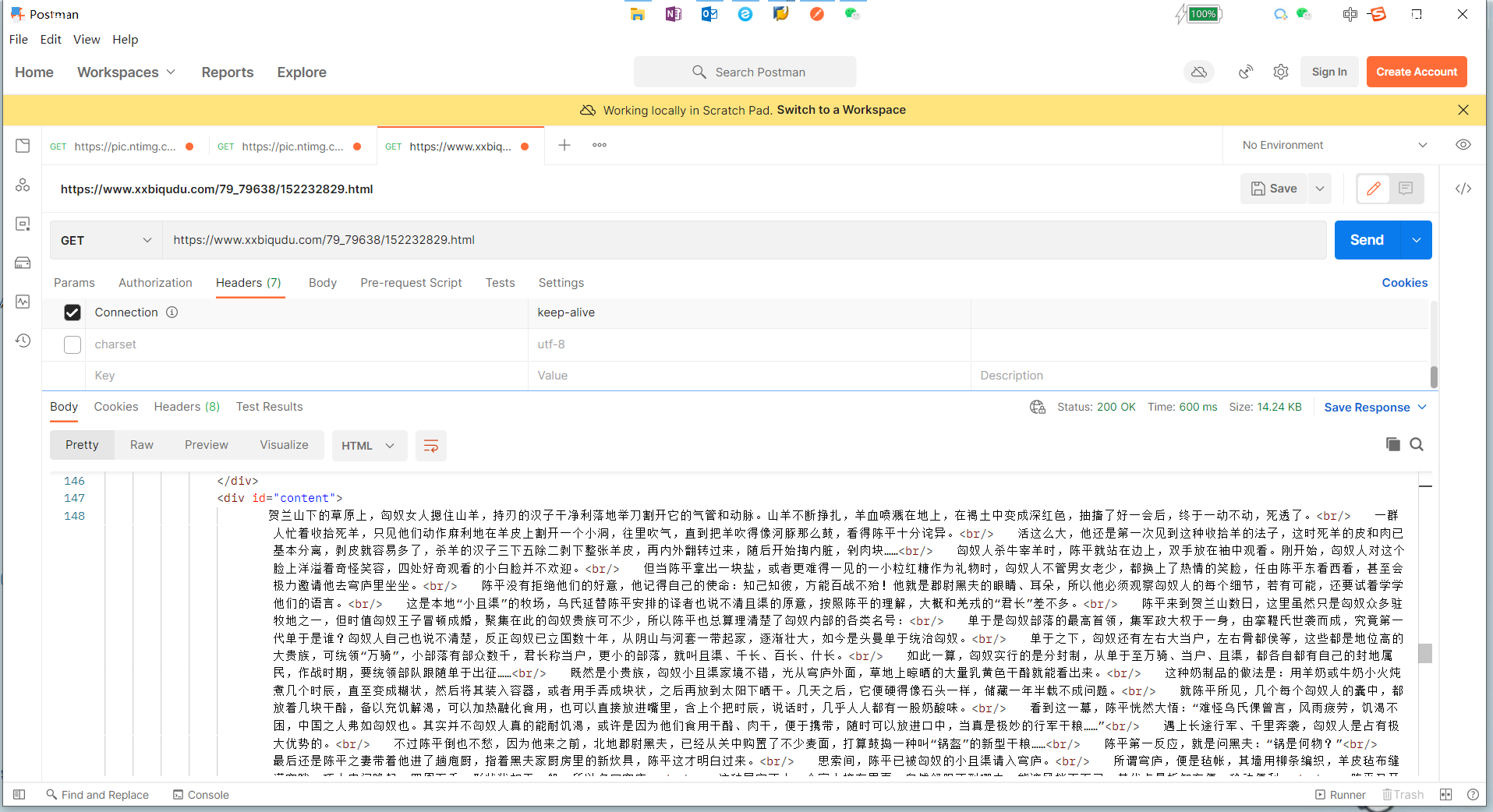
下面就需求分析完毕后开始思考:在postman上打开连接看到 这个<div id = “content”>xxxx.........</div>里面应该就是咱们想要的核心内容了。
如果用Python来写,可能几行代码就解决了。
