R_Studio(学生成绩)对数据缺失值md.pattern()、异常值分析(箱线图)
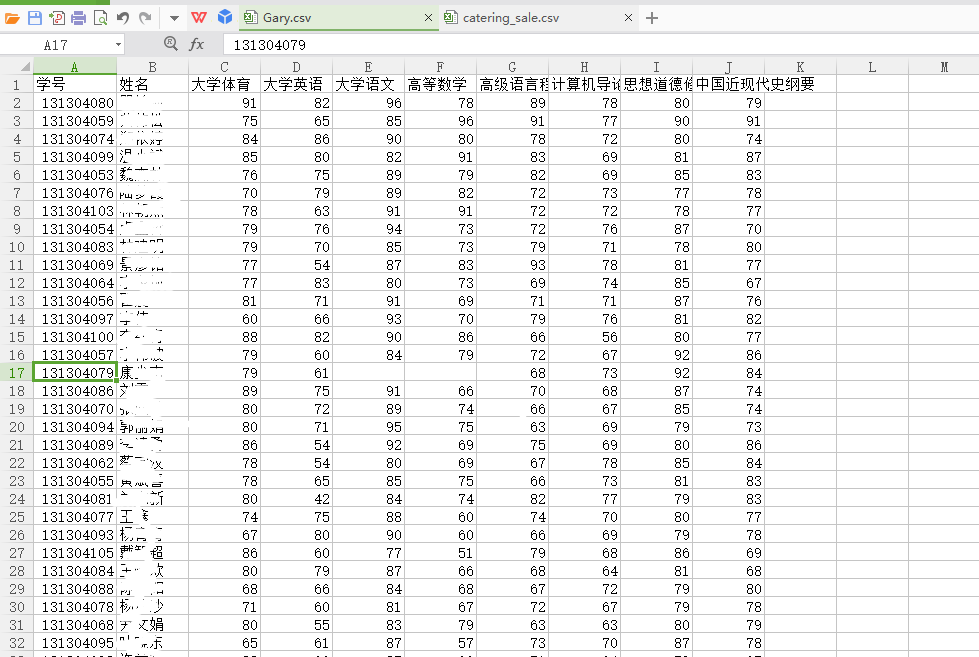
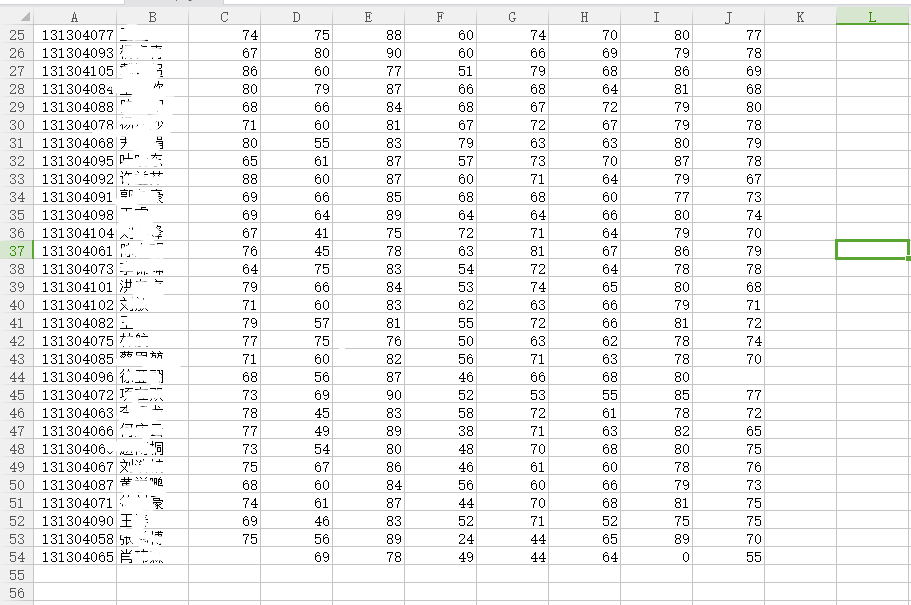
我们发现这张Gary.csv表格存在学生成绩不完全的(五十三名学生,三名学生存在成绩不完整、共四个不完整成绩)
79号大学语文、高等数学
96号中国近代史纲要
65号大学体育


(1)NA表示数据集中的该数据遗失、不存在。在针对具有NA的数据集进行函数操作的时候,该NA不会被直接剔除。如x<-c(1,2,3,NA,4),取mean(x),则结果为NA,如果想去除NA的影响,需要显式告知mean方法,如 mean(x,na.rm=T);NA是没有自己的mode的,在vector中,它会“追随”其他数据的类型,比如刚刚的x,mode(x)为numeric,mode(x[4])亦然。 (2) NULL表示未知的状态。它不会在计算之中,如x<-c(1,2,3,NULL,4),取mean(x),结果为2.5。NULL是不算数的,length(c(NULL))为0,而length(c(NA))为1。可见NA“占着”位置,它存在着,而NULL没有“占着”位置,或者说,“不知道”有没有真正的数据。 在R语言中缺失值通常以NA表示,判断是否缺失值的函数是is.na。 另一个常用到的函数是complete.cases,它对数据框进行分析,判断某一观测样本是否完整。
setwd('D:\\data') #设置工作目录 list.files() #列出工作目录下的文件 dat=read.csv(file="Gary.csv",header=TRUE) #打开Gary.csv文件 is.na(dat) #对数据进行判空,空值返回TRUE complete.cases(dat) #对数据行进行判空,存在空值的行返回TRUE sum(complete.cases(dat)) #统计未缺失数 sum(!complete.cases(dat)) #统计缺失数 mean(!complete.cases(dat)) #统计缺失比例 dat[!complete.cases(dat),] #返回存在空值行数据 