第二次作业
软件工程第二次作业
1.代码仓库
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | *计划 | 40 | 30 |
| Estimate | ·估计这个任务需要多少时间 | 1500 | 1500 |
| Development | 开发 | 420 | 400 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 150 |
| Design Spec | 生成设计文档 | 60 | 70 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 100 | 100 |
| Coding | 具体编码 | 240 | 240 |
| Code Review | 代码复审 | 60 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 120 | 120 |
| Test Repor | 测试报告 | 40 | 40 |
| Size Measurement | 计算工作量 | 60 | 50 |
| Postmortem & Process Improvement Plan | 测试报告 | 40 | 40 |
| Test Repor | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 1500 | 1430 |
3.计算模块接口的设计与实现过程
-
需求
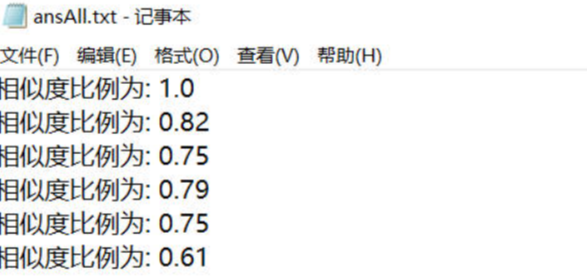
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
-
实现原理