爬虫本质就是读取url,然后解析url => 进行清理=> 回传显示,,接下来思考了一下 ABAP中,cl_http_client / request / response应该就可以实现该需求。
然后就开始操刀,事务码SICF :新建服务路径和处理器:
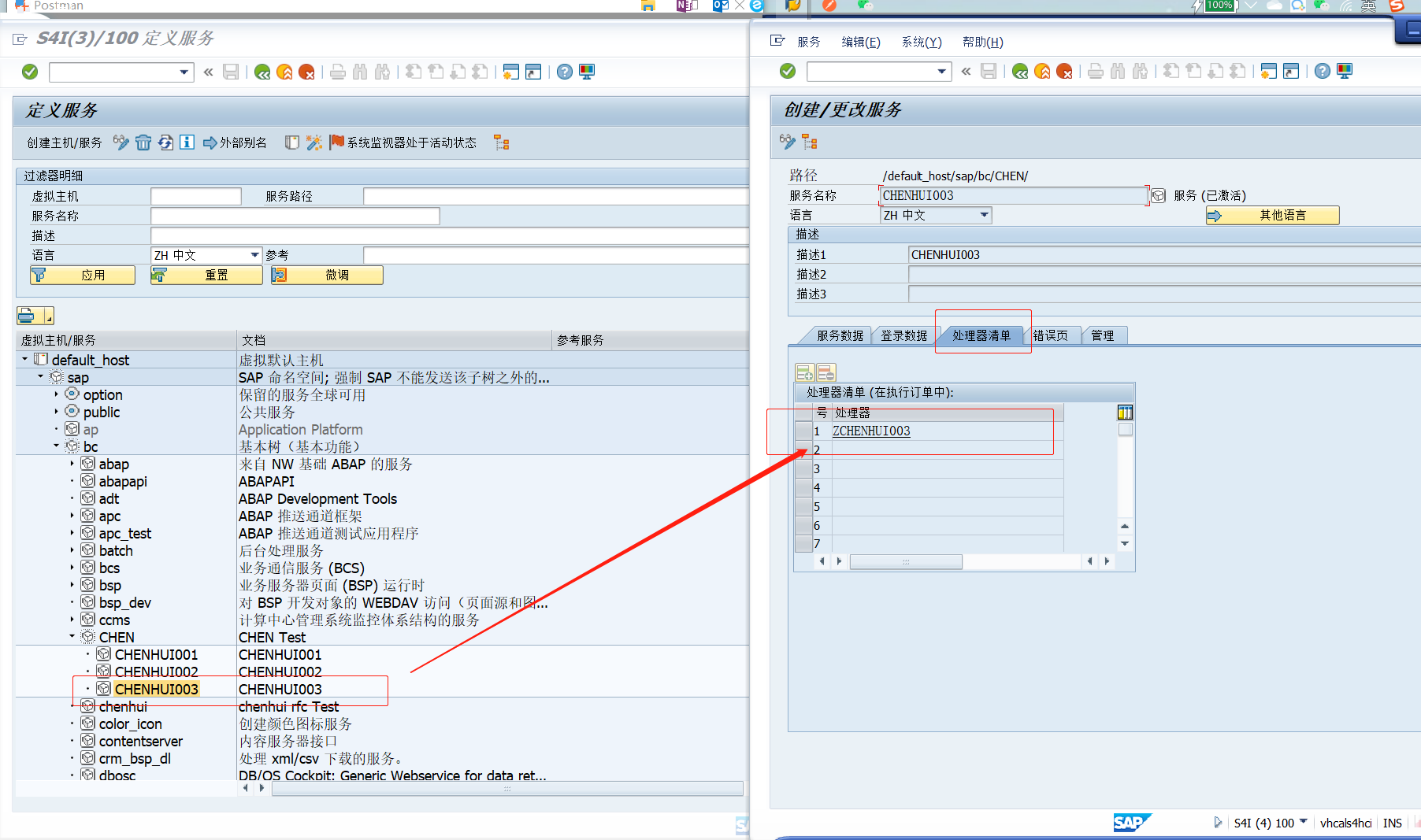
