R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成
“Gary1.csv”、“Gary2.csv”、“Gary3.csv”中保存了一个班级学生三个学期的成绩
对三个学期中的成绩数据进行集成并重新计算综合成绩和排名,并按排名顺序排布(学号9位数111304001~11304047)
Gary1.csv中数据

Gary2.csv中数据
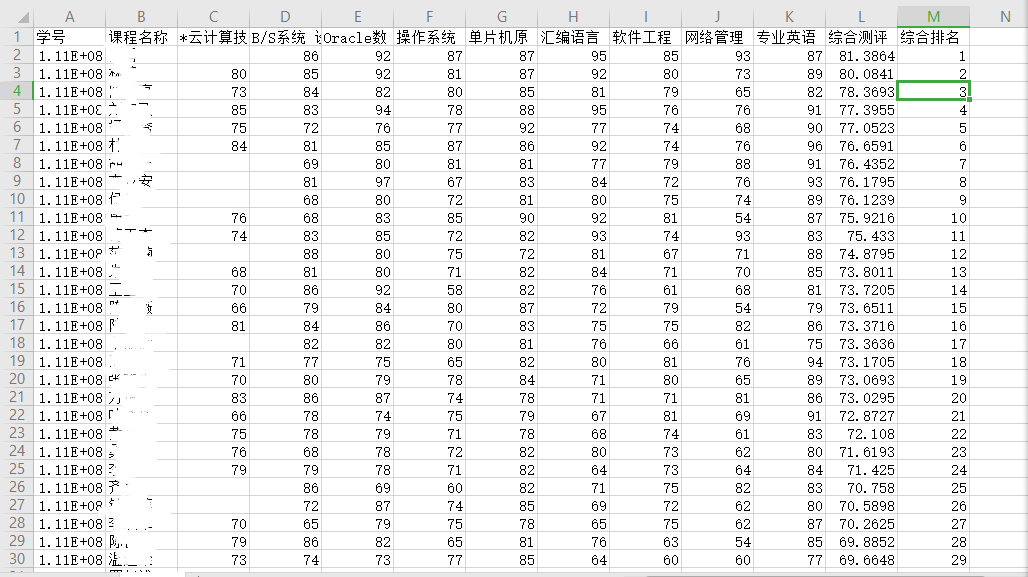
Gary3.csv中数据
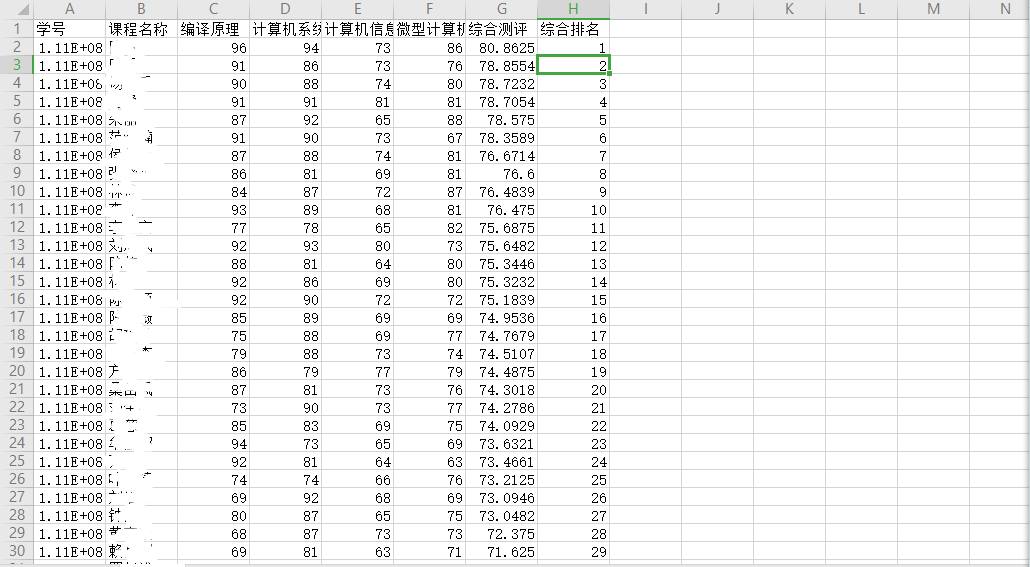
cbind是根据列进行合并 (要求:所有数据行数相等)
rbind是根据行进行合并 (要求:所有数据列数相同)



#打开工作目录文件 setwd('D:\\data') list.files() inputfile1=read.csv(file="Gary1.csv",header=TRUE) inputfile2=read.csv(file="Gary2.csv",header=TRUE) inputfile3=read.csv(file="Gary3.csv",header=TRUE) #删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名 result=cbind(inputfile1[,-c(10,11)],inputfile2[,-c(1,2,12,13)]) #数据集列合并 #同理 result2=cbind(result,inputfile3[,-c(1,2,7,8)]) #对学生成绩进行相加,得到一组数据(我自己测试学生成绩是从第三列到第二十二列的) #相加成绩保存到evaluation中 evaluation=apply(result2[,3:22], 1,mean,na.rm=TRUE) #apply函数一般有三个参数 #第一个参数代表矩阵对象 #第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理 #第三个参数就是处理数据的函数 #apply会分别一行或一列处理该矩阵的数据。 #将evaluation用“综合测评”添加到resule2中,将结果用result11保存 result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名 result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