通过SimHash算法并结合实际的代码来实现,通过对不同文本的SimHash值进而比较“海明距离”,从而判断两个文本的相似度。
-
开发环境及依赖
编程语言:java
编程工具:IDEA
项目构建工具:maven
性能分析工具:JProfiler 9.2
单元测试:JUnit 4.12
HTML解析:Jsoup 1.11.3
分词处理:hanlp 1.8.1
4.实现思路
程序使用KMP算法在第一个文本中寻找第二个文本的子串,KMP算法通过构建部分匹配表(Partial Match Table)来避免不必要的回溯,提高字符串匹配的效率,然后程序使用动态规划算法计算两个文本之间的编辑距离。动态规划算法通过填充一个二维数组来记录状态值,其中dp[i][j]表示将第一个文本的前i个字符转换为第二个文本的前j个字符所需的最少操作次数。
具体计算步骤如下:
- 初始化数组的第一行和第一列,表示将一个空字符串转换为另一个字符串所需的操作次数。
- 从第二行和第二列开始,遍历数组的每个元素。
- 如果第一个文本的第i个字符等于第二个文本的第j个字符,则dp[i][j]等于dp[i-1][j-1],表示不需要进行任何操作。
- 如果第一个文本的第i个字符不等于第二个文本的第j个字符,则dp[i][j]等于左边、上边和左上角三个元素中的最小值加1,表示需要进行插入、删除或替换操作。
- 最后,dp[len1][len2]即为两个文本之间的编辑距离,其中len1和len2分别表示两个文本的长度。
5.模块设计

6.性能分析
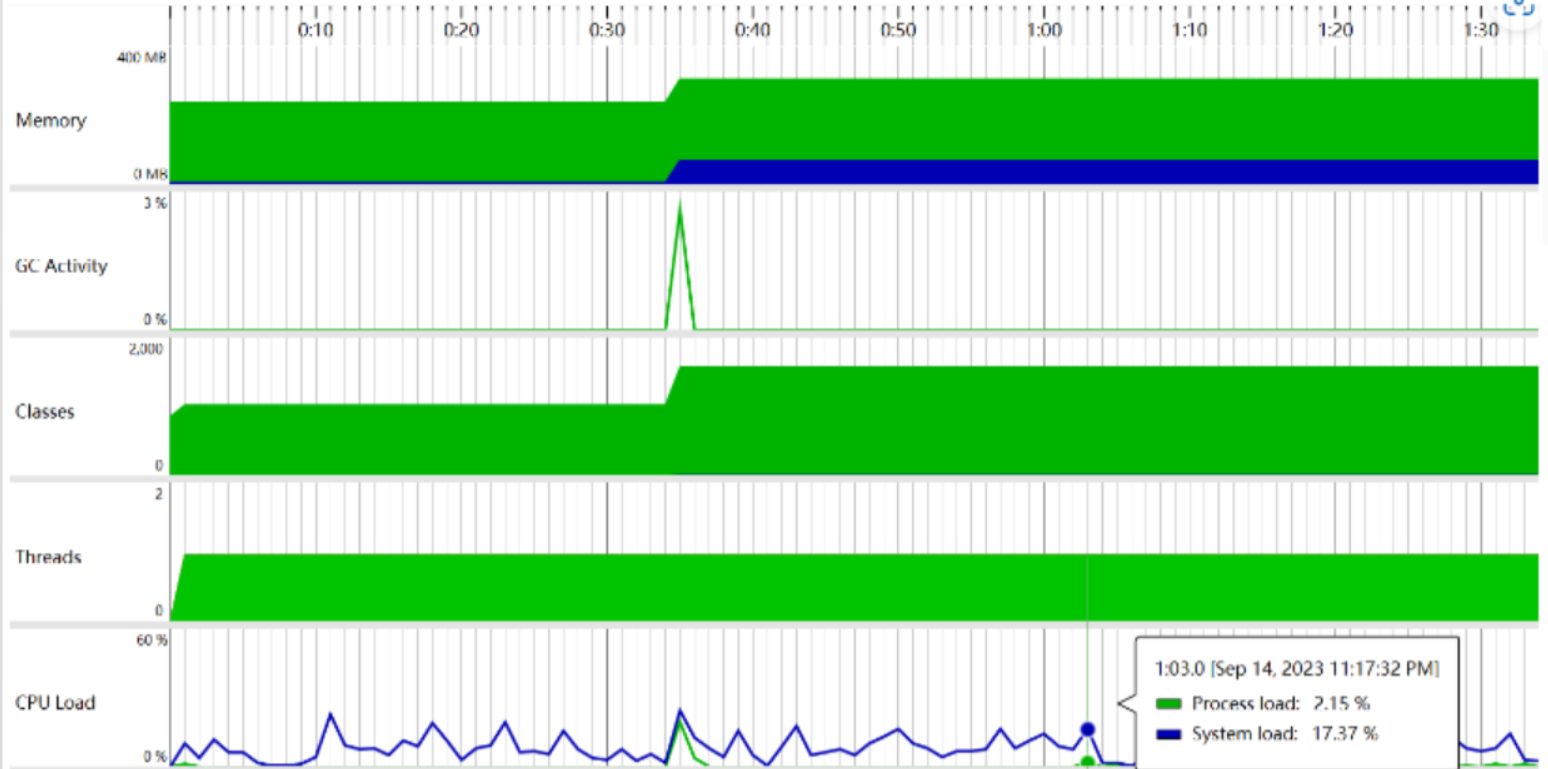
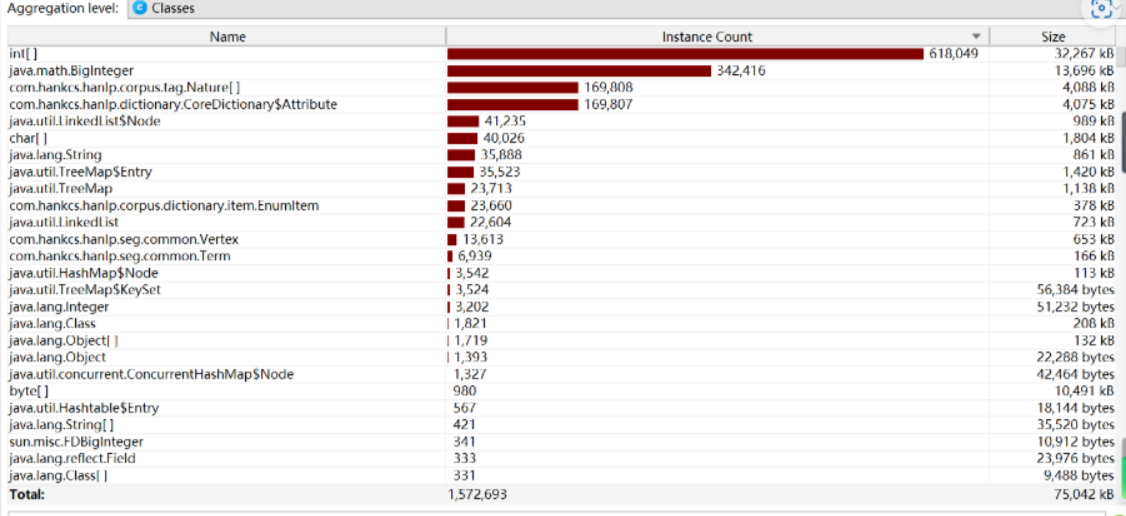
调用次数最多的是com.hankcs.hanlp包提供的接口, 即分词、取关键词与计算词频花费了最多的时间。
7.测试部分