接下来:转到事务码:SE24,写处理器的逻辑,继承IF_HTTP_EXTENSION接口,重定义 方法:IF_HTTP_EXTENSION~HANDLE_REQUEST
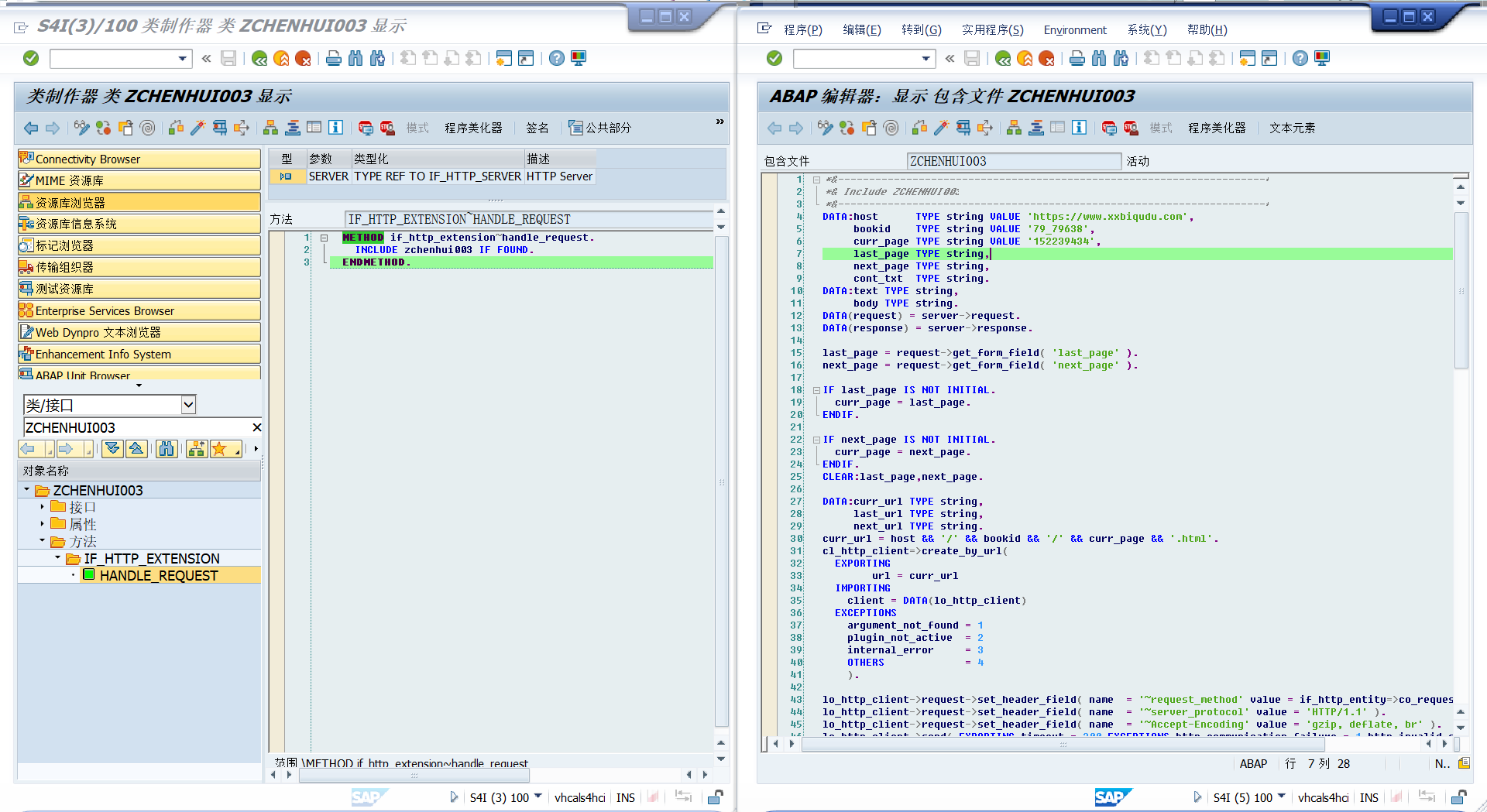
按照一般思路先测试连通性,发现:
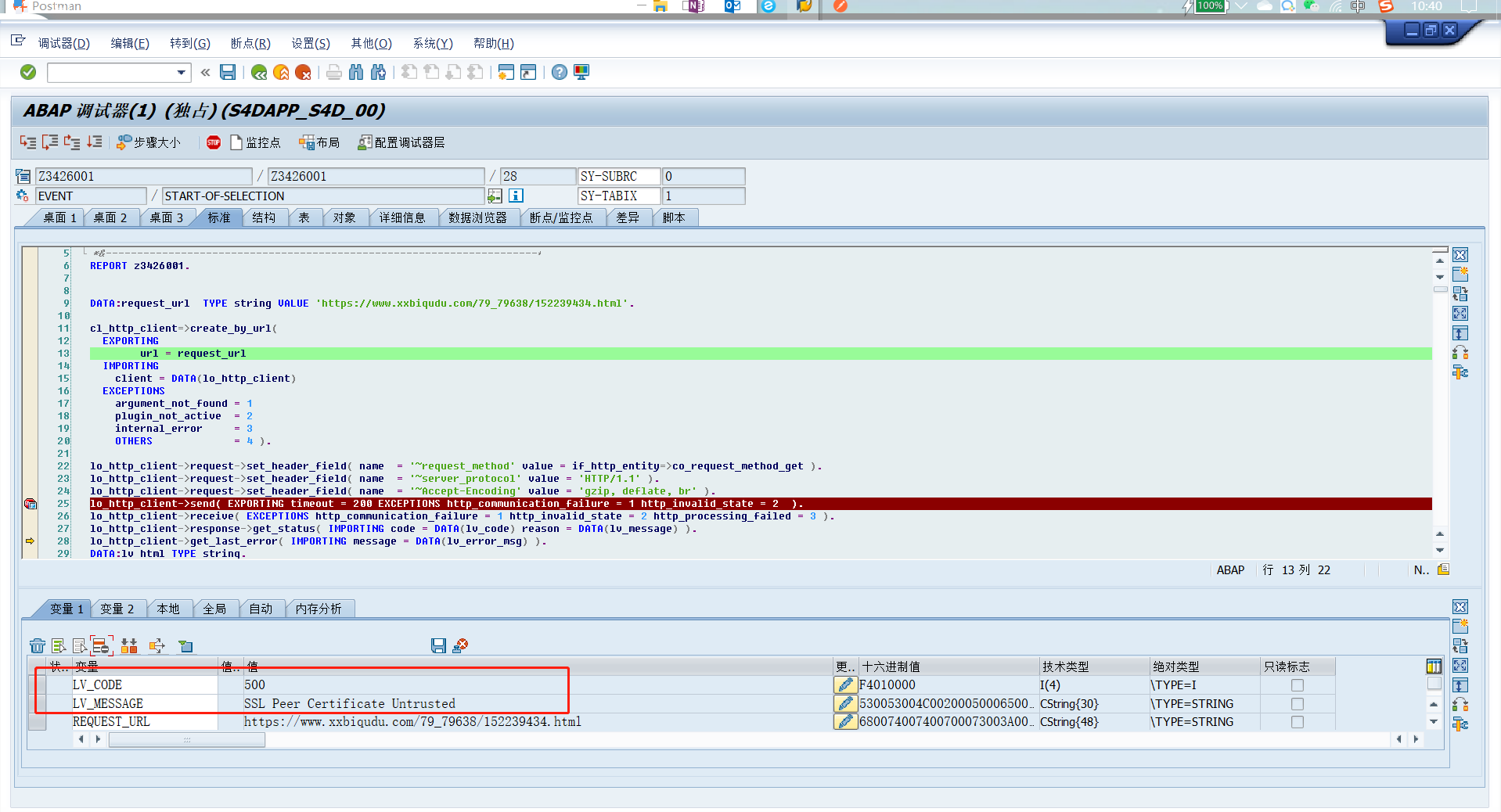
居然报证书问题:SSL Peer Certificate Untrusted
那就安装证书吧,百度一下如何在SAP安装证书: https://blog.csdn.net/u014535256/article/details/111147691
等证书安装完毕,再进行配合postman解析
发现可以读取到大致内容了:
居然乱码了,GBK???