library(mice) md.pattern(dat) #针对复杂的数据集值进行处理 #异常值检测箱线图 sp<-boxplot(dat$"大学语文",boxwex=0.7,norch=FALSE) title("大学语文") xi=1.1 sd.s=sd(dat[complete.cases(dat),]$"大学语文") #标准差 mn.s=mean(dat[complete.cases(dat),]$"大学语文") #均值 points(xi,mn.s,col="red",pch=18) arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1) text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)], sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red") plot(saledata[,1],saledata[,2]) lines(saledata[,2])
对成绩数据进行缺失值分析,并表述分析过程
处理方法
对数据进行判空,空值返回TRUE
is.na(dat)
对数据行进行判空,存在空值的行返回TRUE
complete.cases(dat)
统计未缺失数
sum(complete.cases(dat))
统计缺失数
sum(!complete.cases(dat))
统计缺失比例
mean(!complete.cases(dat))
返回存在空值行数据
dat[!complete.cases(dat),]
依赖包mice
md.pattern(dat) #针对复杂的数据集值进行处理
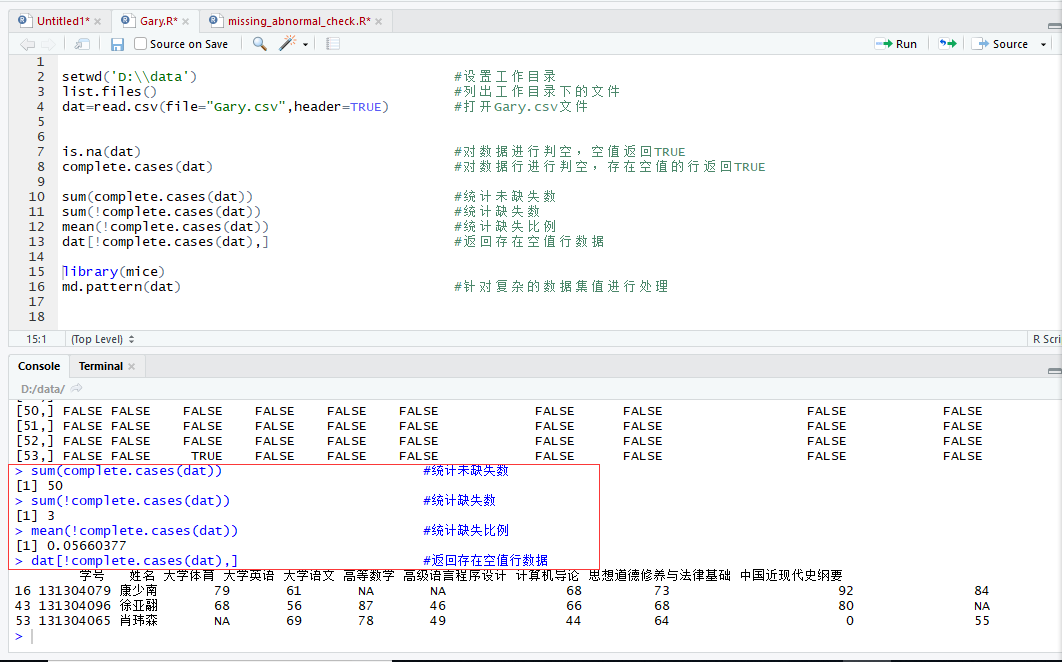
md.pattern()
依赖包mice
生成一个以矩阵或数据框形式展示缺失值模式的表格

0表示变量的列中没有缺失,1则表示有缺失值
第一行第一个数据:完整成绩人数
第二个数据至倒数第二个数据:列出全部学生考试科目
最后一个数据:缺少考试科目数量(争对复杂数据,这里象对数据简单)
第二行至倒数第二行:缺少考试成绩学生信息
第二行表示存在一个学生缺少 中国近代史纲要成绩 缺少成绩科目数量为1