实现过程
apply函数三个参数:
第一个参数代表矩阵对象
第二个参数代表要操作矩阵的维度 1表示对行进行处理,2表示对列进行处理
第三个参数就是处理数据的函数
读取文件数据保存到inputfile中
inputfile1=read.csv(file="Gary1.csv",header=TRUE) inputfile2=read.csv(file="Gary2.csv",header=TRUE) inputfile3=read.csv(file="Gary3.csv",header=TRUE)
删除inputfile1中的综合成绩和排名,删除inputfile2,inputfuke3中的学号、姓名、综合成绩和排名(合并数据后这些数据多余了)
result=cbind(inputfile1[,-c(10,11)],inputfile2[,-c(1,2,12,13)]) #数据集列合并 result2=cbind(result,inputfile3[,-c(1,2,7,8)])
计算学生成绩并将所得结果添加到学生表中
evaluation=apply(result2[,3:22], 1,mean,na.rm=TRUE) #将evaluation用“综合测评”添加到resule2中,将结果用result11保存 result11=data.frame(result2,'综合测评'=evaluation) #对result11中按综合测评成绩进行decreasing减少量排名 result22=result11[order(result11$综合测评,decreasing = TRUE), ] result33=data.frame(result22,'测评排名'=order(result22$综合测评,decreasing = TRUE)) result33
当R数据中存在NA时,使用对数据的mean()函数时需要注意NA问题
y<-mean(x)
因为x中有NA,所以当对x进行mean操作时,y会被赋值为NA
对学生成绩异常值检测 传送门
