
2023数据采集与融合技术实践作业1
2023数据采集与融合技术实践作业1
作业①
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
实验代码:
import urllib.request
from bs4 import BeautifulSoup
import requests
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
st = "<h3>中国大学排名</h3>"
st = st + "<table border='1' width='600'>"
st = st + "<tr>" + "<td>" + "排名" + "</td>" + "<td>" + "学校名称" + "</td>" + "<td>" + "省市" + "</td>" + "<td>" + "类型" + "</td>" + "<td>" + "总分" + "</td>" + "</tr>"
N = int(input("输入要查询前TOP几个大学:"))
try:
req = requests.get(url)
request = urllib.request.Request(url)
html = urllib.request.urlopen(request)
req = html.read().decode("utf-8")
soup = BeautifulSoup(req,'html.parser')
vital = soup.find_all('td',class_="")
name = soup.find_all('a',class_="name-cn")
url = soup.find()
except Exception as err:
print(err)
for i in range(N):
n = 5*i
st = st + "<tr>"
st = st + "<td>" + vital[n].text.strip() + "</td>"
st = st + "<td>" + name[i].text + "</td>"
st = st + "<td>" + vital[n+1].text.strip() + "</td>"
st = st + "<td>" + vital[n+2].text.strip() + "</td>"
st = st + "<td>" + vital[n+3].text.strip() + "</td>"
st = st + "</tr>"
st = st + "</table>"
with open("universityRank.html","w",encoding="utf-8") as f:
f.write(st)
f.close()
结果:

心得体会
相对简单
作业②
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码:
import urllib.request
import requests
import urllib
from bs4 import BeautifulSoup
import math
import threading
import time
import multiprocessing
import re
req = re.compile(r'<img src=\'(.*?)\'')
cookies = {'dest_area : country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0,__permanent_id : 20230917180510800122040734002274359 ,__visit_id : 20230917180510815112835205082235586, ddscreen : 2,__trace_id : 20230917180510815166309272151488070'}
baseurl = 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input/'
head = {"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; Media Center PC 6.0; InfoPath.3; MS-RTC LM 8; Zune 4.7)"
"Cookies" : 'dest_area : country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0,__permanent_id : 20230917180510800122040734002274359 ,__visit_id : 20230917180510815112835205082235586, ddscreen : 2,__trace_id : 20230917180510815166309272151488070'}
def get(url, n):
try:
html = requests.get(url,headers=head)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
html = html.text
soup = BeautifulSoup(html, "html.parser")
name = soup.find_all('a',class_='pic')
price = soup.find_all('span',class_='price_n')
# 把数据以列表的形式保存
list = []
for i in range(0,n):
list.append([name[i].attrs['title'],price[i].text])
# 把数据写入文件
with open('Dangdang1.xlxs', 'a', encoding='utf-8') as f:
for i in range(0,n):
f.write( str(list[i][1])+'\t'+str(list[i][0])+'\n')
print('写入成功!')
def generator(url):
try:
html = requests.get(url,headers=head)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html.text
def consume_photo(html,pohto = None):
imgs = re.findall(r'<img src=\'(.*?)\'',html)
photo = []
for img in imgs:
try:
html = requests.get('http:' + img , headers=head)
photo.append(html.content)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return photo
def save(photos,n):
for photo in photos:
with open('D:\PythonPJ\Data\Text4\\reptile\img\\' + str(n) + '.jpg', 'wb') as f:
f.write(photo)
f.close()
n +=1
def thred(num):
threds = []
page = math.ceil(int(num) / 60)
for i in range(1,int(page+1)):
url = baseurl + '&page_index=' + str(i)
if (i != page):
threds.append(threading.Thread(target=get,args=(url,60)))
'''threds = threds.append(threading.Sudoku(get,(url,i)))'''
else:
n = int(num) % 60
get(url, n)
for thred in threds:
thred.start()
for thred in threds:
thred.join()
def mutl(num):
mutls = []
page = math.ceil(int(num) / 60)
for i in range(1,int(page+1)):
url = baseurl + '&page_index=' + str(i)
if (i != page):
mutls.append(multiprocessing.Process(target=get,args=(url,60)))
'''threds = threds.append(threading.Sudoku(get,(url,i)))'''
else:
n = int(num) % 60
get(url, n)
for thred in mutls:
thred.start()
for thred in mutls:
thred.join()
def main():
num = input('请输入要搜索的数量:')
pages = math.ceil(int(num)/60)
for page in range(1,pages+1):
url = baseurl + '&page_index=' + str(page)
html = generator(url)
photos = consume_photo(html)
save(photos,(page-1)*50)
print('保存完毕')
# 运行
if __name__ == '__main__':
main()
运行截图
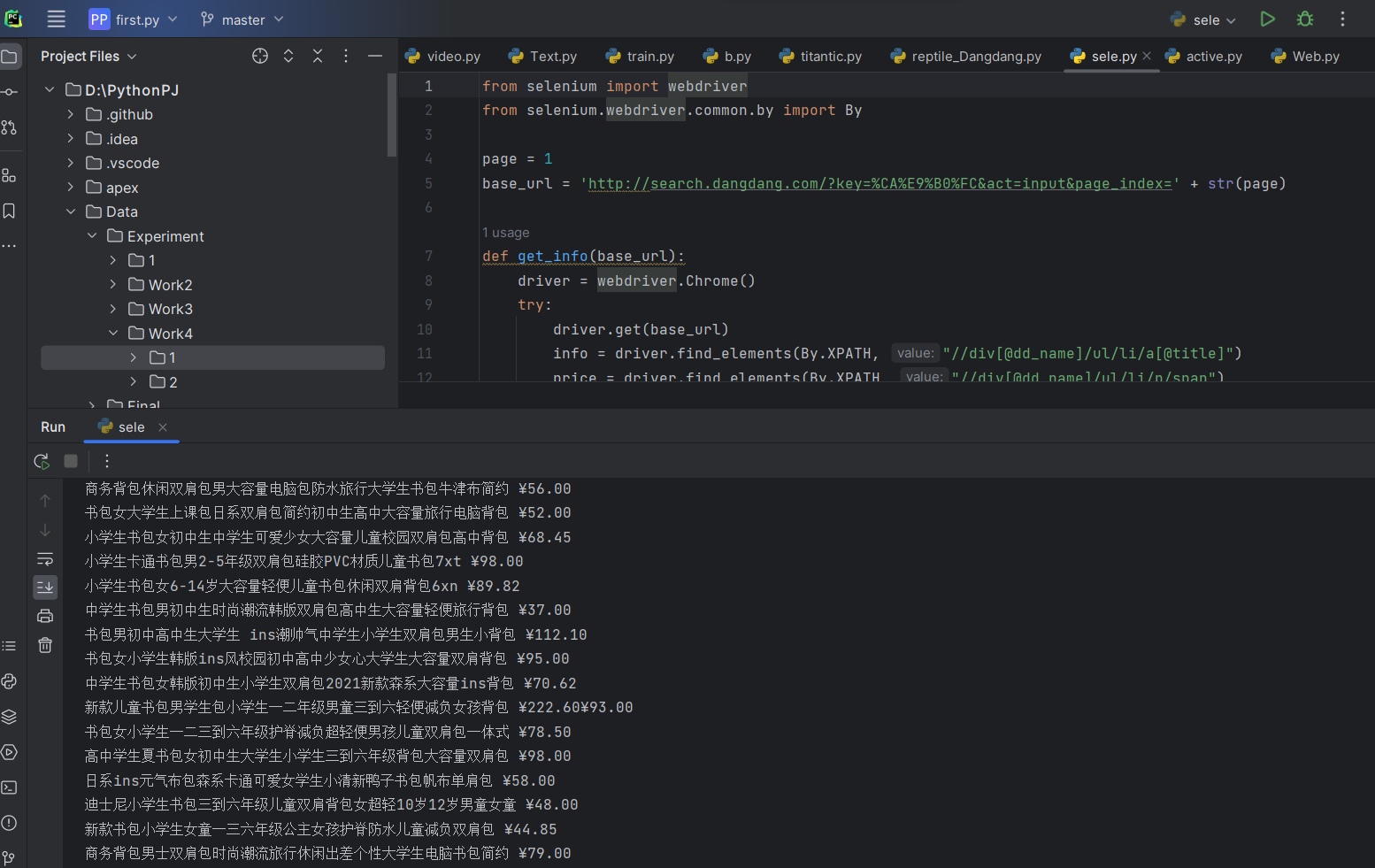
心得体会:
当时的代码以及找不到了,就有个修改版本的,实验要求是request访问,当当网没做什么反爬机制,也是相对简单,然后是对于html的提取,直接利用re或者BeautifulSoup也是相对简单
作业③:
- 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
- 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
实验代码
import requests
from bs4 import BeautifulSoup
import urllib
url = 'https://xcb.fzu.edu.cn/info/1071/4481.htm'
html = requests.get(url)
soup = BeautifulSoup(html.text,"html.parser")
src = soup.find_all('img')
for i in range(0,len(src)):
src[i] = src[i].attrs['src']
print(src[i])
src[i] = 'https://xcb.fzu.edu.cn' + src[i]
# 保存图片,放在当前目录的img文件夹下
for i in range(0,len(src)):
try:
html = requests.get(src[i])
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
# 保存图片
with open('D:/img//' + str(i) + '.jpg', 'wb') as f:
f.write(html.content)
f.close()
print('第%d张图片下载完成' % (i+1))
心得体会
相对简单,就是简单的对于BeautifulSoup以及request的应用


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)