第三行表示存在一个学生缺少 大学语文和高等数学 缺少成绩科目数量为2
第四行表示存在一个学生缺少 大学体育 缺少成绩科目数量为1
最后一行:给出了每个科目的缺失值数目(中国近代史纲要成绩、大学语文和高等数学、大学体育)
最后一个数据:缺少科目学生人数(3人)
对成绩数据进行异常值分析,并表述分析过程
箱线图 传送门
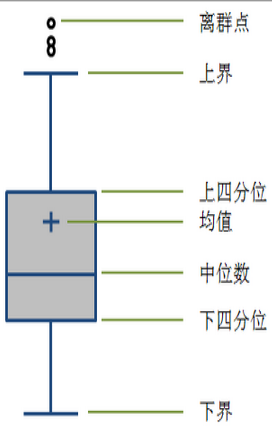
箱线图(Boxplot)也称箱须图(Box-whisker Plot),是利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,它也可以粗略地看出数据是否具有有对称性,分布的分散程度等信息,特别可以用于对几个样本的比较。
#异常值检测箱线图 sp<-boxplot(dat$"大学语文",boxwex=0.7,norch=FALSE) title("大学语文") xi=1.1 sd.s=sd(dat[complete.cases(dat),]$"大学语文") #标准差 mn.s=mean(dat[complete.cases(dat),]$"大学语文") #均值 points(xi,mn.s,col="red",pch=18) arrows(xi, mn.s - sd.s, xi, mn.s + sd.s, code = 3, col = "pink", angle = 75, length = .1) text(rep(c(1.05,1.05,0.95,0.95),length=length(sp$out)),labels=sp$out[order(sp$out)], sp$out[order(sp$out)]+rep(c(150,-150,150,-150),length=length(sp$out)),col="red") plot(saledata[,1],saledata[,2]) lines(saledata[,2])

提示错误:Error in text.default(rep(c(1.05, 1.05, 0.95, 0.95), length = length(sp$out)), : 'labels'长度不能设成零
测试科目 大学语文 时尽然无耻的报错了 Σ(= = !)...