好吧GBK转UTF-8,尝试了好几种办法,
只有:DATA(lv_xstr) = lo_http_client->response->get_data( ). 先读取成二进制,然后再使用二进制转utf-8才可以,
而使用DATA(lv_str) = lo_http_client->response->get_cdata( ).读取到的字符是乱码的,自己可尝试。
接下啦读取到报文后,就可以进行解析了元素了。
现在当前元素可以解析到,但也不能仅仅读取一页吧,那还需要进行翻页,上一页和下一页呢。
首先解析上一页和下一页的页码:
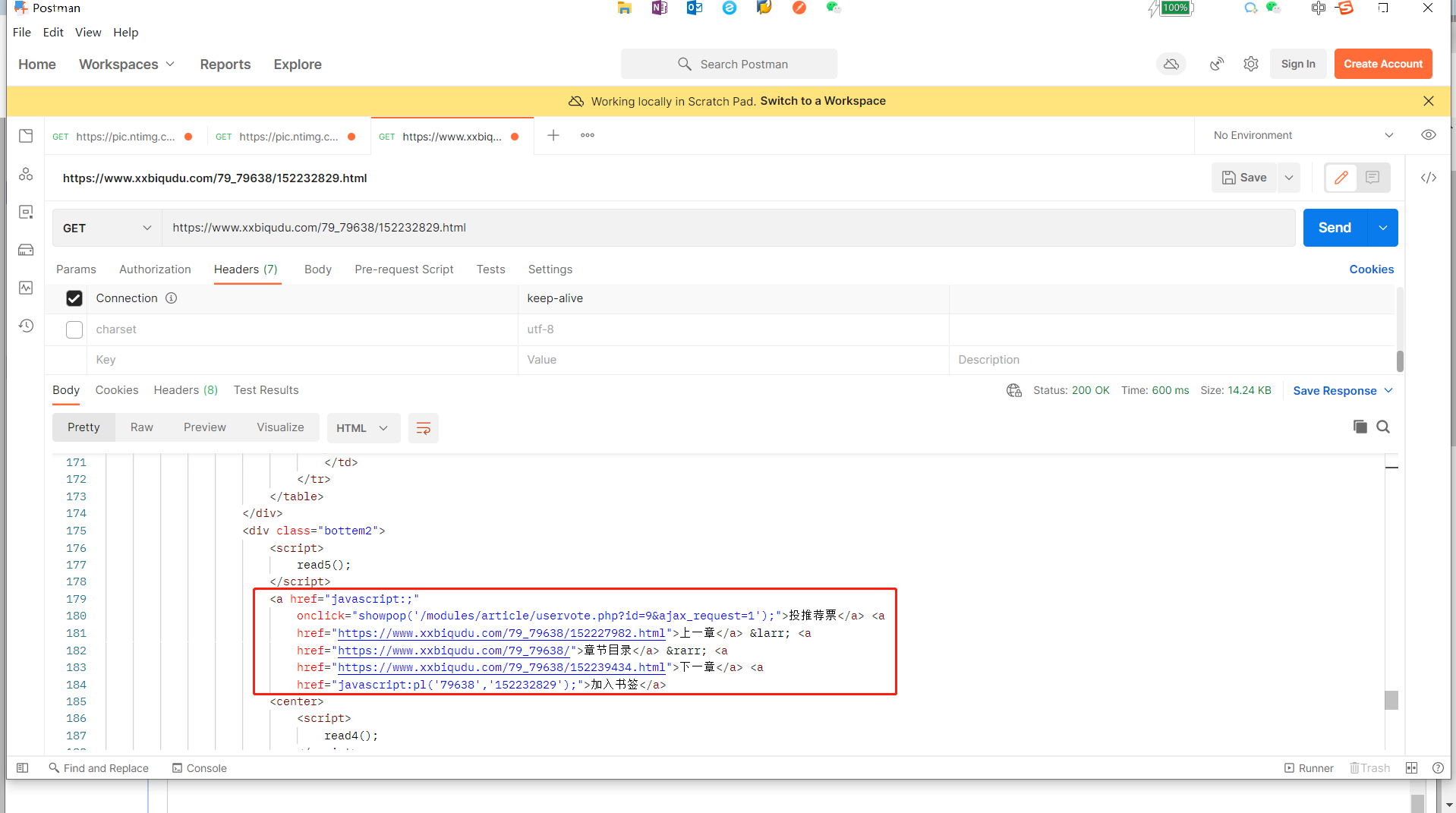
ABAP代码里通过字符长度的截取就可以获取完整的url,具体的截取方法可以参考本Bolog中的附件代码。
最后再加一个阅读进度,将当前阅读的页码存到表里,下次再打开时,就可以从当前页打开了(至于需不需要区分用户名,会员,等等记录状态,等别人没送Lv Shi Han再说吧)
对于新手来讲,不妨自己练手试一试,暂时不参考该源码呢。
最后上代码:https://files.cnblogs.com/files/1187163927ch/ZCHENHUI003.zip
解压密码:1187163927
需要详细代码和技术交流的可以加QQ:1187163827
本文来自博客园,作者:Lovemywx2,转载请注明原文链接:https://www.cnblogs.com/1187163927ch/p/15735499.html
