与答辩有关_推荐系统
根据数据源的不同推荐引擎可以分为三类
1、基于人口的统计学推荐(Demographic-based Recommendation)
2、基于内容的推荐(Content-based Recommendation)
3、基于协同过滤的推荐(Collaborative Filtering-based Recommendation)
基于内容的推荐:
根据物品或内容的元数据,发现物品或内容的相关性,然后基于用户以前的喜好记录推荐给用户相似的物品,如图所示:
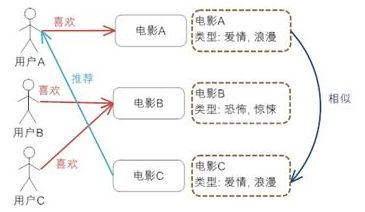
上图给出了基于内容推荐的一个典型的例子,电影推荐系统,首先我们需要对电影的元数据有一个建模,这里只简单的描述了一下电影的类型;然后通过电影的元数据发现电影间的相似度,因为类型都是“爱情,浪漫”电影 A 和 C 被认为是相似的电影(当然,只根据类型是不够的,要得到更好的推荐,我们还可以考虑电影的导演,演员等等);最后实现推荐,对于用户 A,他喜欢看电影 A,那么系统就可以给他推荐类似的电影 C。
而基于协同过滤推荐又分为以下三类:
(1)基于用户的协同过滤推荐(User-based Collaborative Filtering Recommendation)
基于用户的协同过滤推荐算法先使用统计技术寻找与目标用户有相同喜好的邻居,然后根据目标用户的邻居的喜好产生向目标用户的推荐。基本原理就是利用用户访问行为的相似性来互相推荐用户可能感兴趣的资源,如图所示:

上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A、物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A 、物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
(2)基于项目的协同过滤推荐(Item-based Collaborative Filtering Recommendation)
根据所有用户对物品或者信息的评价,发现物品和物品之间的相似度,然后根据用户的历史偏好信息将类似的物品推荐给该用户,如图所示:
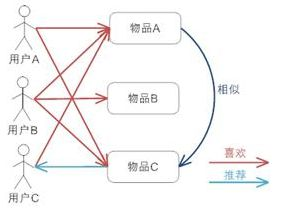
上图表明基于项目的协同过滤推荐的基本原理,用户A喜欢物品A和物品C,用户B喜欢物品A、物品B和物品C,用户C喜欢物品A,从这些用户的历史喜好中可以认为物品A与物品C比较类似,喜欢物品A的都喜欢物品C,基于这个判断用户C可能也喜欢物品C,所以推荐系统将物品C推荐给用户C。
(3)基于模型的协同过滤推荐(Model-based Collaborative Filtering Recommendation)
基模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
综上所述:
基于内容的推荐只考虑了对象的本身性质,将对象按标签形成集合,如果你消费集合中的一个则向你推荐集合中的其他对象;
基于协同过滤的推荐算法充分利用集体智慧,即在大量的人群的行为和数据中收集答案,以帮助我们对整个人群得到统计意义上的结论,推荐的个性化程度高,基于以下两个出发点:(1)兴趣相近的用户可能会对同样的东西感兴趣;(2)用户可能较偏爱与其已购买的东西相类似的商品。也就是说考虑进了用户的历史习惯,对象客观上不一定相似,但由于人的行为可以认为其主观上是相似的,就可以产生推荐了。
理解朴素贝叶斯分类的拉普拉斯平滑 传送门
背景:为什么要做平滑处理?
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
拉普拉斯的理论支撑
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。
假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
应用举例
假设在文本分类中,有3个类,C1、C2、C3,在指定的训练样本中,某个词语K1,在各个类中观测计数分别为0,990,10,K1的概率为0,0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
1/1003 = 0.001,991/1003=0.988,11/1003=0.011
在实际的使用中也经常使用加 lambda(1≥lambda≥0)来代替简单加1。如果对N个计数都加上lambda,这时分母也要记得加上N*lambda。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架