sp$out:结果中会自带异常值,就是下面代码中的sp$out,这个是做箱型图,按照上下边界之外为异常值进行判定的
对数据进行规范化目的:规范化目的是使结构更合理,消除存储异常,使数据冗余尽量小,便于插入,删除,和跟新
测试高等数学
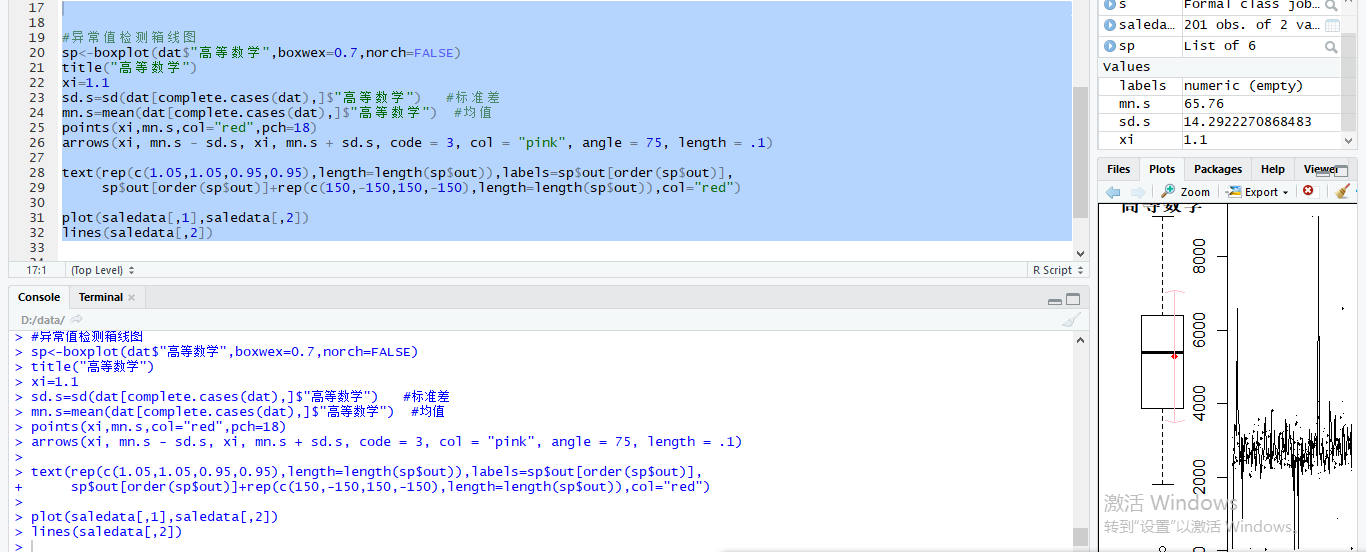
成功画出箱线图!!
测试 高级语言程序设计
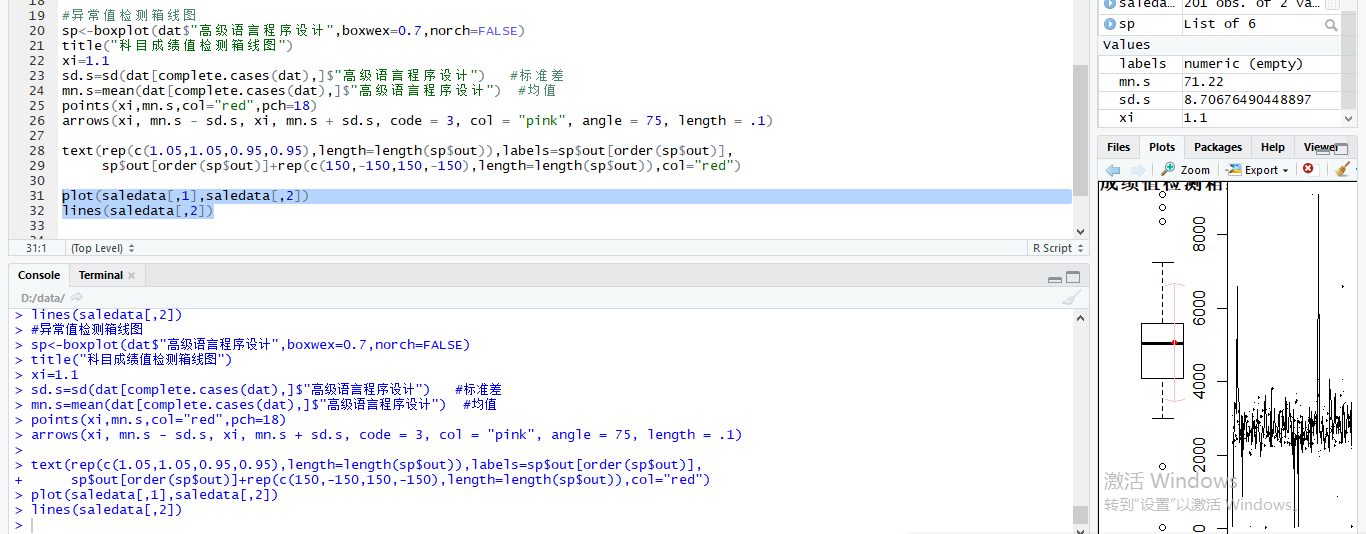
成功画出箱线图!!