修改上列代码28行
evaluation=apply(result2[,3:22], 1,mean)

补充:merge()函数 传送门
merge 连接两个数据,官方参考文档语法
merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), incomparables = NULL, ...)
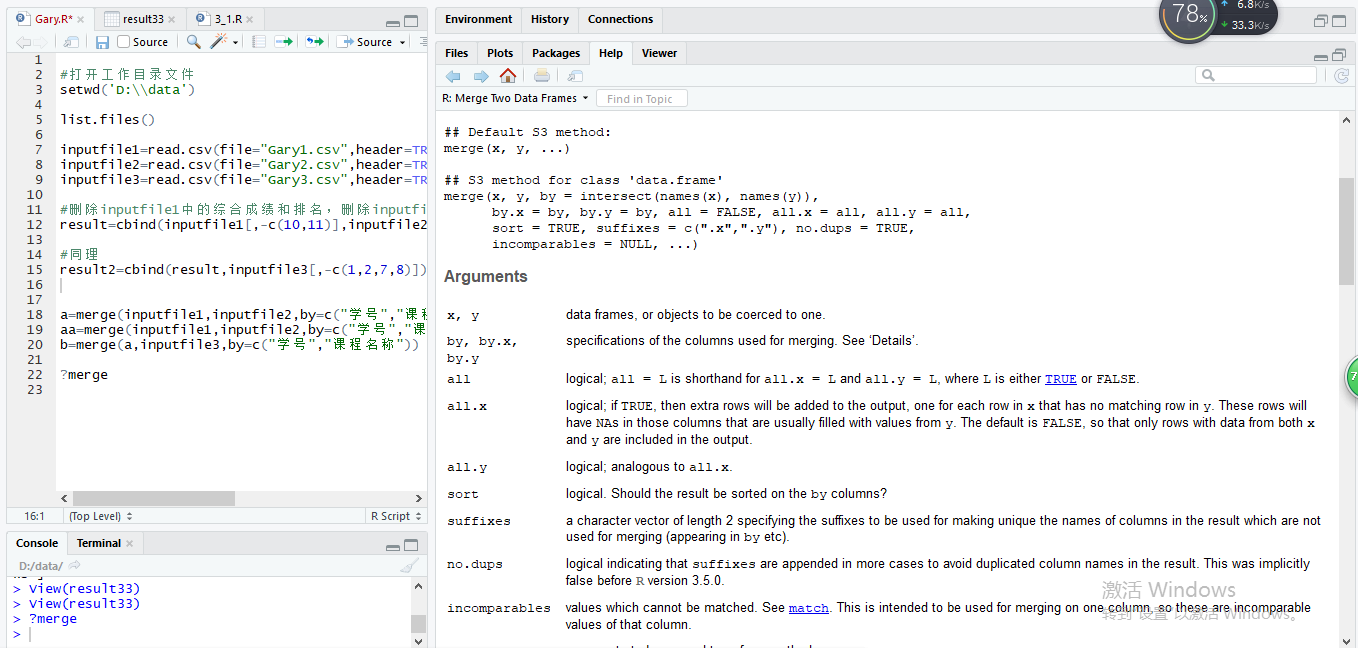
merge()函数是对数据进行交并补运算,三张表进行数据合并时可先合并第一第二张表,再用所合成结果对第三张表进行合成
测试a和aa中值的不同
setwd('D:\\data') list.files() inputfile1=read.csv(file="Gary1.csv",header=TRUE) inputfile2=read.csv(file="Gary2.csv",header=TRUE) inputfile3=read.csv(file="Gary3.csv",header=TRUE) #删除inputfile1中的综合成绩和排名,删除inputfile2中的学号、姓名、综合成绩和排名 result=cbind(inputfile1[,-c(10,11)],inputfile2[,-c(1,2,12,13)]) #数据集列合并 #同理 result2=cbind(result,inputfile3[,-c(1,2,7,8)]) a=merge(inputfile1,inputfile2,by=c("学号","课程名称")) aa=merge(inputfile1,inputfile2,by=c("学号","课程名称","综合排名")) b=merge(a,inputfile3,by=c("学号","课程名称"))
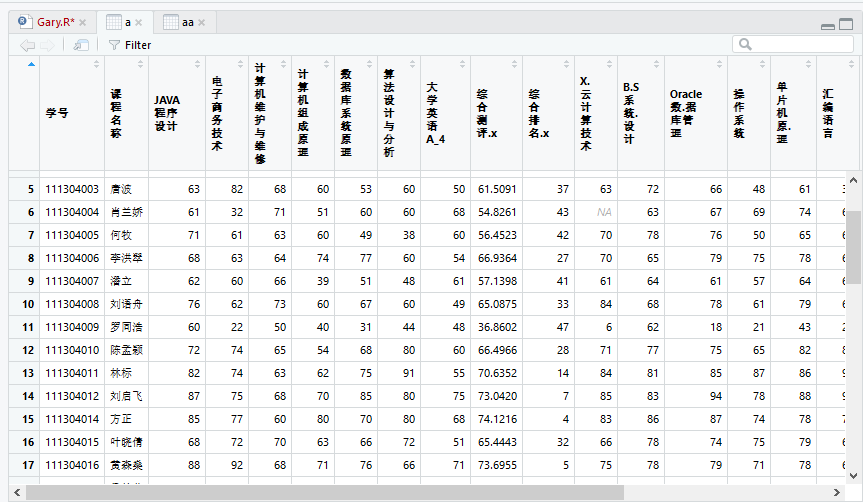
发现aa中存在一个人成绩存在多个综合测评、综合排名的缺陷,把a也添加到by=c("学号","课程名称","综合排名")当中
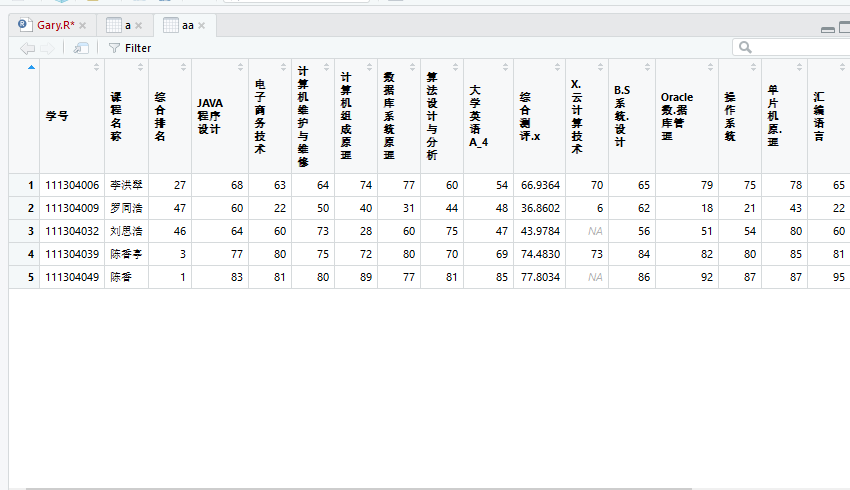
只要第一个学期和第二个学期综合排名不一样时,不显示合并成功的数据!!!
merge()函数对数据的操作还是挺严格的!!!

